

在信息论中,香农的信源编码定理(或无噪声编码定理)确立了数据压缩的限度,以及香农熵的操作意义。信源编码定理表明(在极限情况下,随着独立同分布随机变量数据流的长度趋于无穷)不可能把数据压缩得码率(每个符号的比特的平均数)比信源的香农熵还小,不满足的几乎可以肯定,信息将丢失。但是有可能使码率任意接近香农熵,且损失的概率极小。码符号的信源编码定理把码字的最小可能期望长度看作输入字(看作随机变量)的熵和目标编码表的大小的一个函数,给出了此函数的上界和下界。
简介信源编码是从信息源的符号(序列)到码符号集(通常是bit)的映射,使得信源符号可以从二进制位元(无损信源编码)或有一些失真(有损信源编码)中准确恢复。在信息论中,信源编码定理非正式地陈述为:
N 个熵均为 H(X) 的独立同分布的随机变量在 N → ∞ 时,可以很小的信息损失风险压缩成多于 N H(X) bit;但相反地,若压缩到少于 NH(X) bit,则信息几乎一定会丢失。令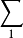 ,
,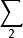 表示两个有限编码表,并令
表示两个有限编码表,并令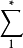 和
和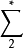 (分别)表示来自那些编码表的所有有限字的集合。设 X 为从
(分别)表示来自那些编码表的所有有限字的集合。设 X 为从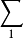 取值的随机变量,令 f 为从 到 的可译码,其中
取值的随机变量,令 f 为从 到 的可译码,其中 = a。令 S 表示字长 f (X) 给出的随机变量。
= a。令 S 表示字长 f (X) 给出的随机变量。
如果 f 是对 X 拥有最小期望字长的最佳码,那么(Shannon 1948):
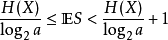
证明对于 1 ≤ i ≤ n 令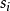 表示每个可能的
表示每个可能的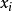 的字长。定义
的字长。定义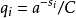 ,其中 C 会使得
,其中 C 会使得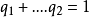 。于是
。于是
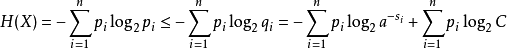
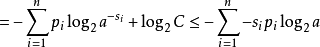
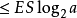
其中第二行由吉布斯不等式推出,而第五行由克拉夫特不等式推出:
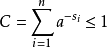
对第二个不等式我们可以令
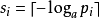
于是:
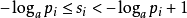
因此
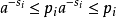
并且
因此由克拉夫特不等式,存在一种有这些字长的无前缀编码。因此最小的 S 满足
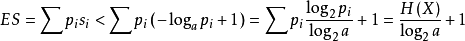
发展在以大数据为特征的信息时代,大量的信息流对信息数据的存储和传输带来了极大的挑战。大量的数据直接存储是高代价且不聪明的做法,信息压缩存储往往更加高效。很早以前,工程师们就已经掌握了简单的压缩技巧,例如 Huffman 压缩,复杂度低且效率很高的算数编码,以及通用的信源编码算法,像常用的 Lempel-Ziv 算法。然而,由于很多数据之间存在关联性,另外多信源情形下数据的分布式特性,使得可能存在更加聪明有效的信息压缩新技术,通信的网络化特征也预示着更为复杂的联合压缩策略相较于单独压缩,是更好的选择。所有这些,也迫切要求相应的信源编码理论得到不断发展,以提供理论支持。
美国数学家及工程师 C. E. Shannon在 1948 年发表了题为《A Mathematical Theory of Communication》的学术论文。在该论文中,他提出了通信的数学模型,从信息的抽象概念、信息的度量、压缩与传输等方面建立了一整套相对完整的通信数学理论。在这篇论文中,
Shannon 首次给出了著名的信源编码定理与信道编码定理这两大编码定理,奠定了一门崭新的学科,即信息论的基础,宣告了信息时代的到来。信息论作为一门关于通信基本理论的学科,自开创以来,指导了各种信息新技术的发展并指明了可以继续改进的方向,为信息时代的进步提供了最为根本的理论依据。Shannon 把所有可以产生信息的源端,比如声源、光源等抽象为“信源”,以一个概率空间p ,作为其数学表示。为了解决如何有效表示以及有效存储信息的问题,Shannon 在进行了深入的研究以后,最终给出了信源编码定理。该定理以一个简洁漂亮的数学量,即信源的信源熵 H,作为一个信源可以被无损压缩的理论下界。他在 1959 年发表的另一篇论文中,讨论了率失真问题,提出了率失真编码定理,丰富了信源编码理论。信源编码理论的另一个突破来自两位贝尔实验室的研究人员,D. Slepian 和J. Wolf, 他们在 1973 年解决了分布式相关信源编码问题。分布式是通信网络的一个重要特征,一个关于分布式的理论无疑会对工程应用产生积极的推动和指导作用。自此之后,对于各种模型的多用户信源编码问题的研究得到了快速的发展,取得了大量的研究成果。然而,尽管有不少重大的突破和十分漂亮的结果,信源编码理论还远不是一个完整的理论,甚至于已解决的问题远远少于未解决的问题。自 Slepian 和 Wolf 发表他们里程碑式的论文以后,30 多年过去了。但是后续绝大部分关于多信源编码问题考虑的是序列编码情形,关于无错变长多信源编码问题研究的相对少得多,这一理论需要得到发展。大多数学者在证明
Shannon 信源、信道编码定理,以及各种网络编码定理时,一般都使用随机编码技术与典型、联合典型等数学工具,得出了信源渐进无损压缩或限失真时的理论下限和信息渐进无错传输的理论上限(描述为各种 Shannon 信息量)。
然而,渐进可忽略的错误需要在编码长度非常大时才能获得,所以随机编码技术并不能直接拿来应用。另外,如果要求接收端知道信源压缩前的准确信息而不会出错,那么上述随机编码技术就没有作用了。由于无错误的信息论问题与组合、图论中的很多问题有密切的联系,比如 Shannon 著名的无错信道容量问题就可以描述为求一个 n次乘积图的独立顶点个数,以及两维 Kraft 不等式与相关信源特征图中最大团(clique)的个数的关系,以及其他一些原因,使得无错信息理论得到了科研工作者的重视,这一理论也逐渐发展成为信息论的一大研究分支。从任意小的渐进和忽略的错误概率到完全没有错误,似乎并不是很大的跳跃。然而事实情况是,这两种情形是截然不同的问题,解决各自问题的方法和工具也完全不相同。
许多研究人员对无错信源编码理论进行了讨论,提出了解决这一类问题的主要数学工具和手段,尤其是 J. Korner 结合图理论提出的图熵概念以及R. Ahlswede 的超图染色方法,对后续研究具有很大的启示作用。实现无错的编码方案有很多种,本文主要关注采用变长编码的方法。Shannon 的经典信源编码定理发表以后,很快 D. Huffman给出了最小开销码构造的 Huffman 编码程序。我们知道对于概率分布已知的单信源,Huffman 编码将给出前缀码,通过观察输出码字序列,可以还原原始信源消息。作为前缀码存在的充分和必要条件的 Kraft 不等式首先由 Mc Millan给予证明,随后 Karush给出了更为常用证明方法。可译码是比前缀码更广泛的一类码,检验其可译性的Sardinas-Patterson 程序由 A. Sardinas 和 G. W. Patterson在 1956 年给出1。
信源编码为减小信源冗余度而对信源符号进行变换的方法。根据信源性质分类,有信源统计特性已知或未知、无失真或限失真、无记忆或有记忆信源的编码;按编码方法分类,有分组码或非分组码、等长码或变长码等。最常见的是信源统计特性已知的离散、平稳、无失真信源编码。主要方法有:①统计编码,如仙农码、费诺码、赫夫曼码、算术码等。②预测编码。③变换编码,以及上述方法的组合(混合编码)。对于信源统计特性未知的信源编码称为通用编码。衡量信源编码的主要指标是压缩比。在无失真编码中,压缩的极限是编码的平均码表等于信源的符号熵。在限失真编码中,冗余度的压缩极限与平均失真的关系服从信源的信息率失真R(D)函数。在工程应用中则是在压缩比,平均失真和工程实现之间寻求折中2。
本词条内容贡献者为:
王伟 - 副教授 - 上海交通大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国