

深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。1
简介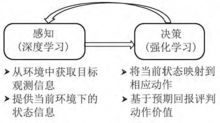
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。1
原理框架DRL是一种端对端(end-to-end)的感知与控制系统,具有很强的通用性.其学习过程可以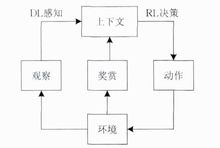 描述为:
描述为:
(1)在每个时刻agent与环境交互得到一个高维度的观察,并利用DL方法来感知观察,以得到具体的状态特征表示;
(2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作;
(3)环境对此动作做出反应,并得到下一个观察.通过不断循环以上过程,最终可以得到实现目标的最优策略。2
DRL原理框架如图所示。
DQN算法DQN算法融合了神经网络和Q learning的方法, 名字叫做 Deep Q Network。
DQN 有一个记忆库用于学习之前的经历。在之前的简介影片中提到过, Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率。Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的。有了这两种提升手段, DQN 才能在一些游戏中超越人类。
基于卷积神经网络的深度强化学习由于卷积神经网络对图像处理拥有天然的优势,将卷积神经网络与强化学习结合处理图像数据的感知决策任务成了很多学者的研究方向。
深度Q网络是深度强化学习领域的开创性工作。它采用时间上相邻的4帧游戏画面作为原始图像输入,经过深度卷积神经网络和全连接神经网络,输出状态动作Q函数,实现了端到端的学习控制。
深度Q网络使用带有参数θ的Q函数Q(s, a; θ)去逼近值函数。迭代次数为i 时,损失函数为
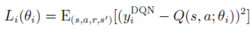
其中
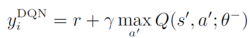
θi代表学习过程中的网络参数。经过一段时间的学习后, 新的θi更新θ−。具体的学习过程根据:
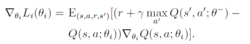
基于递归神经网络的深度强化学习深度强化学习面临的问题往往具有很强的时间依赖性,而递归神经网络适合处理和时间序列相关的问题。强化学习与递归神经网络的结合也是深度强化学习的主要形式。
对于时间序列信息,深度Q网络的处理方法是加入经验回放机制。但是经验回放的记忆能力有限,每个决策点需要获取整个输入画面进行感知记忆。将长短时记忆网络与深度Q网络结合,提出深度递归Q网络(deep recurrent Q network,DRQN),在部分可观测马尔科夫决策过程(partiallyobservable Markov decision process, POMDP)中表现出了更好的鲁棒性,同时在缺失若干帧画面的情况下也能获得很好的实验结果。
受此启发的深度注意力递归Q网络(deep attentionrecurrent Q network, DARQN)。它能够选择性地重点关注相关信息区域,减少深度神经网络的参数数量和计算开销。
本词条内容贡献者为:
曹慧慧 - 副教授 - 中国矿业大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国