

今天的强化学习技术需要上亿次交互、上亿次试错,最后才能找到对的方式。真实世界试错代价太大怎么办?我们尝试从真实世界的数据里构建一个虚拟的世界,在这个虚拟的世界做出各种各样的尝试。
当强化学习走出打游戏、下围棋的游戏环境后,在更真实的应用场景,能帮我们提高生产力,让效率更高、成本更省,更方便地做出复杂的决策。
2020年10月25日,“科普中国-我是科学家”第28期“AI:人工智能,或者爱”演讲现场,南京大学人工智能学院教授俞扬,带来演讲《当AI走出游戏》。
俞扬演讲视频:
以下为俞扬演讲实录:
2020.10.25 合肥
大家好,我是俞扬,来自南京大学人工智能学院。
提起人工智能,大家经常会问: 智能到底是什么?
 来看一个例子:一只狗,它的智能体现在什么地方?体现在这只狗能学会听懂我们说话。
来看一个例子:一只狗,它的智能体现在什么地方?体现在这只狗能学会听懂我们说话。
这只狗不是天生就懂人类的语言,但是我们可以训练它。在手上拿一个吃的,然后给这只狗下达指令——
坐下。
当然它听不懂,但是它能闻得到我手上食物的味道,能听得见我说话。这时我拿着吃的,让它坐下,它如果不坐,这个吃的就攥在我手里面,不会给它吃。如果它突然坐下了或者趴下了,和我的指令一样,就把吃的给它。
下一次,如果它不是这个动作,它就拿不到吃的;一旦趴下了就能拿到吃的。这个过程反复十几次,大概需要半个小时,就能训练出听得懂指令的狗。这就是动物、生物的智能。
但今天很多人工智能的应用,包括人脸识别、指纹识别、语音识别,这些人工智能技术的核心其实不是生物智能,而是 “监督学习”技术 。
“监督”就表明有一个老师的存在,这个老师会告诉机器:这张图是我的照片;另外一张图不是我的照片。收集了很多数据以后,机器就能识别出谁是我,谁不是我,这就是人脸识别。
 这个技术和前面提到的狗的学习过程不一样。狗是在完全没有老师的情况下,自己学会听懂人类说话,没有人告诉它,坐下的时候要摆什么动作。它是自己慢慢去摸索,发现坐下以后才能拿到吃的。
这个技术和前面提到的狗的学习过程不一样。狗是在完全没有老师的情况下,自己学会听懂人类说话,没有人告诉它,坐下的时候要摆什么动作。它是自己慢慢去摸索,发现坐下以后才能拿到吃的。
所以能不能实现让机器像动物一样学习?这就是智能计算机。
它能做的事和动物一样:在一个环境里,对环境能做观测,去看、去听、去闻周围有什么。另外还可以做出许多行动,比如这只狗在环境里摆出不同的动作,有时候摆对了,就拿到一个吃的,这个叫做奖励。
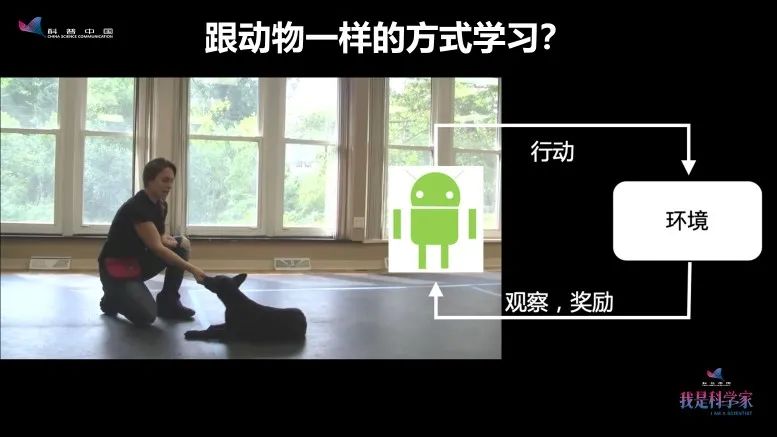 如果机器能像狗一样智能,它就能在环境中自己学习,不需要有一个老师专门一个样本、一个样本地来教。这件事情,实际上是可以实现的,它有另外一个名字叫做—— 强化学习 。
如果机器能像狗一样智能,它就能在环境中自己学习,不需要有一个老师专门一个样本、一个样本地来教。这件事情,实际上是可以实现的,它有另外一个名字叫做—— 强化学习 。
强化学习在最近人工智能突出的进展上经常被报道。比如,人工智能在围棋领域已经能下过所有的围棋高手;在一些很复杂的游戏中,也能打败大部分的人类的玩家,这些都是靠机器自己摸索。
它能帮我们做什么事情呢?
在围棋方面,它可以超越人类的能力,那么它可不可以帮我们治理今天越来越堵的交通?可不可以帮我们更好地管理仓库?可不可以帮我们来组织生产?甚至,可不可以帮我们、替代我们做一些繁琐的工作?
 如果可以做这些事情,那么这个技术就能带来生产力的提升。我们特别渴望这样的技术能走出打游戏、下围棋的游戏环境,去更真实的应用场景,帮我们提高生产力,让日子过得更好。
如果可以做这些事情,那么这个技术就能带来生产力的提升。我们特别渴望这样的技术能走出打游戏、下围棋的游戏环境,去更真实的应用场景,帮我们提高生产力,让日子过得更好。
但是很可惜,这些应用目前为止还没有做得很好。
哪个地方做得不好?效率不够好。
可以和动物来对比一下,像训练狗,可能就需要十几次,半个小时它就学会了,然后它就有吃的了。但是如果要下围棋,在训练过程中需要上亿次试错——有大量下出来的围棋是错的,都输给了对手,可能要到最后才发现有一条路可以走通,能下赢。直到这个时候,我们才学会怎么能下出最好的围棋。
 也就是说,今天的技术在游戏环境下,需要上亿次交互、上亿次试错,最后才能找到对的方式。这和生物智能的效率不在同一个水平上,如果这只狗需要上亿次试错才能拿到吃的,它可能早就已经饿死了。如果计算机需要做出上亿次错误的红绿灯安排,才能指挥好交通,那可能我们根本出不了门。
也就是说,今天的技术在游戏环境下,需要上亿次交互、上亿次试错,最后才能找到对的方式。这和生物智能的效率不在同一个水平上,如果这只狗需要上亿次试错才能拿到吃的,它可能早就已经饿死了。如果计算机需要做出上亿次错误的红绿灯安排,才能指挥好交通,那可能我们根本出不了门。
所以这个技术到今天还没有得到广泛地使用。
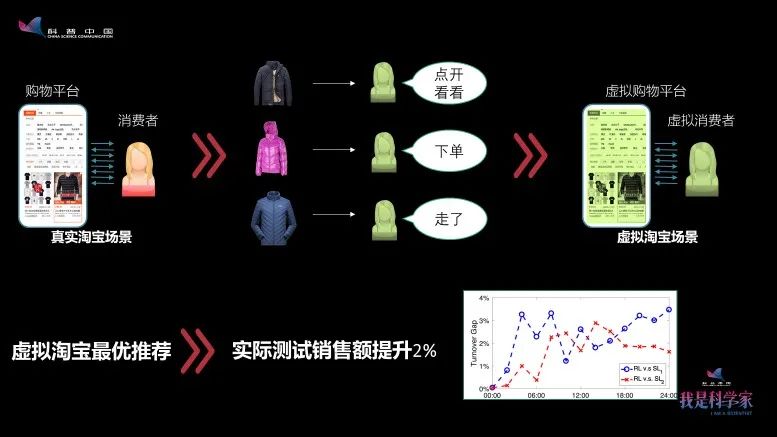
但实际上它的效用特别可观。举一个例子,我们在2016年和淘宝的搜索团队合作,希望能更好地帮消费者找到想要的商品。
以往的商品推荐是通过消费者的历史数据,预测未来会买什么样的东西。比如说,今天我家搬家了,买了一个冰箱,商品推荐就会按照我的历史数据,再给我推荐几台冰箱,那么这对于我来说就是一个错误的推荐。
还有一个问题,浏览商品时,消费者能看100个商品就很多了,但是实际上整个淘宝网上有超过10亿件商品。消费者不可能看到所有商品,也没有办法能找到最想买的东西。
 那么怎么来解决这些问题?
那么怎么来解决这些问题?
2016年我们做了一个尝试——在真实的用户购物环境中,用强化学习去寻找合适的推荐商品。但我们发现,因为强化学习需要试错,所以在一开始的时候,可能有一些错误推荐。
这个时候消费者体验会非常不好,可能立马就关掉淘宝网页了,所以我们觉得这样做代价太大。
那怎么办?
我们从科幻电影里得到了一些启发。比如《黑客帝国》这部电影,构想人类生活在一个虚拟世界中。这个虚拟的世界跟真的一样,但是由于它是虚拟的,很多真实世界不会发生的事情,在虚拟世界里都可以模拟。
 所以我们想,如果不能在真实的世界中随意尝试,那么能不能从真实世界的数据里构建一个虚拟的世界,在这个虚拟的世界做出各种各样的尝试?
所以我们想,如果不能在真实的世界中随意尝试,那么能不能从真实世界的数据里构建一个虚拟的世界,在这个虚拟的世界做出各种各样的尝试?
回到淘宝上面,我们想做的就是根据一个真实用户的历史购物数据,还原了一个 虚拟的用户 。这个虚拟的用户和真实的用户行为表现可能差不多。
 我们给他推荐一件商品,他可能就点开看一看,另外一件商品可能会买单,还有的商品可能看都不会看。在虚拟场景下,不会有任何真实的开销。这个虚拟用户可以代替真实用户浏览上亿个商品,告诉我们什么样的商品最符合用户的需求。
我们给他推荐一件商品,他可能就点开看一看,另外一件商品可能会买单,还有的商品可能看都不会看。在虚拟场景下,不会有任何真实的开销。这个虚拟用户可以代替真实用户浏览上亿个商品,告诉我们什么样的商品最符合用户的需求。
这样我们就构建了 虚拟淘宝的环境 。在这样的环境下,有大量的虚拟用户在买东西,为强化学习提供数据。而根据虚拟用户数据提出的算法,在真实的场景中,也能做出更好的推荐。
 买完东西以后,还有一个流程——买的东西怎么到消费者手里?首先,这个订单会发到一个仓库,工作人员会把很多袋子挂到一个车上,每一个袋子就是一个订单,工人去捡货。
买完东西以后,还有一个流程——买的东西怎么到消费者手里?首先,这个订单会发到一个仓库,工作人员会把很多袋子挂到一个车上,每一个袋子就是一个订单,工人去捡货。
这里又有一个问题了:把什么样的订单拿到一起去捡,工人捡货的效率最高。以往普遍认为工人的效率和他走过的路径有关系,但是实际上在真实捡货过程中,除了路径以外,还有商品的大小、重量、放的高度,很多东西都会影响到工人捡货的效率。
怎么样提高工人的分拣效率?一样的,构建一个虚拟工人,尝试如何给虚拟的工人安排订单,能让他的效率最高。后来我们把虚拟环境中得到的最优派单方式,放到真实环境中去用,获得了10%以上的效率提升。
 当商品全部打包好后,就要通过物流来送到消费者的手上,这里又碰到一个问题:怎么样给司机安排最优行走路线?
当商品全部打包好后,就要通过物流来送到消费者的手上,这里又碰到一个问题:怎么样给司机安排最优行走路线?
还是用同样的方法,从数据里还原出虚拟的司机,在虚拟的司机身上实验,如何安排路线最好。目前,三个城市已经完成了初步的实验,获得了11%以上的效率提升,同时也提升了司机的收入。
 从上面很初步的例子,已经可以看到,当强化学习走出游戏环境,能解决很多应用问题,让效率更高、成本更省,更方便地做出复杂的决策。
从上面很初步的例子,已经可以看到,当强化学习走出游戏环境,能解决很多应用问题,让效率更高、成本更省,更方便地做出复杂的决策。
所以这样的技术,当它能完全落地、全面铺开的时候,将给生活带来巨大的改变,是一个很有能量的技术。但是越有能量的技术,使用的时候可能就要越小心,因为它被滥用后带来负面效果的可能性越大。如果强化学习被用在大数据杀熟上,可能比现有技术杀得更狠。
 2005年一部电影中,曾展示过无人驾驶的战斗机自己去作战,虽然当时是电影里的虚构场景,但是前段时间在美国的国防部比赛里,已经在模拟场景中实现了无人驾驶战斗机。当这个技术在敌人手上时,对我们就构成了威胁。
2005年一部电影中,曾展示过无人驾驶的战斗机自己去作战,虽然当时是电影里的虚构场景,但是前段时间在美国的国防部比赛里,已经在模拟场景中实现了无人驾驶战斗机。当这个技术在敌人手上时,对我们就构成了威胁。
那怎么样能防止技术不当使用带来的负面后果,以及防止敌对实力在这项技术上形成威胁?
 我们要在这个科研方向加大投入,让更好、更先进的技术掌握在自己手上。我们希望未来能像这个电影里看到的一样,这个机器人为我们服务,在为我们产生正面的价值。
我们要在这个科研方向加大投入,让更好、更先进的技术掌握在自己手上。我们希望未来能像这个电影里看到的一样,这个机器人为我们服务,在为我们产生正面的价值。
谢谢大家。
 演讲嘉宾俞扬:《当AI走出游戏》 | 摄影:VPhoto
演讲嘉宾俞扬:《当AI走出游戏》 | 摄影:VPhoto
作者:俞扬
监制:吴欧
策划:吴欧 麦芽杨
编辑:李霄 范可鑫
排版:夏晓茜
校对:范可鑫
在“我是科学家iScientist”后台回复“演讲”,或者点击菜单栏“演讲”,即可看到更多科学家演讲。
 欢迎个人转发到朋友圈
欢迎个人转发到朋友圈
 本文版权属于“我是科学家”,未经授权不得转载。如需转载请联系iscientist@guokr.com
本文版权属于“我是科学家”,未经授权不得转载。如需转载请联系iscientist@guokr.com
欢迎填写调查问卷,支持我们↓↓↓
 “科普中国”公众满意度调查问卷 ▲
“科普中国”公众满意度调查问卷 ▲
【扩展阅读】 被人口普查漏掉的人,AI在卫星地图上能看见
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国