

当代最非凡的算法莫过于每天帮助数百万人浏览互联网的搜索算法。如果我被扔在荒岛上,只允许随身携带一个算法,我可能会选择谷歌的搜索引擎。(并不是说它会有多大的用处,因为我不太可能连上互联网)。
20世纪90年代早期,一个专门收录所有互联网网址的目录直到1994年才收录了大约3000个网站。 当时的互联网很小,小到可以让你轻而易举地浏览一下就能找到想找的东西 。从那时起,互联网就在不断发展。当我开始写这篇文章时,互联网上已经有1267084131个网站了,还没写几句话的工夫,这个数字就上升到了1267085440 (访问 http://www.internetlivestats.com/ 即可 查看现存网站数量)。
谷歌的搜索引擎是如何从数以几十亿计的网站中准确地找出你想要的信息呢?86岁来自维冈的老奶奶玛丽·阿什伍德(Mary Ashwood)在浏览器的搜索栏里非常有礼貌地使用“请”和“谢谢”来提出她的搜索请求,或许她脑海中想象的画面是, 电脑另一端一群勤劳的实习生正在埋头苦干,处理浩如烟海的请求信息 。她孙子本(Ben)打开笔记本电脑,看到“麻烦你帮我翻译一下这个罗马数字—MCMXCVIII,谢谢你!”的搜索问句后,忍不住在Twitter上向全世界讲述了奶奶的误解。当谷歌工作人员回复他的Twitter消息时,他惊呆了:
敬爱的本的奶奶,愿您一切安好。
在数十亿次的搜索中,是您让我们会心一笑。
嗯,您所需要翻译的罗马数字是1998。
感谢您!
在这一次的机缘巧合下,本的奶奶将谷歌的工作人员推向台前。谷歌的搜索引擎每15秒就要处理数百万次请求,这样的数量任何公司都无法做到人工回复。那么,如果谷歌不是拥有互联网神奇魔法的精灵,它是如何成功地找到你想要的答案呢?
这一切归功于 1 996年拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin)在斯坦福大学的宿舍里发明的强大而精妙的算法 。他们最初想把新算法命名为“ 网络爬虫 ”(Backrub),但最终还是决定叫“ 谷歌”(Google) ,其灵感来自1后面的100个零。他们的目标是找到一种对互联网上所有的页面进行排序的方法,以帮助大家在这个不断增长的海量数据库中进行检索,所以起这个代表巨大数字的名字似乎特别贴切,而且也很酷炫。
这并不意味其他的算法不能做这件事,但是那些算法在概念上非常简单。如果你想搜索更多关于“有礼貌的奶奶和谷歌”的信息,现有的算法会将所有包含这些关键词的页面识别出来,并按顺序排列,搜索词出现频率最高的网站会被放在最顶部。
这种方式虽然有效,却容易被黑客攻击 :任何一个花店老板只要在网页的元数据中数千遍地插入关键词“母亲节鲜花”,那么每个想买花的子女电脑上的搜索结果的最顶端就会出现这个花店的链接。你肯定不希望自己的搜索被精明的人设计或者操纵,那么,如何才能对一个网站的重要性给予公正的评价呢?
如何判断哪些网站该被过滤掉呢?佩奇和布林想出一个聪明的方法: 如果一个网站有很多链接指向它,就暗示着其他网站认为这个网站值得访问 。其原理是通过其他网站的评估去衡量某个网站的重要性,或者说该网站的访问价值。但是,这种方式也有可能被黑客攻击,比如只需伪造出有 1000 个网站的链接指向这个花店就行了,这样也会使其被纳入搜索名录。
为了防止这种情况出现,他们决定 给那些获得广泛好评,深受信赖的网站赋予更高的权重 。
可这仍然会让他们面临一个挑战:如何客观评价一个网站的重要性?
以一个小型网络为例 (如图4-2所示) 。
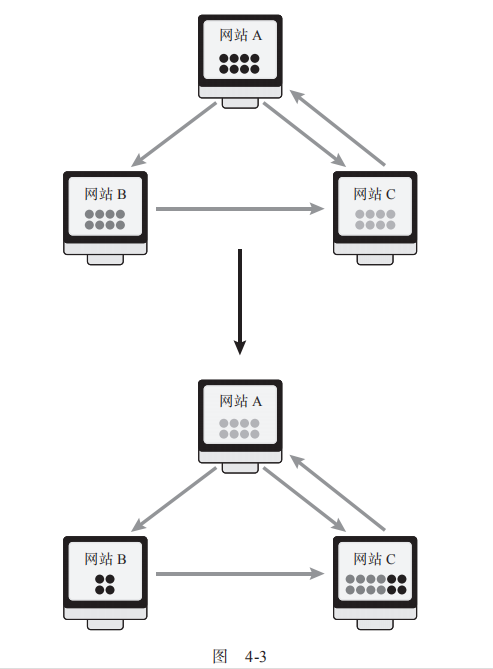
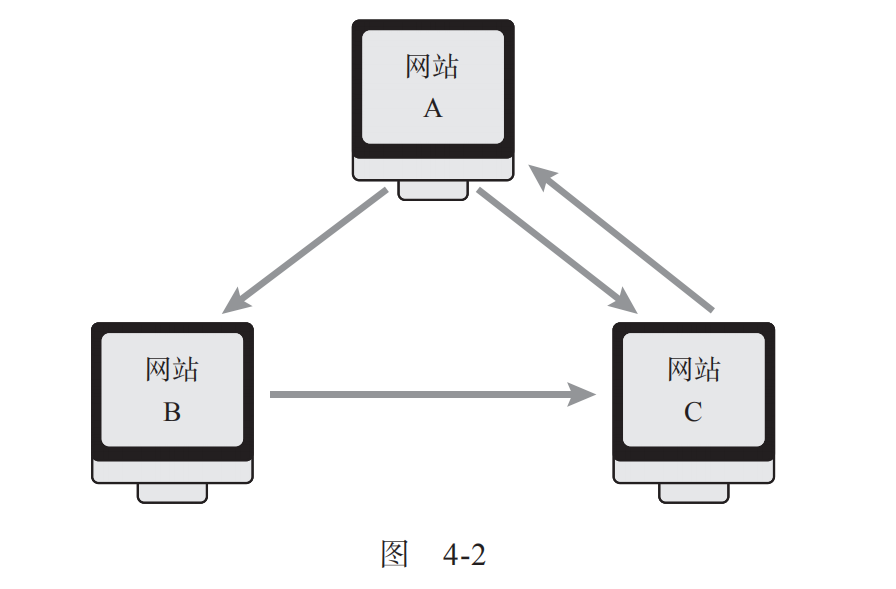 首先, 给每个网站设定相同的权重 。然后,让我们把网站想象成一个桶,给每个桶里放8个球,表示网站的初始权重相同。现在,每个网站必须将球交给它链接的其他网站,如果链接多个网站,那么就将球均分给那些网站 (如图4-3所示) 。由于网站A链接了网站B和网站C,它将为每个网站提供4个球;而网站B只链接了网站C,它就需要将拥有的8个球全部放入网站C的桶中。第1轮分配后,网站C得到的小球数最多。
首先, 给每个网站设定相同的权重 。然后,让我们把网站想象成一个桶,给每个桶里放8个球,表示网站的初始权重相同。现在,每个网站必须将球交给它链接的其他网站,如果链接多个网站,那么就将球均分给那些网站 (如图4-3所示) 。由于网站A链接了网站B和网站C,它将为每个网站提供4个球;而网站B只链接了网站C,它就需要将拥有的8个球全部放入网站C的桶中。第1轮分配后,网站C得到的小球数最多。
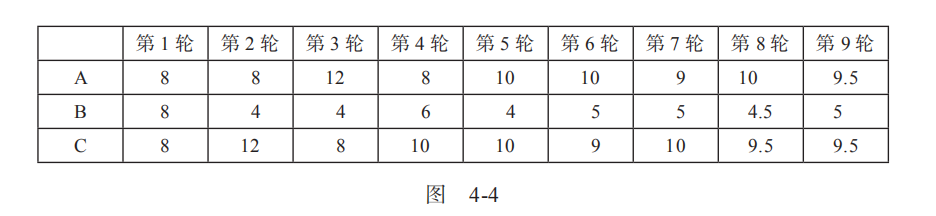
 但是我们需要继续重复这个分配过程,因为现在位于最高排名的网站C链接了网站A,所以又会产生新的分配结果。9轮重复分配过程中各网站小球数量的变化情况如图4-4所示。
但是我们需要继续重复这个分配过程,因为现在位于最高排名的网站C链接了网站A,所以又会产生新的分配结果。9轮重复分配过程中各网站小球数量的变化情况如图4-4所示。
 到这一步,它还算不上是一个特别好的算法,因为 不稳定,并且效率相当低 ,没有达到理想算法的两个关键标准。佩奇和布林的洞见之伟大在于,他们意识到,需要找到一种方法,通过观察网络的连通性来分配球。结果,他们在 线性代数 中找到了一个诀窍,可以一步算出正确的分布情况。
到这一步,它还算不上是一个特别好的算法,因为 不稳定,并且效率相当低 ,没有达到理想算法的两个关键标准。佩奇和布林的洞见之伟大在于,他们意识到,需要找到一种方法,通过观察网络的连通性来分配球。结果,他们在 线性代数 中找到了一个诀窍,可以一步算出正确的分布情况。
这种算法从构建一个矩阵开始,该矩阵描述球在网站间的重新分配方式。矩阵的第1列表示球从网站A到其他网站的分配比例:0.5转到网站B,0.5转到网站C。由此,可以得到球的重分配矩阵:
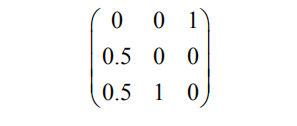 难点是寻找这个矩阵特征值为1的特征向量 ,这是一个与该矩阵相乘不会发生改变的列向量。找到特征向量的方法我们在大学本科时就学过了,因此在这个网络中我们发现,通过重分配矩阵找到的列向量非常稳定:
难点是寻找这个矩阵特征值为1的特征向量 ,这是一个与该矩阵相乘不会发生改变的列向量。找到特征向量的方法我们在大学本科时就学过了,因此在这个网络中我们发现,通过重分配矩阵找到的列向量非常稳定:
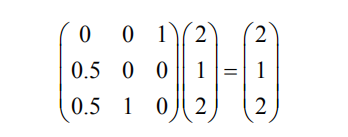 这就表明,如果我们按照2 : 1 : 2的比例给各网站分配球,会看到这个权重比例是稳定的。用之前9轮分配的例子中得到的数据也可以验证这一结论,各网站拥有的球的比例总是约等于2 : 1 : 2。
这就表明,如果我们按照2 : 1 : 2的比例给各网站分配球,会看到这个权重比例是稳定的。用之前9轮分配的例子中得到的数据也可以验证这一结论,各网站拥有的球的比例总是约等于2 : 1 : 2。
矩阵的特征向量是在数学和其他科学领域中非常有效的一种工具,是量子物理中用来计算粒子能级的秘密武器,可以用于研究旋转流体的稳定性(比如旋转的恒星或者病毒的繁殖率),甚至可以用于研究素数在所有数字中是怎样分布的问题。
通过计算网络连通性的特征向量,我们发现网站A和网站C的排名应该是相同的。虽然网站A只连接到一个网站(网站 C),但由于网站C的权值较高,它会赋予网站 A 较高的权值。
这是算法的核心基础,但 需要加入一些额外的细节处理才能使其充分发挥作用 。例如,该算法可能需要考虑一些异常情况:如果存在未链接其他网站的孤立网站,它的球会无法重新分配。
尽管基础引擎是公开的,但算法内部的一些重要参数还是保密的,并且随着时间的推移不断发展变化、更新换代,这些在一定程度上使得算法难以被破解。谷歌算法最吸引人的地方在于它本身的健壮性和防止欺骗的策略— 一个网站很难在自己的网站上做手脚来提高排名,它必须依靠其他网站来提升自己的排名 。
如果你关注一下谷歌搜索,就会发现 排名很靠前的网站主要都是新闻媒体网站和大学官方网站 ,比如牛津大学、哈佛大学的官网。许多外部网站都会链接到大学网站上的研究资料及观点页面,这正是由于这些大学的研究成果受到了世界各地许多人的关注。
当牛津大学网络中的任何一个网站链接到外部网站时,该链接将提升其所链接的外部网站的排名,这意味着牛津大学认可与该网站共享其巨大的声望。
这也就是为什么我经常会被其他人要求,让我把在牛津数学系的网站链接到外部网站。这么做有助于提高外部网站的排名,毕竟能够在谷歌搜索排名登顶是每一个网站的终极“圣杯”。
谷歌的算法再强大,也 不可避免地被那些了解数学原理的人用更加聪明的办法攻击并加以利用 。
在2018年夏天的某段时间里,如果你在谷歌上搜索“白痴”(idiot),首先弹出的便是唐纳德·特朗普(Donald Trump)的照片。
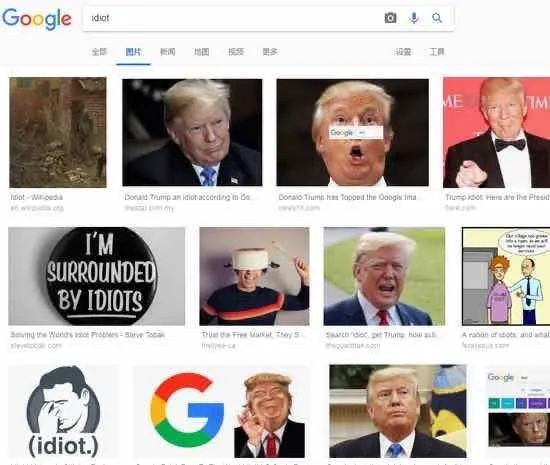 (在谷歌上搜索“idiot”,首先弹出的是Donald Trump的照片)
(在谷歌上搜索“idiot”,首先弹出的是Donald Trump的照片)
一些激进分子知道怎样利用Reddit在互联网的巨大影响力:他们在网上发布一个包含“白痴”这个关键词和特朗普照片的帖子让大家投票,两者的组合很快就登上了谷歌搜索的首位。
但随着时间的推移,这些另类的搜索结果的峰值会通过算法本身而不是人工干预进行降级,并被算法慢慢剔除。谷歌不喜欢扮演“上帝”,但 从长远来看,它相信的是数学的力量 。
互联网就像一头会变身的妖兽,瞬息万变,每一纳秒就会有一个新网站诞生。随着网站的关闭和更新,新的链接关系也在不断地生成、变化,这意味着 网站页面的搜索优先级需要动态调整 。为了让谷歌跟上互联网不断发展的步伐,他们会使用一个有着相当可爱名字的工具,定期在互联网上搜罗网站信息并更新网站链接的统计点击量,这个工具叫作 “谷歌蜘蛛侠”(Google spiders) 。
技术控和体育教练发现,这种评估网络节点的方法也可以应用于其他“类网络”领域,尤其是足球。当评估对手时,评估对手的关键球员非常重要,因为他会控制整个球队的打法或者成为比赛的焦点。如果在比赛初期就能找到这名球员,并对他的发挥进行有效的遏制,那么在战略上就能冻结对手整个球队的战斗力。
来自伦敦的两位数学家哈维尔·洛佩斯·佩纳(Javier López Peña)和雨果·杜塞特(Hugo Touchette)都是狂热的足球迷,他们决定研究一下, 看看谷歌的算法是否有助于分析世界杯参赛球队的情况 。
 (科学家运用算法分析世界杯参赛球队情况 | pixabay)
(科学家运用算法分析世界杯参赛球队情况 | pixabay)
他们是这样考虑的:如果把每位球员看作一个网站,一个球员给另一个球员传球就好比一个网站链接另一个网站,那么比赛中的传球路线就可以被视为一个网络;传球给队友是信任那个球员的标志,因为球员通常会避免传球给一个容易丢球的“笨”队友;一个不会积极跑动、有效控球的球员是很难拿到球的,所以只有有能力控球的人才会有人给他传球。
因此,他们决定使用国际足联在2010年世界杯期间提供的传球数据来分析球员实力排名。当对英格兰队的比赛进行分析时,他们发现史蒂文·杰拉德(Steven Gerrard)和弗兰克·兰帕德(Frank Lampard)两位球员的数据明显高于其他人。这反映出一个情况:足球会频繁传给这两位中场球员,遏制他们在场上的发挥极有可能使英格兰队输球。最终,英格兰队在世界杯中确实没有走太远,复赛就被老对手德国队淘汰了。
以最终胜者西班牙队的数据来说,经过算法统计分析,西班牙队中没有明显的核心球员,这反映了整个球队很好地贯彻了“全攻全守”“快速短传”的战术思想,这最终促成了西班牙队走上冠军领奖台。
与美国许多依靠数据分析发展起来的体育项目不同,足球需要经过一段时间的积累才能利用数学和数据统计挖掘比赛背后隐藏的规律。但是到了2018年俄罗斯世界杯,许多球队都聘请了科学家在幕后提供技术支持—通过分析数据来了解对手的优势和弱点,这其中就包括对每支球队中传球依赖度的分析。
网络分析还应用于文学领域 。安德鲁·贝弗里奇(Andrew Beveridge)和单杰(Jie Shan)用一套名为“网络科学”的方法分析了乔治·雷蒙德·理查德·马丁(George R.R.Martin)的史诗奇幻巨著《冰与火之歌》(Song of Ice and Fire)。了解该故事剧情的人都知道,想要预测哪些角色会在剧本下一卷中出现不太容易,因为马丁先生会为了剧情需要,不惜“写死”哪怕是剧中最好的角色。
贝弗里奇和单杰决定在书中的人物之间建立一个网络。他们选定了剧中107个关键人物作为网络中的节点,然后根据关系重要程度为人物节点之间的连接线赋予权值。但算法如何评估节点间连接的重要性呢?该算法只是简单地计算剧情中两个人物名字在连续的15个单词内出现的次数。这并不是在衡量人物之间的友谊,而是在衡量他们之间的互动或联系频度。
他们选定这个系列的第三卷《冰雨的风暴》(A Storm of Sword)进行分析,因为剧情发展到这里也就基本稳定了。
首先,他们对网络中的节点(或者说角色)进行了排名分析,三个角色很快脱颖而出,他们分别是提利昂(Tyrion)、琼恩·雪诺(Jon Snow)和珊莎·史塔克(Sansa Stark)。
 (提利昂(Tyrion)、珊莎·史塔克(Sansa Stark)的名字出现次数排名靠前 | 《权利的游戏》剧照)
(提利昂(Tyrion)、珊莎·史塔克(Sansa Stark)的名字出现次数排名靠前 | 《权利的游戏》剧照)
读过这本书或看过该系列电视作品的观众都不会对这个发现感到意外,但令人惊奇的是, 一个不理解剧本内容的计算机算法也能分析出跟人相同的结论 。这不是简单地计算某个角色名字出现的次数就能评估的,如果只是简单的这样做,会有其他人物的名字出现在排名中。
事实证明,算法对于这个剧情网络更加微妙的分析揭示出了剧中真正的主角。
随着剧情的发展,第三卷中的一些关键人物都被“写死”了,但这三个角色都在马丁的笔下幸存了下来。这就是一个优秀的算法存在的价值:从足球到《权力的游戏》, 它在多种不同的应用场景中都能发挥作用 。
本文节选自 《天才与算法:人脑与AI的数学思维》 ,这本书是美、英两国双料院士马库斯·杜·索托伊先生巅峰作品。我们即将进入一个由算法主导世界,AI将在绘画、音乐、写作等向人类发起挑战,作者用数学帮我们理解算法及创造力的本质。

 作者:马库斯·杜·索托伊(Marcus du Sautoy)
作者:马库斯·杜·索托伊(Marcus du Sautoy)
编辑:吴雨靖
排版:雷颖

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国