

预测稀疏分解(predictive sparse decomposition,PSD)是稀疏编码和参数化自编码器的混合模型。该模型由一个编码器f(x)和一个解码器g(h)组成,并且都是参数化的。在训练过程中,h由优化算法控制。
基本内容预测稀疏分解(predictive sparse decomposition,PSD)是稀疏编码和参数化自编码器的混合模型。参数化编码器被训练为能预测迭代推断的输出。该模型由一个编码器 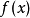 和一个解码器
和一个解码器  组成,并且都是参数化的。在训练过程中,
组成,并且都是参数化的。在训练过程中,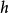 由优化算法控制。优化过程是最小化:1
由优化算法控制。优化过程是最小化:1
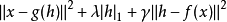
训练和稀疏编码相同,训练算法交替地相对和模型的参数最小化上述目标。相对 最小化较快,因为 提供的良好初始值以及损失函数将 约束在 附近。简单的梯度下降算法只需 10 步左右就能获得理想的 。
PSD 所使用的训练程序不是先训练稀疏编码模型,然后训练来预测稀疏编码的特征。 PSD 训练过程正则化解码器,使用 可以推断出良好编码的参数。1
应用预测稀疏分解是学习近似推断(learned approximate inference)的一个例子。PSD 能够被解释为通过最大化模型的对数似然下界训练有向稀疏编码的概率模型。PSD 被应用于图片和视频中对象识别的无监督特征学习,在音频中也有所应用。
在 PSD 的实际应用中,迭代优化仅在训练过程中使用。模型被部署后,参数编码器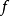 用于计算已经习得的特征。相比通过梯度下降推断
用于计算已经习得的特征。相比通过梯度下降推断 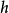 ,计算是很容易的。因为 是一个可微带参函数, PSD 模型可堆叠,并用于初始化其他训练准则的深度网络。 1
,计算是很容易的。因为 是一个可微带参函数, PSD 模型可堆叠,并用于初始化其他训练准则的深度网络。 1
不足预测性的稀疏分解模型训练一个浅层编码器网络,从而预测输入的稀疏编码。这可以被看作是自编码器和稀疏编码之间的混合。为模型设计概率语义是可能的,其中编码器可以被视为执行学成近似 MAP 推断。由于其浅层的编码器, PSD 不能实现我们在均值场推断中看到的单元之间的那种竞争。然而,该问题可以通过训练深度编码器实现学成近似推断来补救,如 ISTA 技术。 1
当训练集不足以捕获样本的变化时,PSD在实际应用中可能无法实现令人满意的性能。2
本词条内容贡献者为:
何星 - 副教授 - 上海交通大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国