

经典科幻大片里的声纹识别是怎么做到的?录音、变声器真的可以骗过声纹识别系统吗?《一千零一夜》的故事里,阿里巴巴用“芝麻开门”的喊声打开了宝藏洞门,在1000多年后的今天,人们终于实现了用声音做钥匙的梦想。现实中的声纹识别技术究竟是如何炼成的?到底有多厉害?清华大学教授、博士生导师,清华大学语音与语言技术中心(CSLT)主任,清华大学人工智能研究院听觉中心主任,得意音通创始人郑方带来演讲《声纹识别技术,现实世界中的“芝麻开门”》。
郑方演讲视频:

以下为郑方演讲实录:
大家好,我是郑方。
 我们先来看一段视频——
我们先来看一段视频——

这是电影《2012》里面的一个片段,大家可能看过,很有名。主人公用声音做了两件事情:识别身份和命令识别(启动引擎),其实就是“芝麻开门”的一个现实版体现。
为什么可以做到这些?这跟我们的声音有很大的关系。
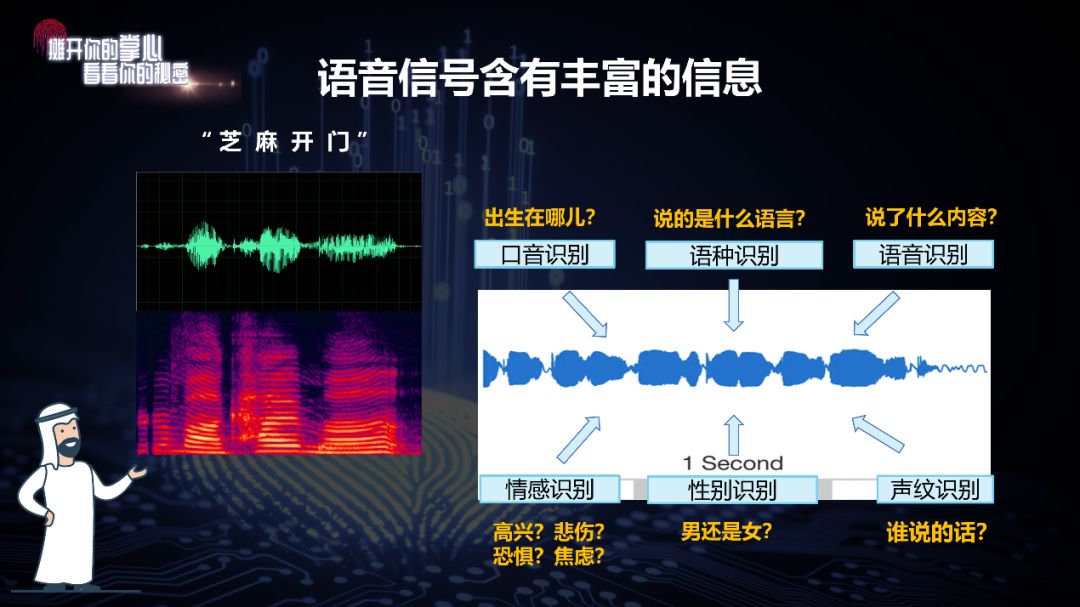 语音信号很简单,是一维的,几乎每个人都会听和说;但 蕴藏其中的信息量非常丰富 ,包括性别、口音、内容、情感等等。其实还有一些别的信息,我几年前曾经想过,能不能实现通过声音看病?结果2017年,以色列的公司就做出来了。
语音信号很简单,是一维的,几乎每个人都会听和说;但 蕴藏其中的信息量非常丰富 ,包括性别、口音、内容、情感等等。其实还有一些别的信息,我几年前曾经想过,能不能实现通过声音看病?结果2017年,以色列的公司就做出来了。
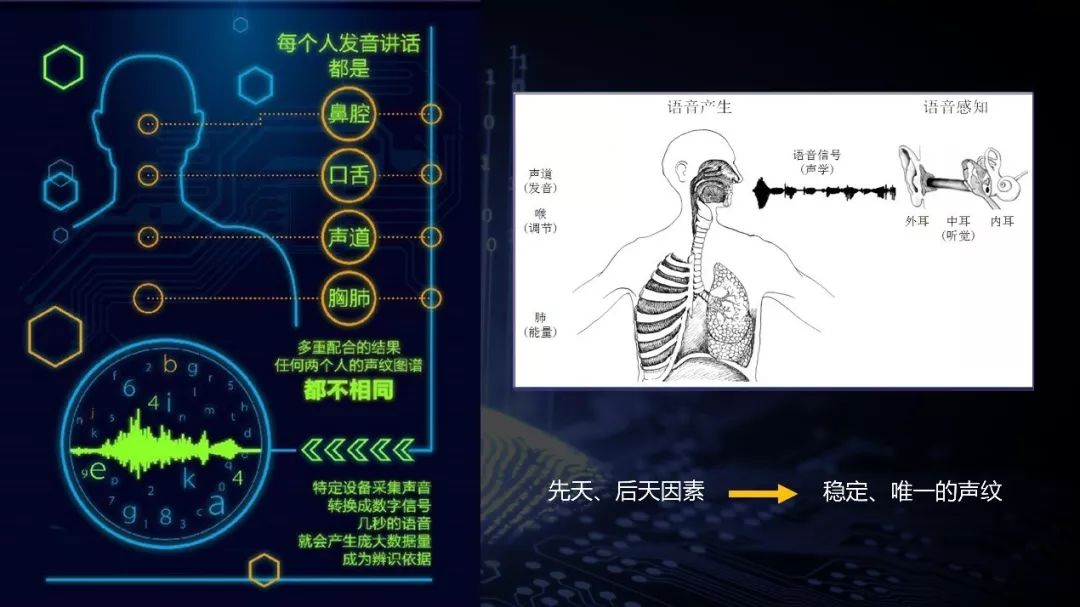 声纹其实只是语言中一项非常简单的内容,跟人的生理特征(声道)有很大的关系。每个人的声道都不一样(长度、形状等),因此每个人的声纹也不一样。
声纹其实只是语言中一项非常简单的内容,跟人的生理特征(声道)有很大的关系。每个人的声道都不一样(长度、形状等),因此每个人的声纹也不一样。
曾经山西省公安厅找了23对同卵双胞胎,想研究他们的声音能不能区分开。结果发现, 即便是双胞胎声音也不一样 ——虽然人耳可能听不出来,但是机器确实分得开。
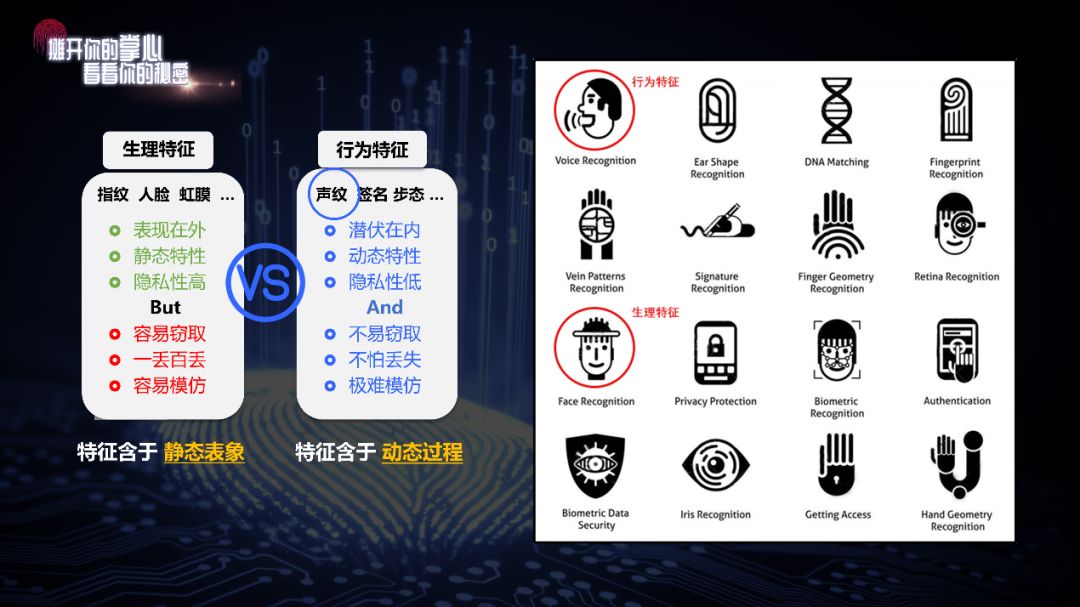 声纹属于生物特征。“生物特征”这个词现在非常流行,大家可能也有关注,是指能够确定身份的人自身的一些信息。
声纹属于生物特征。“生物特征”这个词现在非常流行,大家可能也有关注,是指能够确定身份的人自身的一些信息。
生物特征包含生理特征和行为特征两种。
指纹、人脸等等属于生理特征,信息含于静态表象,从生到死基本不变;声纹属于行为特征,信息含于动态过程,即使同一个人说同样的词、同样短语,也没有任何两次是一样的,会存在波形、时间、音量、情感等方面的差异。但声纹还兼具生理特征,因为它跟声道有关系。
声纹识别的分类有很多,主要有以下两类——
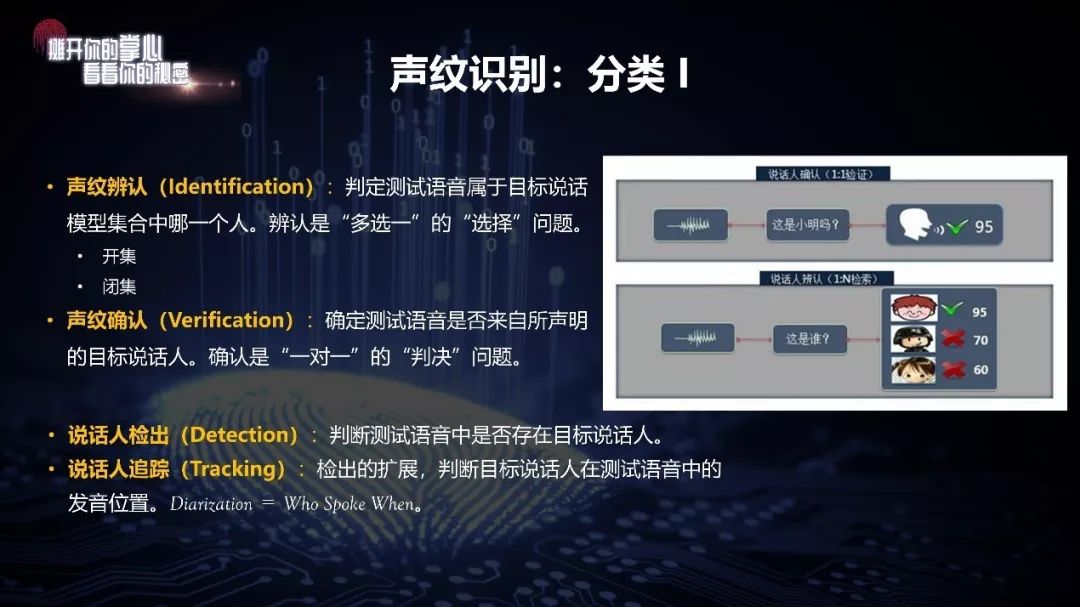 第一种与指纹、人脸识别类似,分为声纹辨认、声纹确认,另外还有说话人检出和说话人追踪。
第一种与指纹、人脸识别类似,分为声纹辨认、声纹确认,另外还有说话人检出和说话人追踪。
 第二种分类为声纹特有,包括文本无关、文本相关和文本提示。
第二种分类为声纹特有,包括文本无关、文本相关和文本提示。
用文本无关或者文本相关的识别方法做应用,你可能会想,会不会把录下的声音存到系统里呢?所以也许会涉及安全性问题。我们后来想到一种办法(文本提示):让用户每次说的话是都从一个集合里面随机挑出来的。 只有保证内容和用户都对,才认为这次认证是对的 。
声纹识别其实有些不同:指纹、掌纹等等都是可见的,而声纹不可见,只能听。
那么,怎么去做识别声纹呢?
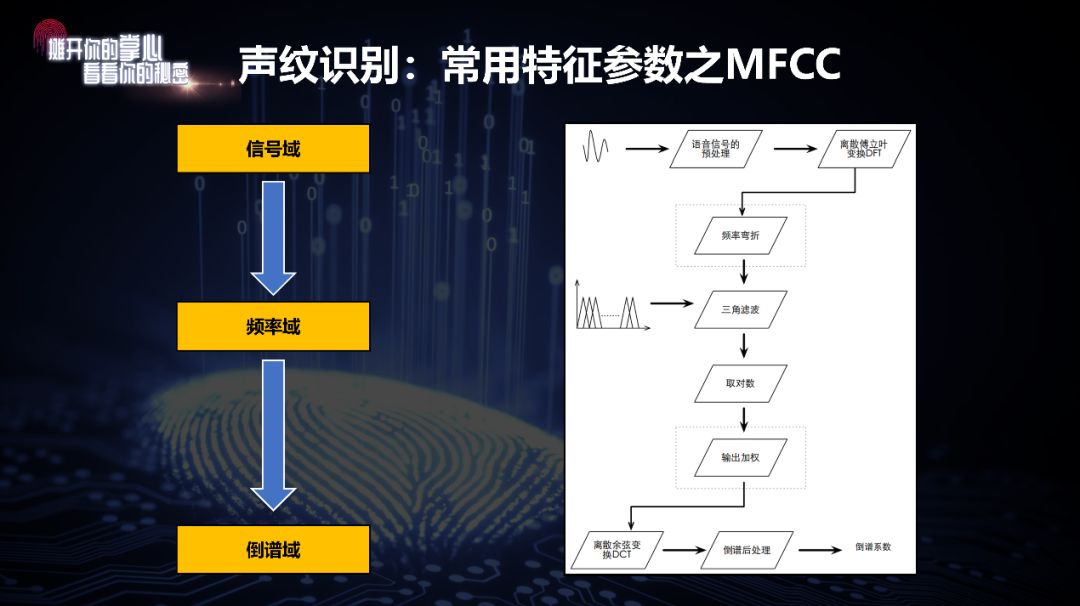 首先是特征提取,就是先从信号域通过傅里叶变换到频率域,然后再通过处理到倒谱域,其中流程如右图所示。
首先是特征提取,就是先从信号域通过傅里叶变换到频率域,然后再通过处理到倒谱域,其中流程如右图所示。
经过上述处理,我们可以看到一定特性。比如我说某个音在这个区域,另一个人说这个音可能在另一个区域。也就是说,可以通过描述语音特征,来描述发音的人。
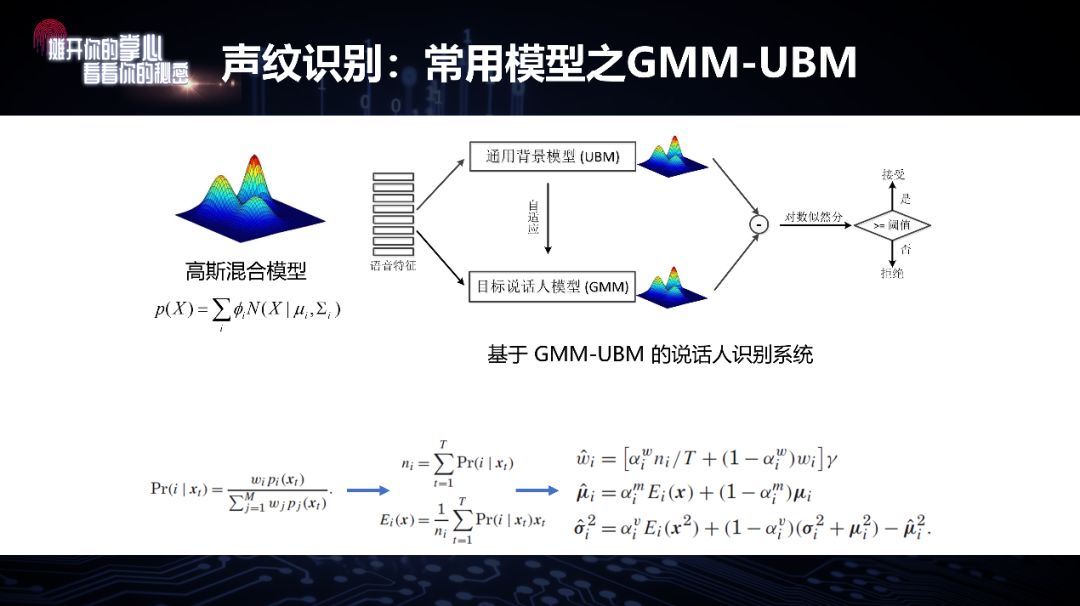 也正因为此,我们往往不叫“声纹模板”而直接叫“声纹模型”,每个人的声纹模型都会不一样。
也正因为此,我们往往不叫“声纹模板”而直接叫“声纹模型”,每个人的声纹模型都会不一样。
 但是用声纹去鉴别身份,一个非常重要的研究点是稳定性。因为每个人每次说话声音都不一样,身体状况(如生病感冒)、生理变化(如变声期)以及环境噪音都会造成声音变化。
但是用声纹去鉴别身份,一个非常重要的研究点是稳定性。因为每个人每次说话声音都不一样,身体状况(如生病感冒)、生理变化(如变声期)以及环境噪音都会造成声音变化。
那么,声纹到底可靠吗?
如果答案是不可靠,声纹识别就很难做到。
尽管上述因素会对识别造成影响,但还是能够识别出来,因为蕴藏在一维信号里的声纹信息是可以分开的。
我之前做过一个实验:喝酒和没喝酒的状态下,声音是否能被识别。结果发现没有问题。不过喝到九成醉之后,舌头直了,词说不清楚,就不太能进行语言识别了,虽然声纹识别没有问题;但是让他再清楚地说一遍,就又能识别了。
5G发展之后,大家非常想实现的一个事情就是远程认证身份。如果需要把身份证寄过去,一来一回,十分麻烦。
声纹识别就曾经在身份认证里做了一些事情。
关于生物特征识别,过去大家都比较关注准确率,现在则会更多关心安全性。但是我想跟大家说的是, 任何人的生物特征都是唯一的,是由基因决定的,而我们所谓的误差通常是技术手段导致的 。
但是,声纹用于身份认证还要解决两个非常关键的问题,我们来看两个案例——
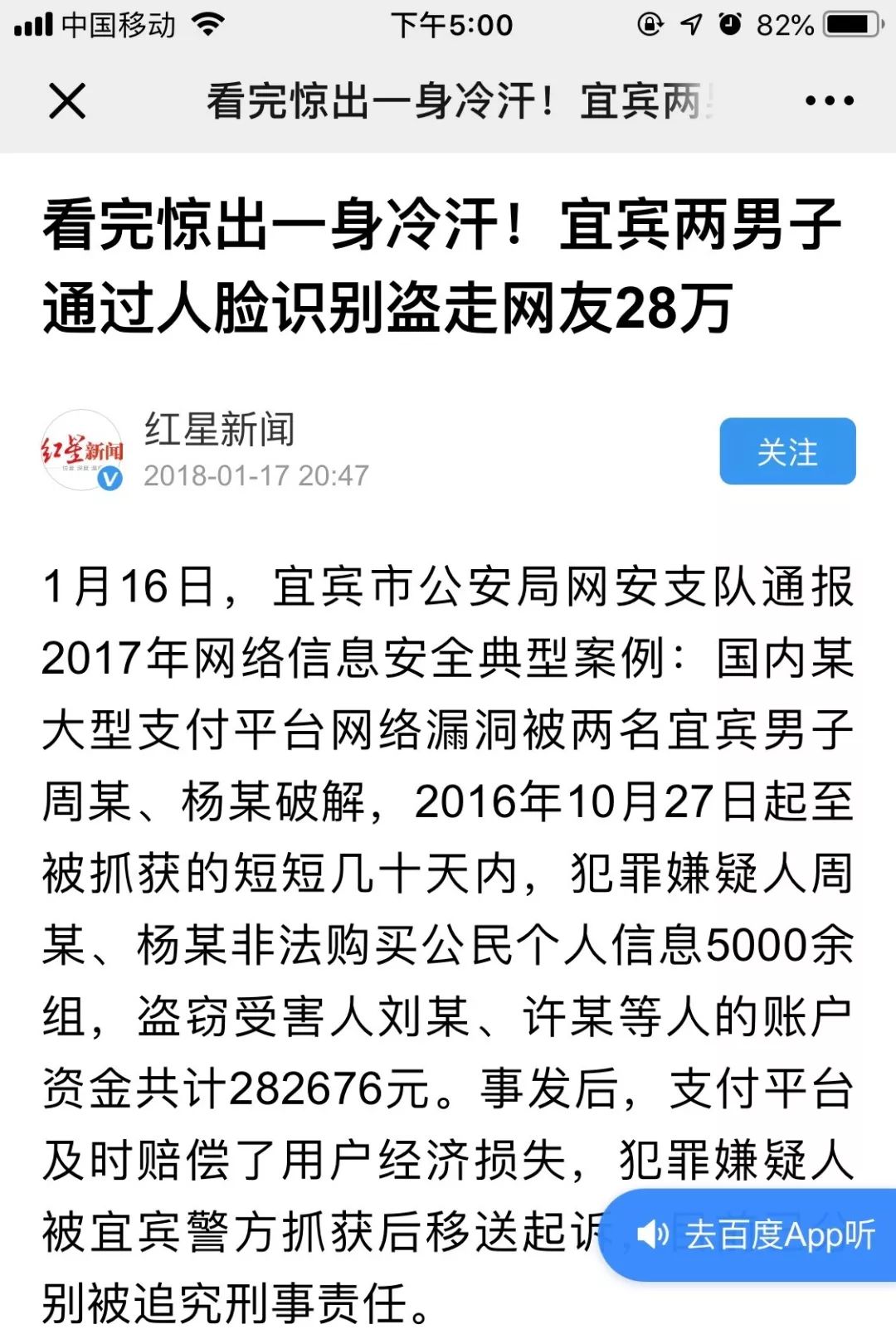 2018年1月16日,犯罪分子用照片通过银行的人脸识别,顺利取到钱。虽然银行有时候会让我们摇头晃脑进行活体检测,但是仍有问题:用目标人的照片骗过人脸识别,在活体检测时,他自己晃脑袋、摇头和张嘴,最后还是通过了。所以怎么防止假体攻击,是一件非常关键的事情。
2018年1月16日,犯罪分子用照片通过银行的人脸识别,顺利取到钱。虽然银行有时候会让我们摇头晃脑进行活体检测,但是仍有问题:用目标人的照片骗过人脸识别,在活体检测时,他自己晃脑袋、摇头和张嘴,最后还是通过了。所以怎么防止假体攻击,是一件非常关键的事情。
另外一个问题是关于真实意图的检测。当时iPhone的指纹解锁出来后,就曾经出现好多小两口吵架,因为在对方睡着之后打开手机看了聊天记录。
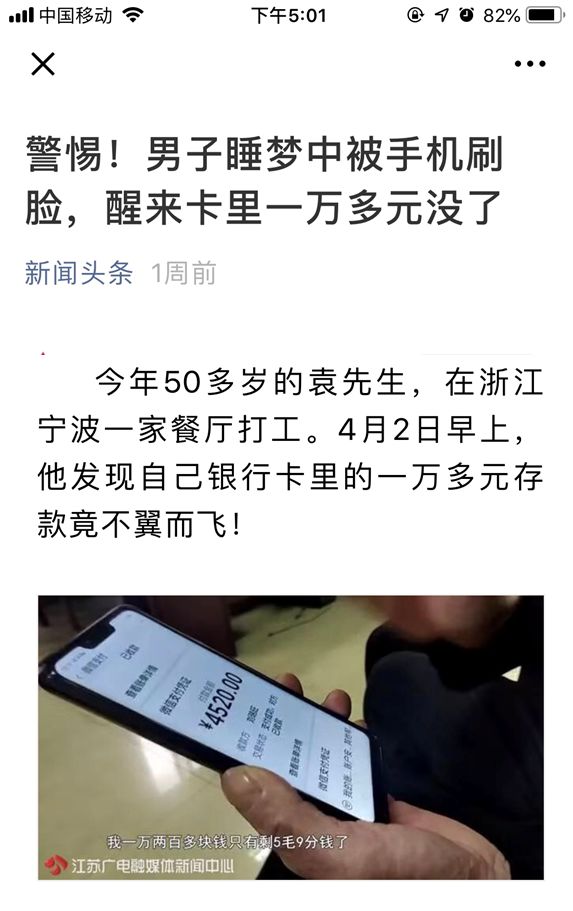 第二个案件,就是两人合租,犯罪分子趁舍友睡着用舍友的脸解锁了手机,然后把手机里的钱转走。虽然这样的事情通常不会发生在身边,但是一旦能够通过网络发生,风险就很大了。
第二个案件,就是两人合租,犯罪分子趁舍友睡着用舍友的脸解锁了手机,然后把手机里的钱转走。虽然这样的事情通常不会发生在身边,但是一旦能够通过网络发生,风险就很大了。
所以这两个问题都要解决。
 声音作为一种因子,就要考虑防攻击的问题。比如说声音模仿——我学你说话,然后语音合成。现在有好多类似工具,如果把奥巴马的声音拿过来学一学,最后就能替奥巴马发言说话。
声音作为一种因子,就要考虑防攻击的问题。比如说声音模仿——我学你说话,然后语音合成。现在有好多类似工具,如果把奥巴马的声音拿过来学一学,最后就能替奥巴马发言说话。
当然,对于声音模仿、语音合成和声音转换,现在是有办法解决的。但是,还有一个更可怕也更麻烦的攻击方式——录音重放,因为声音是真的,如假包换。
那怎么检测真假?
你可能会说,可以让他随机说话。
这种方法也有风险。俗话说,不怕贼偷就怕贼惦记。如果有人跟你很熟,把你的声音都录下来,汉语就418个音节,完全可以根据指示进行拼接。
不过,大家也不用太担心。因为我们做了一些研究的工作,最后发现,录音基本上可以做到百分之百地检测出来。
世界上没有百分之百安全,所以声纹防攻击还要有一些组合的策略,增加破解难度。
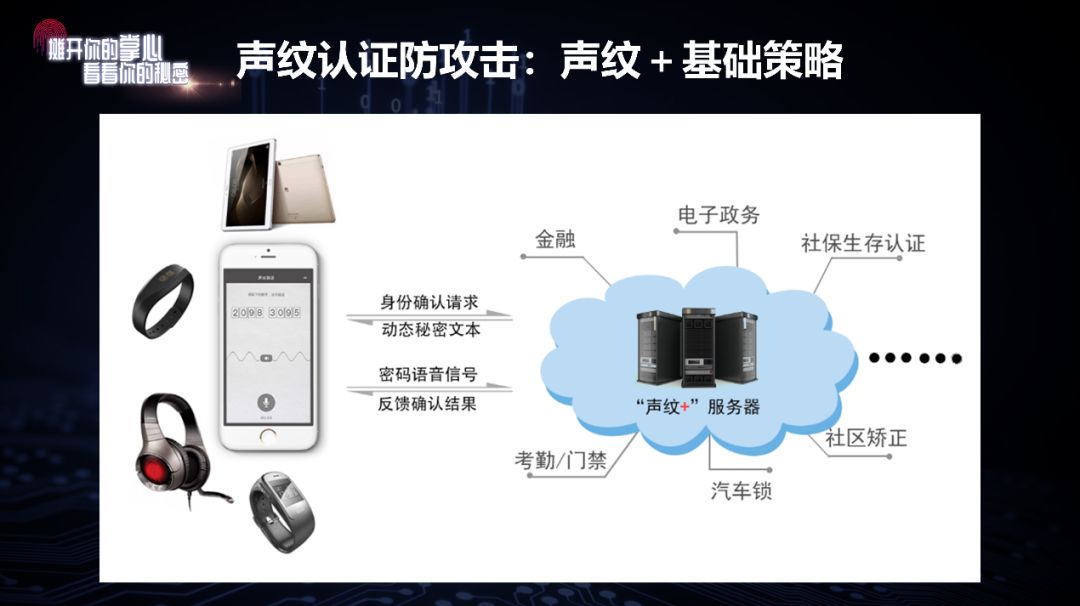 比如说,我们自己可以变化说话的方式。在用数字“0”作为密码动态码时,可以开始念“零”,后来念“圈”,过两天还念成“轮胎”……这样一来,即便是把十个数的声音都录下来,也没法攻击——不知道我的读音其实已经换了。
比如说,我们自己可以变化说话的方式。在用数字“0”作为密码动态码时,可以开始念“零”,后来念“圈”,过两天还念成“轮胎”……这样一来,即便是把十个数的声音都录下来,也没法攻击——不知道我的读音其实已经换了。
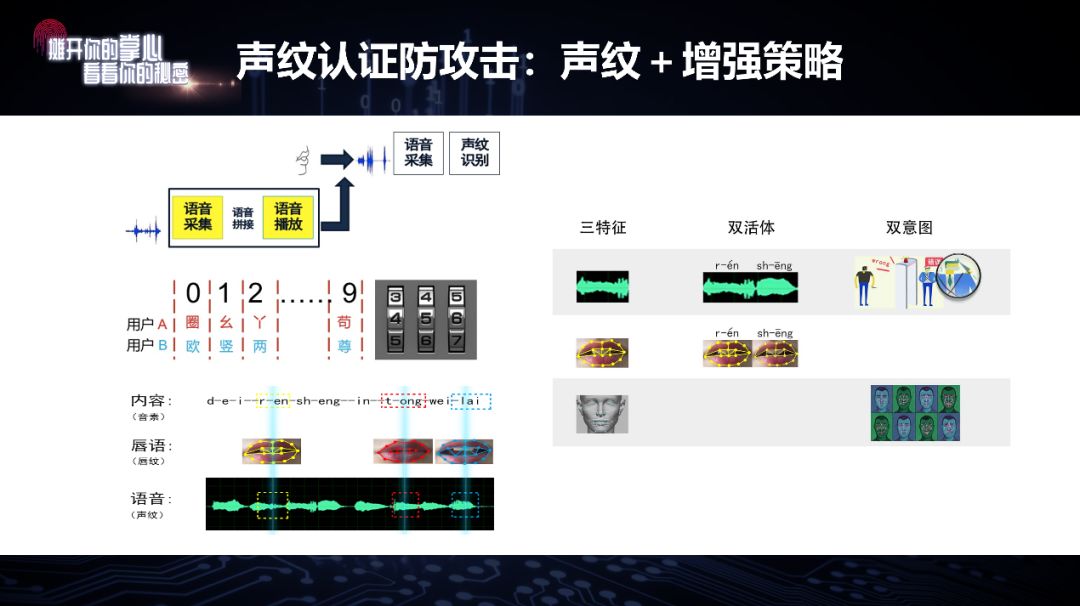 还可以用多模态,比如和嘴唇的特征结合。大家知道,一些基于智能手机的远程的应用比较多,而智能手机有两个标配的传感器,一个是麦克风,另一个是摄像头。所以可以在用户拿着手机说话的时候,把嘴唇也录进去;识别是本人后,再要求说数字,内容也对、时序也对才允许通过。这样一来,就明显增加了攻击难度。
还可以用多模态,比如和嘴唇的特征结合。大家知道,一些基于智能手机的远程的应用比较多,而智能手机有两个标配的传感器,一个是麦克风,另一个是摄像头。所以可以在用户拿着手机说话的时候,把嘴唇也录进去;识别是本人后,再要求说数字,内容也对、时序也对才允许通过。这样一来,就明显增加了攻击难度。
此外,情感检测现在已经可以做到了,这方面我们的研究在国际上比赛拿过第一。具体来说,就是根据人脸看表情,然后根据声音识别情感。二者相结合,就能知道用户是不是受人胁迫。如果识别出这种情况,系统就会就报警。
声音方面的检测比较好做,主要有以下几个方面——
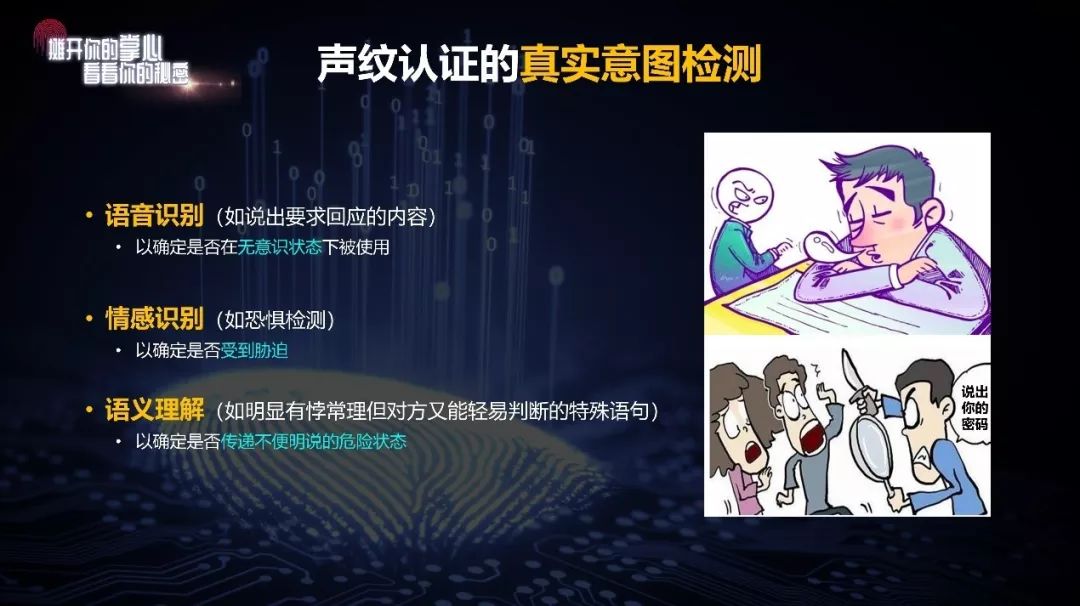 语音识别。如果用户睡着了,显然不可能按照提示说话,就避免了被盗用。
语音识别。如果用户睡着了,显然不可能按照提示说话,就避免了被盗用。
情感识别。如果受人逼迫,会自然而然地流露出恐惧,在声音和微表情里面均会有体现。
语义理解。可以通过设定明显有悖常理但能轻易判断的特殊语句(比如多次将“12”念作“23”),来判断用户是否试图传递不便说明的危险状态。
所以,我们可以把几种不同的信息结合起来,提供一个比较安全的检测手段。
 公安破案现在是声纹识别的主要应用领域之一,能够通过电话以及网络语音通话识别嫌疑人身份。
公安破案现在是声纹识别的主要应用领域之一,能够通过电话以及网络语音通话识别嫌疑人身份。
 金融领域(如国内外好多银行)现在也已经开始大量使用声纹识别了。在没有任何证件、没有U盾的情况下,需要网上办理业务,声音认证身份是最方便的。
金融领域(如国内外好多银行)现在也已经开始大量使用声纹识别了。在没有任何证件、没有U盾的情况下,需要网上办理业务,声音认证身份是最方便的。
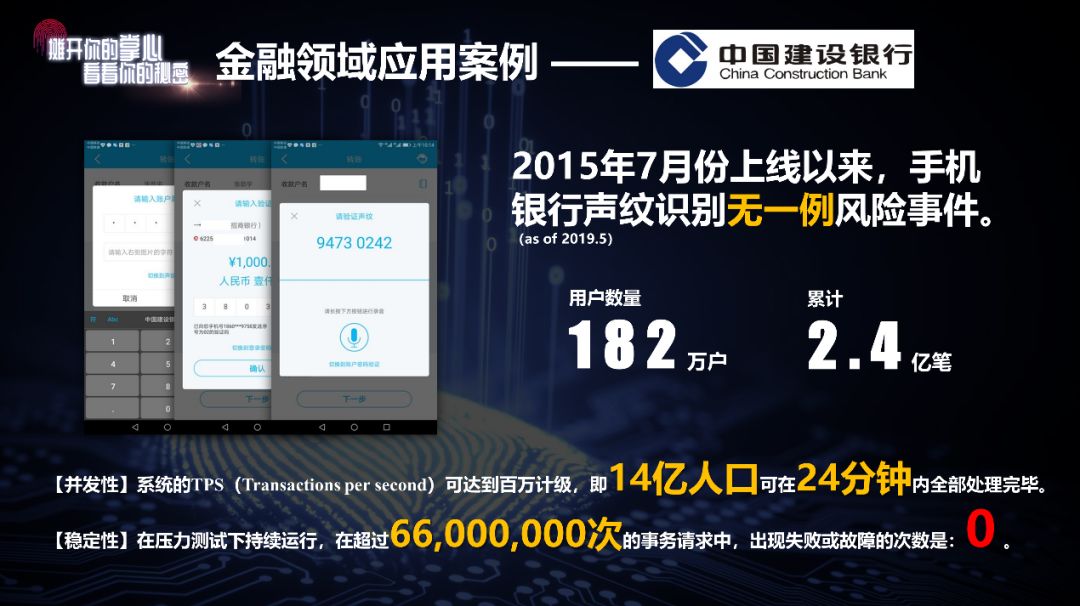 建设银行自2015年上线手机银行声纹识别功能后,用户数量已经达到182万,迄今为止没有发生过一次失误。
建设银行自2015年上线手机银行声纹识别功能后,用户数量已经达到182万,迄今为止没有发生过一次失误。
 其它领域的应用也很多,在保险、驾驶、航空和高铁等方面都有涉及。
其它领域的应用也很多,在保险、驾驶、航空和高铁等方面都有涉及。
 2017年得意音通组建了得意音通信息技术研究院,延聘全球顶级的人工智能专家。
2017年得意音通组建了得意音通信息技术研究院,延聘全球顶级的人工智能专家。
 其中,张钹院士是中国人工智能鼻祖——人工智能发展了六十多年,他工作时间也是六十多年。庄炳湟院士来自美国。我们研究的主要领域是语言理解、语音识别和声纹识别三个方面,研究成果很好地解决了一些问题。
其中,张钹院士是中国人工智能鼻祖——人工智能发展了六十多年,他工作时间也是六十多年。庄炳湟院士来自美国。我们研究的主要领域是语言理解、语音识别和声纹识别三个方面,研究成果很好地解决了一些问题。
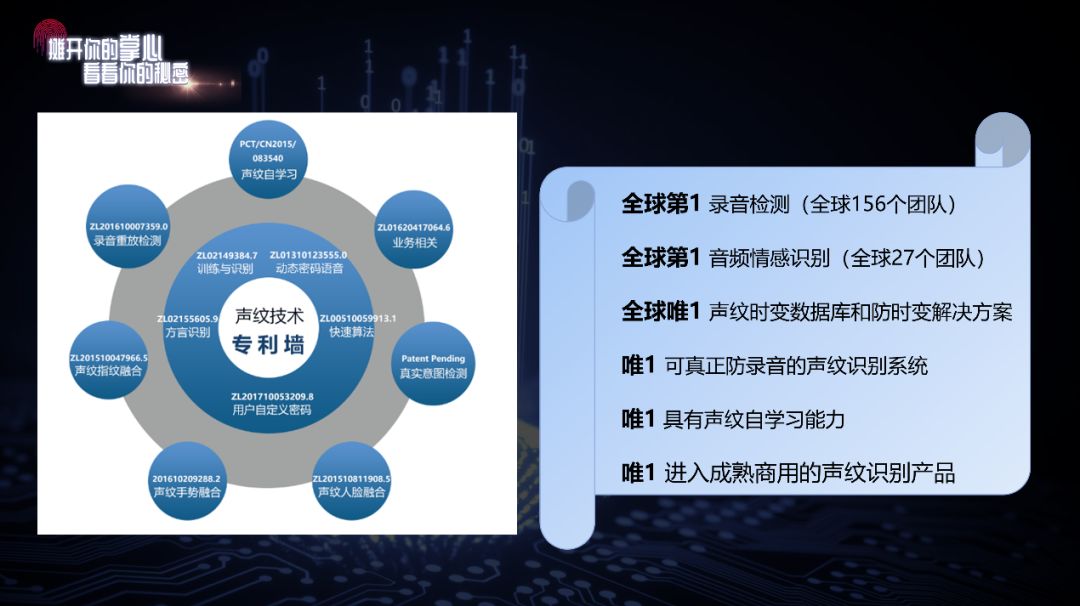 我们的研究成果, 目前好多是“第一”或者“唯一”的 。刚才提到的录音检测,今年年初,全球156个队伍我们排名第一;现在错误率几乎是零——不过还有一个条件,就是录音设备要见过才能识别出来。根据前不久刚出的新结果显示,甚至没见过的录音设备都能检测出来,可以更大程度保证安全。
我们的研究成果, 目前好多是“第一”或者“唯一”的 。刚才提到的录音检测,今年年初,全球156个队伍我们排名第一;现在错误率几乎是零——不过还有一个条件,就是录音设备要见过才能识别出来。根据前不久刚出的新结果显示,甚至没见过的录音设备都能检测出来,可以更大程度保证安全。
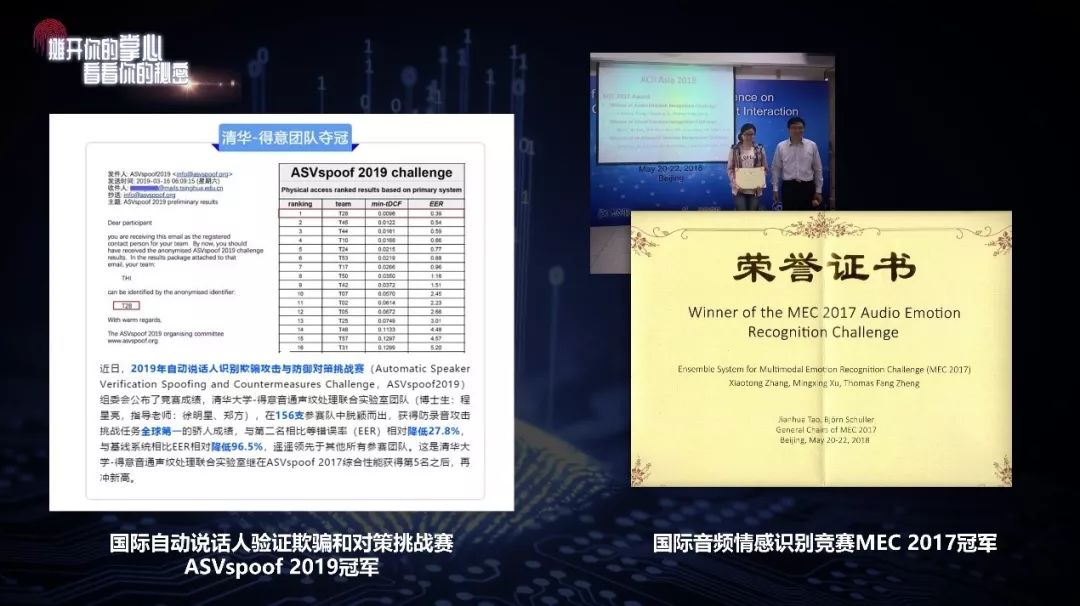 这两项分别为我们获得的国际防录音检测大赛和情感检测大赛的冠军。
这两项分别为我们获得的国际防录音检测大赛和情感检测大赛的冠军。
 如今,声纹识别已经开始在全国各地推广使用。在贵州,我们建立了一个声纹身份认证云,公安和社保金融都开始逐渐关联。不仅如此,陕西、河北、山东、内蒙等其他几个省也都开始接入。
如今,声纹识别已经开始在全国各地推广使用。在贵州,我们建立了一个声纹身份认证云,公安和社保金融都开始逐渐关联。不仅如此,陕西、河北、山东、内蒙等其他几个省也都开始接入。
未来会是什么样子呢?
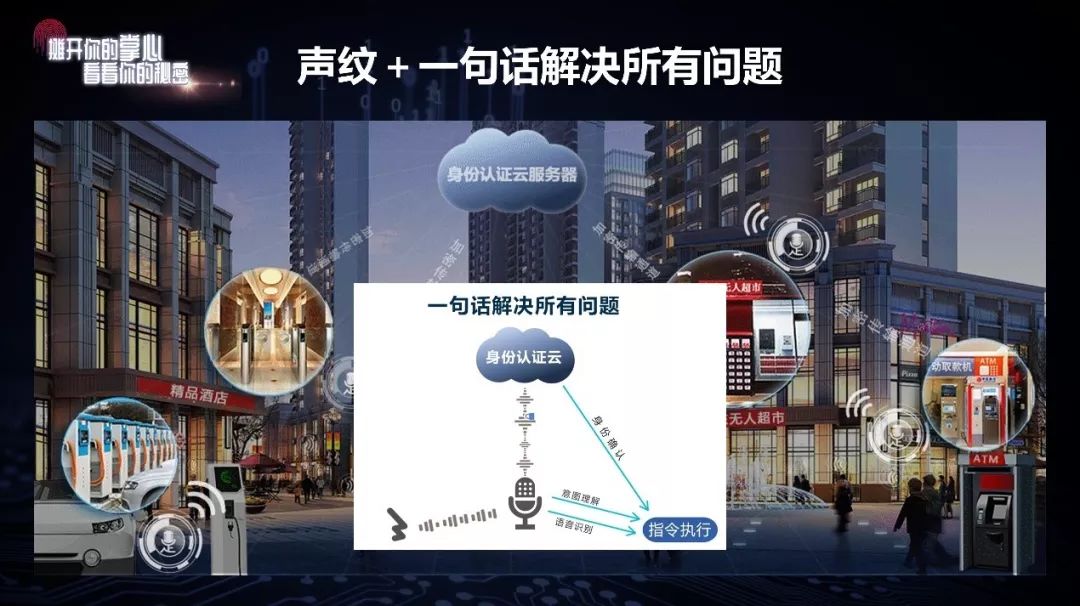 这幅图片是我想象的一个场景,就是可以随时随地低成本地解决所有问题。在无人商店、旅馆、加油站等很多场景,只要加个麦克风,就能进行声纹认证——5G推行以后,到处都能连上网,甚至珠穆朗玛峰都可以。说完了传过去,认证通过之后,就可以办理各种业务,方便了许多。
这幅图片是我想象的一个场景,就是可以随时随地低成本地解决所有问题。在无人商店、旅馆、加油站等很多场景,只要加个麦克风,就能进行声纹认证——5G推行以后,到处都能连上网,甚至珠穆朗玛峰都可以。说完了传过去,认证通过之后,就可以办理各种业务,方便了许多。
声音作为一种比较特殊的信号,简单又丰富,是辩证法的高度统一,可以很好地为大家服务。而且在各种不同的信号中,声音有一个很不同的特点,就是它可以双向交互。正是这种特性,能够“让21世纪成为一个语音的世纪”,这是比尔盖茨说的。
谢谢各位。
 演讲嘉宾郑方:《声纹识别技术,现实世界中的“芝麻开门”》
演讲嘉宾郑方:《声纹识别技术,现实世界中的“芝麻开门”》
作者:郑方
编辑:麦芽杨、凝音
题图来源:大话西游

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国