

隐含狄利克雷分布(英语:Latent Dirichlet allocation,简称LDA),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。
简介隐含狄利克雷分布也是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
LDA首先由Blei, David M.、吴恩达和Jordan, Michael I于2003年提出,目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。 1
数学模型LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
另外,正如Beta分布是二项式分布的共轭先验概率分布,狄利克雷分布作为多项式分布的共轭先验概率分布。因此正如LDA贝叶斯网络结构中所描述的,在LDA模型中一篇文档生成的方式如下:
从狄利克雷分布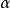 中取样生成文档i的主题分布
中取样生成文档i的主题分布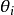
从主题的多项式分布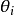 中取样生成文档i第j个词的主题
中取样生成文档i第j个词的主题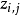
从狄利克雷分布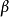 中取样生成主题
中取样生成主题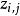 的词语分布
的词语分布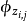
从词语的多项式分布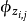 中采样最终生成词语
中采样最终生成词语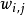
因此整个模型中所有可见变量以及隐藏变量的联合分布是
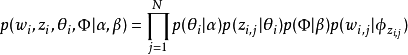
最终一篇文档的单词分布的最大似然估计可以通过将上式的{\displaystyle \theta _{i}}以及{\displaystyle \Phi }进行积分和对{\displaystyle z_{i}}进行求和得到
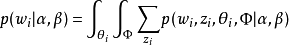
根据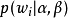 的最大似然估计,最终可以通过吉布斯采样等方法估计出模型中的参数。1
的最大似然估计,最终可以通过吉布斯采样等方法估计出模型中的参数。1
使用吉布斯采样估计LDA参数在LDA最初提出的时候,人们使用EM算法进行求解,后来人们普遍开始使用较为简单的Gibbs Sampling,具体过程如下:
首先对所有文档中的所有词遍历一遍,为其都随机分配一个主题,即zm,n=k~Mult(1/K),其中m表示第m篇文档,n表示文档中的第n个词,k表示主题,K表示主题的总数,之后将对应的nm+1, nm+1, nk+1, nk+1, 他们分别表示在m文档中k主题出现的次数,m文档中主题数量的和,k主题对应的t词的次数,k主题对应的总词数。
之后对下述操作进行重复迭代。
对所有文档中的所有词进行遍历,假如当前文档m的词t对应主题为k,则nm-1, nm-1, nk-1, nk-1, 即先拿出当前词,之后根据LDA中topic sample的概率分布sample出新的主题,在对应的nm, nm, nk, nk上分别+1。
迭代完成后输出主题-词参数矩阵φ和文档-主题矩阵θ1
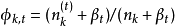
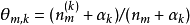
本词条内容贡献者为:
尹维龙 - 副教授 - 哈尔滨工业大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国