

在贝叶斯统计学中,“最大后验概率估计”是后验概率分布的众数。利用最大后验概率估计可以获得对实验数据中无法直接观察到的量的点估计。它与最大似然估计中的经典方法有密切关系,但是它使用了一个增广的优化目标,进一步考虑了被估计量的先验概率分布。所以最大后验概率估计可以看作是规则化(regularization)的最大似然估计。
定义假设我们需要根据观察数据 估计没有观察到的总体参数
估计没有观察到的总体参数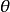 ,让
,让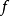 作为 的采样分布,这样
作为 的采样分布,这样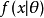 就是总体参数为 时的概率。函数
就是总体参数为 时的概率。函数
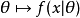
即为似然函数,其估计
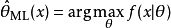
就是的最大似然估计。
假设存在一个先验分布 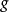 ,这就允许我们将作为贝叶斯统计(en:Bayesian statistics)中的随机变量,这样的后验分布就是:
,这就允许我们将作为贝叶斯统计(en:Bayesian statistics)中的随机变量,这样的后验分布就是:
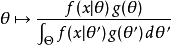
其中是的domain,这是贝叶斯定理的直接应用。
最大后验估计方法于是估计为这个随机变量的后验分布的众数:
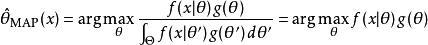
后验分布的分母与无关,所以在优化过程中不起作用。注意当前验是常数函数时最大后验估计与最大似然估计重合。
方法最大后验估计可以用以下几种方法计算:
解析方法,当后验分布的模能够用解析解方式表示的时候用这种方法。当使用共轭先验的时候就是这种情况。
通过如共扼积分法或者牛顿法这样的数值优化方法进行,这通常需要一阶或者导数,导数需要通过解析或者数值方法得到。
通过期望最大化算法的修改实现,这种方法不需要后验密度的导数。
尽管最大后验估计与 Bayesian 统计共享前验分布的使用,通常并不认为它是一种 Bayesian 方法,这是因为最大后验估计是点估计,然而 Bayesian 方法的特点是使用这些分布来总结数据、得到推论。Bayesian 方法试图算出后验均值或者中值以及posterior interval,而不是后验模。尤其是当后验分布没有一个简单的解析形式的时候更是这样:在这种情况下,后验分布可以使用Markov chain Monte Carlo技术来模拟,但是找到它的模的优化是很困难或者是不可能的。
计算MAP估计可以通过以下几种方式计算:
1、分析地,当后分布的模式可以以封闭形式给出时。 当使用共轭前体时就是这种情况。
2、通过数值优化,如共轭梯度法或牛顿法。 这通常需要一阶或二阶导数,必须通过分析或数值方法进行评估。
3、通过修改期望最大化算法。 这不需要后密度的导数。
4、通过使用模拟退火的蒙特卡罗方法。
评价虽然MAP估计只需要温和的条件就是贝叶斯估计的一个极限情况(在0-1损失函数下),但它一般不能很好地代表贝叶斯方法。 这是因为MAP估计是点估计,而贝叶斯方法的特征在于使用分布来总结数据和绘制推论:因此,贝叶斯方法倾向于报告后验均值或中值,以及可信区间。 这是因为这些估计量分别在平方误差和线性误差损失下是最优的 - 这更能代表典型的损失函数 - 并且因为后验分布可能没有简单的分析形式:在这种情况下,可以模拟分布 使用马尔可夫链蒙特卡罗技术,而优化以找到其模式可能是困难的或不可能的。
在许多类型的模型中,例如混合模型,后部可以是多模态的。在这种情况下,通常的建议是应该选择最高模式:这并不总是可行的(全局优化是一个难题),在某些情况下甚至不可能(例如在出现可识别性问题时)。此外,最高模式可能是大多数后验的不典型。
最后,与ML估计器不同,MAP估计在重新参数化下不是不变的。从一个参数化切换到另一个参数化涉及引入影响最大值位置的雅可比行列式1。
作为上述贝叶斯估计量(均值和中位数估计量)与使用MAP估计值之间差异的一个例子,考虑需要将输入x分类为正或负的情况(例如,贷款有风险或安全) 。假设关于正确的分类方法h1,h2和h3只有三种可能的假设,后验分别为0.4,0.3和0.3。假设给定一个新实例,x,h1将其分类为正数,而另外两个将其分类为负数。使用对正确分类器h1的MAP估计,x被分类为正,而贝叶斯估计器将对所有假设求平均并将x分类为负。
本词条内容贡献者为:
王伟 - 副教授 - 上海交通大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国