

概率模型,给定一个用户的查询串,相对于该串存在一个包含所有相关文档的集合。我们把这样的集合看作是一个理想的结果文档集,在给出理想结果集后,我们能很容易得到结果文档。
这样我们可以把查询处理看作是对理想结果文档集属性的处理。问题是我们并不能确切地知道这些属性,我们所知道的是存在索引术语来表示这些属性。由于在查询期间这些属性都是不可见的,这就需要在初始阶段来估计这些属性。这种初始阶段的估计允许我们对首次检索的文档集合返回理想的结果集,并产生一个初步的概率描述。
简介概率模型(Statistical Model,也称为Probabilistic Model)是用来描述不同随机变量之间关系的数学模型,通常情况下刻画了一个或多个随机变量之间的相互非确定性的概率关系。从数学上讲,该模型通常被表达为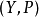 ,其中 Y 是观测集合用来描述可能的观测结果, P 是 Y 对应的概率分布函数集合。若使用概率模型,一般而言需假设存在一个确定的分布P 生成观测数据 Y 。因此通常使用统计推断的办法确定集合 P 中谁是数据产生的原因。
,其中 Y 是观测集合用来描述可能的观测结果, P 是 Y 对应的概率分布函数集合。若使用概率模型,一般而言需假设存在一个确定的分布P 生成观测数据 Y 。因此通常使用统计推断的办法确定集合 P 中谁是数据产生的原因。
大多数统计检验都可以被理解为一种概率模型。例如,一个比较两组数据均值的学生t检验可以被认为是对该概率模型参数是否为0的检测。此外,检验与模型的另一个共同点则是两者都需要提出假设并且误差在模型中常被假设为正态分布。1
定义概率模型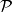 是一个概率分布函数或密度函数的集合。可分为参数模型,无参数和半参数模型。
是一个概率分布函数或密度函数的集合。可分为参数模型,无参数和半参数模型。
参数模型是一组由有限维参数构成的分布集合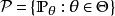 。其中
。其中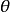 是参数,而
是参数,而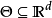 是其可行欧几里得子空间。概率模型可被用来描述一组可产生已知采样数据的分布集合。例如,假设数据产生于唯一参数的高斯分布,则我们可假设该概率模型为
是其可行欧几里得子空间。概率模型可被用来描述一组可产生已知采样数据的分布集合。例如,假设数据产生于唯一参数的高斯分布,则我们可假设该概率模型为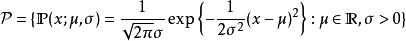 。
。
无参数模型则是一组由无限维参数构成的概率分布函数集合,可被表示为 。
。
相比于无参数模型和参数模型,半参数模型也由无限维参数构成,但其在分布函数空间内并不紧密。例如,一组混叠的高斯模型。确切的说,如果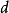 是参数的维度,是数据点的大小,如果随着
是参数的维度,是数据点的大小,如果随着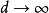 和
和 则,则我们称之为半参数模型。2
则,则我们称之为半参数模型。2
处理过程为了提高理想结果集的描述概率,系统需要与用户进行交互式(feedback)操作。具体处理过程如下:用户大致浏览一下结果文档,决定哪些是相关的,哪些是不相关的;然后系统利用该信息重新定义理想结果集的概率描述;重复以上操作,就会越来越接近真正的结果文档集。1
算法下面将具体讨论一种简单的算法。
在查询的开始间段只定义了查询串,还没有得到结果文档集。我们不得不作一些简单的假设,例如:(a)假定 对所有的索引术语 来说是常数(一般等于0.5);(b)假定索引术语在非相关文档中的分布可以由索引术语在集合中所有文档中的分布来近似表示。这两种假设用公式表示如下:
表示出现索引术语 的文档的数目,N是集合中总的文档的数目。在上面的假设下,我们可以得到部分包含查询串的文档,并为他们提供一个初始的相关概率。1
优点概率模型的优点在于,文档可以按照他们相关概率递减的顺序来计算秩(rank)。他的缺点在于:开始时需要猜想把文档分为相关和不相关的两个集合,实际上这种模型没有考虑索引术语在文档中的频率(因为所有的权重都是二元的),而索引术语都是相互独立的。2
本词条内容贡献者为:
曹慧慧 - 副教授 - 中国矿业大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国