

n元语法((n-gram grammar)建立在马尔可夫模型上的一种概率语法。
简介n元语法(英语:n-gram)指文本中连续出现的n个语词。n元语法模型是基于(n-1)阶马尔可夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。这一模型被广泛应用于概率论、通信理论、计算语言学(如基于统计的自然语言处理)、计算生物学(如序列分析)、数据压缩等领域。
当n分别为1、2、3时,又分别称为一元语法(unigram)、二元语法(bigram)与三元语法(trigram)。
马尔可夫链马尔可夫链(英语:Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫(俄语:Андрей Андреевич Марков)得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马尔可夫性质。马尔科夫链作为实际过程的统计模型具有许多应用。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。随机漫步就是马尔可夫链的例子。随机漫步中每一步的状态是在图形中的点,每一步可以移动到任何一个相邻的点,在这里移动到每一个点的概率都是相同的(无论之前漫步路径是如何的)。1
语言模型统计式的语言模型是借由一个机率分布,而指派机率给字词所组成的字串:
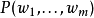
语言模型经常使用在许多自然语言处理方面的应用,如语音识别,机器翻译,词性标注,句法分析和资讯检索。由于字词与句子都是任意组合的长度,因此在训练过的语言模型中会出现未曾出现的字串(资料稀疏的问题),也使得在语料库中估算字串的机率变得很困难,这也是要使用近似的平滑n元语法(N-gram)模型之原因。
在语音辨识和在资料压缩的领域中,这种模式试图捕捉语言的特性,并预测在语音串列中的下一个字。
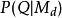 当用于资讯检索,语言模型是与文件有关的集合。以查询字“Q”作为输入,依据机率将文件作排序,而该机率代表该文件的语言模型所产生的语句之机率。2
当用于资讯检索,语言模型是与文件有关的集合。以查询字“Q”作为输入,依据机率将文件作排序,而该机率代表该文件的语言模型所产生的语句之机率。2
示例
|| || 不同领域中的n元语法示例
本词条内容贡献者为:
任毅如 - 副教授 - 湖南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国