


一大波"Master"正在靠近 盘点各国围棋AI发展
来源:腾讯体育 2017-01-09
其实除了AlphaGo,近几年还有一些很优秀的人工智能围棋程序,它们也经常和人类棋手过招,各有胜负。在 DeepMind 的 AlphaGo 异军突起之前,人工围棋软件的佼佼者们,基本被法国和日本等国占据。

阿尔法狗
一个不透露姓名的神秘 Master,突然出现横扫人类围棋高手,豪取60连胜。一份不完全的手下败将名单 : 古力,柯洁,陈耀烨,范廷钰,常昊,时越,芈昱廷,唐韦星,江维杰,柁嘉熹,周睿羊,朴廷桓,元晟溱,姜东润,金志锡,朴永训,井山裕太……
我猜 DeepMind 团队肯定有成员看过中国武侠小说,一名神秘杀手于月黑风高间杀遍江湖,武林腥风血雨,尊严尽丧。正在各种传言盛嚣尘上之时,杀手现身。绝妙的营销。一个技术顶尖还懂搞噱头的团队,就像你身边某个智商情商双爆表,多金,长的还帅的同事,你恨不恨!
其实除了AlphaGo,近几年还有一些很优秀的人工智能围棋程序,它们也经常和人类棋手过招,各有胜负,只是宣传力度远不如Google。在 DeepMind 的 AlphaGo 异军突起之前,人工围棋软件的佼佼者们,基本被法国和日本等国占据。它们有共同的基本思路,也有各自独特的亮点。其中 Facebook 的 darkforest 提供详细的论文和代码,别的电脑围棋程序则比较神秘。
Facebook 的黑暗森林 (Darkforest)
黑暗森林是 Facebook AI Research 的两位华人研究者共同完成的人工智能围棋程序,命名来自刘慈欣的《三体II:黑暗森林》。田渊栋博士自己在知乎上谦虚的说 (原话),要是 DeepMind 决定在2015年10月份战胜樊麾后马上公开,或者他自己再拖一会儿,决定不投ICLR 而等到2016年的 ICML,那就被灭得连渣都不剩了。如果把科研者的虚怀若谷先放一边的话,人工智能的日新月异也可见一斑。
和 AlphaGo 一样,黑暗森林也是基于深度神经网络的模型 (12层),所以也和AlphaGo 具有相似的优势和缺陷。优势就不再赘述了,缺陷主要存在于对局部策略的选择上。为了弥补这一缺陷,黑暗森林也选择了蒙特卡洛树搜索作为对深层网络的补充。
黑暗森林经历了三个版本的演进。第一代 darkforest 体现了相比传统蒙克卡洛搜索的优势,第二代 darkforest2 达到了稳定的 KGS 3d 的水平,之后,在参考了 alphaGo 的算法之后,作者又在 darkforest2 的基础上加入了蒙特卡洛算法,开发出第三代darkfmcts3,性能得到了进一步提升,差不多达到 KGS 5d 的水平。其实相比 DeepMind 人数众多的团队,Darkforest 的开发团队只有两人,能取得这样的性能已相当不容易。
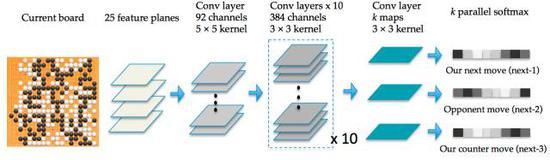
相比 AlphaGo 的策略网络每次只预测下一步走棋,Darkforest 可以预测接下去 k 步棋 (predict long-term moves),包括自己的和对手的棋,这是它独特而强大的地方。个人猜测,当时AlphaGo和李世石下棋的时候,有时会走出一些无用的“电脑手”,一方面是 DCNN 的固有弊端 (Darkforest的论文中也提到类似的问题),另一方面也可能就是因为缺乏长远规划。另一个独特的地方是,Darkforest 的结构采用了多个 softmax 输出,目的是训练时可以增强监督。为了提高收敛速度,Darkforest 还使用了最新的深度残差网络 ResNet。
Darkforest 比 AlphaGo 欠缺的是预测大局的估值网络,这部分是AlphaGo 的独创,个人猜测也是它拥有良好大局观的原因之一。
日本的 Zen
Zen 是目前最著名的围棋程序之一, 2009年发布了第一个版本,最新版本发布于2016年6月。和黑暗森林与 AlphaGo 的团队开发不同,Zen 是日本程序员Yoji Ojima单独开发的围棋程序,硬件部分则由 Kato Hideki 实现。Zen 以劣势的硬件设备 (单机Mac Pro8cores, 当然最新也有mini cluster 或 GPU 版本),连续多年在各种围棋人工智能比赛中夺得冠军。Zen 19K2 也是第一个达到 9D 水准的机器。
法国的 CrazyStone
CrazyStone 由法国计算机科学家 Rémi Coulom 单独开发,采用的也是蒙特卡洛搜索方法,在 Grid‘5000 大规模计算平台上运行。CrazyStone 2013年被让4子击败石田芳夫,2014年被让4子击败依田纪基。图为 Rémi Coulom 和依田纪基正在对决。
2016年5月,CrazyStone 的最新版本加入了深度学习模块,使性能大幅提高,达到 KGS 7d 水准,对战没有深度学习的CrazyStone 2013版本的胜率达到 90%UnbalanceCorporation 还推出了商业版本, 花80美元你就可以拥有一个职业棋手水准的专职陪练!

法国和台湾合作的 MoGo
MoGo 是一款由法国INRIA (法国国家信息与自动化研究所) 和一个台湾的团队共同开发的围棋软件。2009年于台湾,MoGo在被让7子的条件下在19*19全尺寸棋盘上击败了周俊勋九段。 MoGo采用的技术主要有:蒙特卡洛方法,基于Armed Bandits 的树搜索算法 (在当时是革命性的),以及高性能计算集群 (和Crazy Stone一样在Grid‘5000大规模计算平台上运行)。最近 MoGo 貌似没有更新一步的动作。
韩国的DolBaram
作为在围棋领域和智能科技领域均有相当积累的国家,韩国的一家规模并不大的公司 NuriGrim 决定向日本和法国挑战,开发出了 DolBaram。在2016年的 UEC Cup 上,DolBaram 取得了第二名的战绩。在流传出的有限的信息中,可以知道 DolBaram 和 AlphaGo 一样,也采用了深度学习方法。
可以看出,AlphaGo 的成功对人工围棋软件这个行业的影响是很明显的,深度学习和蒙特卡洛结合的方法成为了主流。而围棋之后,类似的方法在别的需要复杂决策的领域的应用,比如医疗,政府决策,智慧城市等,才是更令人激动的。正是人类智慧才创造了人工智能,你大爷终究是你大爷。
补充: 一些关于AlphaGo的陈词滥调
如果读到这里读者还没有累,或是对介绍 AlphaGo 的陈词滥调还没有厌倦,笔者愿意和大家再回顾一下 AlphaGo 的原理,温故而知新嘛
由于巨大的搜索空间 (穷举搜索是不可能的) 和分析棋局自身的复杂性,围棋一向被视为是对于人工智能最具挑战性的经典游戏之一。通常情况下,我们可以设法把实际搜索空间缩小。1) 减小深度:把状态s以下的子树用一个预测状态s的输出的近似函数代替。这种方法已经在国际象棋和跳棋上取得成功,超过了人类的表现,但是因为围棋的复杂度,被认为行不通。2) 减小广度:对政策p采样,政策指的是在某一状态s下的所有走法的概率分布。比如Monte-Carlo rollouts,随机选择一些采样点,直接不分支搜到树的最顶部,然后对这些采样取均值。这种方法可以取得一个较有效的对棋局的判断,被证明可以战胜初级围棋手。
AlphaGo 采取了一种新颖的方法,主要由三部分组成:策略网络,负责预测下一步的棋的概率;估值网络,负责评估当前局面,预测获胜方;蒙塔卡洛树搜索,作用是把系统连为一体。这三个部分并非缺一不可,但是合作在一起,能取得最好的效果。AlphaGo取得了对其他围棋程序99.8%的胜率,在击败李世石的世纪大战之前,AlphaGo 曾5比0横扫欧洲围棋冠军。这是计算机首次在全尺寸棋盘围棋比赛中击败人类职业棋手,这样的成就比人们之前预测的至少提前了十年。
1 策略网络
训练策略网络是 AlphaGo 整个训练体系的第一步。围棋棋盘有19*19个棋格,可以看作是一幅19*19像素的图像,每个像素可以有三个值:黑、白、空。每一个特定时刻的棋局,其实就是一幅19*19的图,作为深层网络的输入。2016年1月发布在自然杂志上的AlphaGo的版本中,策略网络包含了13层神经元,训练数据是从 KGS Go 服务器上取得的3000万个人类棋手的真实棋局,和该棋局对应的下一步走法。
经过多个卷积层和非线性激活函数,策略网络在输出层预测每一个合法落子的概率。机器预测的下一步和人类棋手的下一步会有偏差,网络就以经典的梯度下降算法调整每个连接的权重,纠正偏差。AlphaGo预测人类棋手下一步的准确率达到了57%。值得注意是,AlphaGo还具备一个快速走子策略。完整的策略网络虽然能提供很高的正确率,但是速度较慢 (预测每一步需要 3 ms ),快速走子可以把速度提高1500倍,达到 2 微秒/步,代价是牺牲一定的准确度。
如果说深层卷积网络让 AlphaGo 具备了模仿人类棋手走下一步棋的能力,那么接下来的强化学习 ( reinforcement learning ) 进一步优化了预测结果。强化学习,其实就是让机器不再模仿人类,而是自己跟自己下棋。此时的机器一分为二,一方是当前的状态,另一方是随机选取的之前某一步迭代的状态。随机选取对手是为了要避免过拟合。有趣的是,如果把只会模仿人类的机器和经过强化学习优化过的机器一对一较量,后者取得了80%的胜率。
2 估值网络
估值网络的目的是评估当前局面,预测最后的胜者。估值网络是AlphaGo相比别的人工智能围棋算法的新颖之处。预测局面是围棋的难点之一,就算是顶尖棋手,在预测的时候也经常出现偏差。
训练估值网络有一个小窍门。如果把同一盘棋的每一步局面都当作输入训练的话,因为每两个相邻的棋局都只差一颗棋子,相关性很高,所以很容易造成过拟合的问题。作者就让机器自己生成3000万个不同的棋局,每个棋局都属于一盘不同的棋。训练后的估值网络比采用快速蒙特卡洛推演( Monte-Carlo rollouts with fast policy) 要准确,同时可以达到一般蒙特卡洛推演的准确度,但是要快15000倍。
AlphaGo完全没有做任何局部分析,纯粹用暴力训练出一个相当不错的估值网络,实际上证明了深度卷积神经网络的对问题的分解能力。
3 蒙特卡洛树搜索
AlphaGo通过蒙特卡洛树搜索把策略网络和估值网络结合了起来。目前主要有两种随机算法,蒙特卡洛算法和拉斯维加斯算法。简单的说,蒙特卡洛算法是采样越多,越近似最优解,但找到的不一定就是最优解。相反,拉斯维加斯算法是采样越多,越有可能找到最优解,也就是说找到了就是最优解,但是不保证能找到。显然,对于围棋对弈,要求在有限的采样内,必须给出一个解,不要求是最优解,但是要尽量接近。这种情况,蒙特卡洛算法是很合适的,也是各个围棋软件很常用的一个方法。
如何高效的用蒙特卡洛树搜索把策略和估值网络结合,对实际的工程水平是有很高要求的。AlphaGo选择在CPU上运行异步多线程搜索,在GPU上平行计算策略网络和估值网络。当时和李世石世纪大战的AlphaGo用了40个搜索线程,48个CPU和8个GPU。还有一个更强大的分布式版本,拥有1202个CPU和176个GPU。
-

-
一大波"Master"正在靠近 盘点各国围棋AI发展
-

























