

矢量空间模型是一个把文本文件表示为标识符(比如索引)向量的代数模型。它应用于信息过滤、信息检索、索引以及相关排序。
定义文档和查询都用向量来表示。
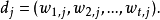
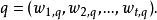 每一维都对应于一个个别的词组。如果某个词组出现在了文档中,那它在向量中的值就非零。已经发展出了不少的方法来计算这些值,这些值叫做(词组)权重。其中一种最为知名的方式是tf-idf权重(见下面的例子)。
每一维都对应于一个个别的词组。如果某个词组出现在了文档中,那它在向量中的值就非零。已经发展出了不少的方法来计算这些值,这些值叫做(词组)权重。其中一种最为知名的方式是tf-idf权重(见下面的例子)。
词组的定义按不同应用而定。典型的词组就是一个单一的词、关键词、或者较长的短语。如果将词语选为词组,那么向量的维数就是词汇表中的词语个数(出现在语料库中的不同词语的个数)。
通过向量运算,可以对各文档和各查询作比较。
应用据文档相似度理论的假设,如要在一次关键词查询中计算各文档间的相关排序,只需比较每个文档向量和原先查询向量(跟文档向量的类型是相同的)之间的角度偏差。1
实际上,计算向量之间夹角的余弦比直接计算夹角本身要简单。
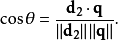
其中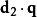 是文档向量和查询向量的点乘。
是文档向量和查询向量的点乘。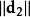 是向量d2的模,而
是向量d2的模,而 是向量q的模。向量的模通过下面的公式来计算:
是向量q的模。向量的模通过下面的公式来计算:
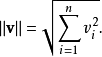
由于这个模型所考虑的所有向量都是每个元素严格非负的,因此如果余弦值为零,则表示查询向量和文档向量是正交的,即不符合(换句话说,就是检索项在文档中没有找到)。如果要了解详细的信息可以查看余弦相似性这条目。
优点相对于标准布尔模型(Standard Boolean model),向量空间模型具有如下优点:
基于线性代数的简单模型
词组的权重不是二元的
文档和查询之间的相似度取值是连续的
允许根据文档间可能的相关性来进行排序
允许局部匹配
局限向量空间模型有如下局限:
不适用于较长的文档,因为它的相似值不理想(过小的内积和过高的维数)。
检索词组必须与文档中出现的词组精确匹配;词语子字串可能会导致“假阳性”匹配。
语义敏感度不佳;具有相同的语境但使用不同的词组的文档不能被关联起来,导致“假阴性匹配”。
词组在文档中出现的顺序在向量形式中无法表示出来。
假定词组在统计上是独立的。
权重是直观上获得的而不够正式。
然而,这些局限中的多数能够通过集合各种方法来解决,包括数学上的技术(比如奇异值分解)和词汇数据库(比如WordNet)。
基于及扩展了向量空间模型的模型基于及扩展了向量空间模型的模型包括:
广义向量空间模型
(增强的)基于主题的向量空间模型
潜在语义学
潜在语义索引
DSIR模型
词汇鉴别(Term Discrimination)
Rocchio分类
以向量空间模型为工具的软件使用向量空间模型做实验或者想基于它们实现研究服务的人或许会对以下的这些软件包感兴趣。
免费开放的软件资源Apache Lucene.这是一个高性能的软件,用java写的功能全面的文本搜索引擎。
SemanticVectors.语义向量索引,将随机投影算法(类似于潜在的语义分析)应用于Apache Lucene构建的文本词组矩阵。
Gensim是一个Python+NumPy的向量空间模型的框架。它包含对Tf–idf、潜在的语义索引、随机投影和潜在的狄利克雷边界的增值算法(有效利用内存空间)。
Antonio Gulli开发的Compressed vector space in C++
Text to Matrix Generator (TMG)用于一系列特殊文本挖掘的matlab工具箱。(1)指标化(2)检索(3)降维(4)聚类(5)分类。大多数的TMG都是用matlab编写的,小部分是用Perl编写的。它包括了LSI的实现和聚类、NMF以及其他方法。
SenseClusters,通过潜在的语义分析和单词的同现矩阵来进行文本和词组聚类的一个公开软件包。
S-Space Package,通过“统计语义”实现的的检索程序集成。
本词条内容贡献者为:
黄伦先 - 副教授 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国