

数据集增强主要是为了减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景。
方法常用的数据增强方法有:
旋转 | 反射变换(Rotation/reflection): 随机旋转图像一定角度; 改变图像内容的朝向;
翻转变换(flip): 沿着水平或者垂直方向翻转图像;
缩放变换(zoom): 按照一定的比例放大或者缩小图像;
平移变换(shift): 在图像平面上对图像以一定方式进行平移;
可以采用随机或人为定义的方式指定平移范围和平移步长, 沿水平或竖直方向进行平移. 改变图像内容的位置;
尺度变换(scale): 对图像按照指定的尺度因子, 进行放大或缩小; 或者参照SIFT特征提取思想, 利用指定的尺度因子对图像滤波构造尺度空间. 改变图像内容的大小或模糊程度;
对比度变换(contrast): 在图像的HSV颜色空间,改变饱和度S和V亮度分量,保持色调H不变. 对每个像素的S和V分量进行指数运算(指数因子在0.25到4之间), 增加光照变化;
噪声扰动(noise): 对图像的每个像素RGB进行随机扰动, 常用的噪声模式是椒盐噪声和高斯噪声;
颜色变化:在图像通道上添加随机扰动。
输入图像随机选择一块区域涂黑,参考《Random Erasing Data Augmentation》。
例子场景数据有800万张,365个类别,各个类别的样本数据非常不平衡,很多类别的样本数达到了4万张,有的类别样本数还不到5千张。这样不均匀的样本分布,给模型训练带来了难题1。
Label Shuffling平衡策略冠军土堆的Class-Aware Sampling方法的启发下,海康威视提出了Label Shuffling的类别平衡策略。具体步骤如下:
首先对原始图像列表按照标签顺序进行排序。
然后计算每个类别的样本数,并且得到样本最多的那个类别的样本数
根据这个最多的样本数,对每一类随机产生一个随机排列的列表
然后用每个类别的列表中的数对各自类别的样本数求余,得到一个索引值,从该类的图像中提取图像,生成该类的图像随机列表;
然后把所有类别的随机列表连在一起,做个Random Shuffling,得到最后的图像列表,用这个列表进行训练。
Label Smoothing策略Label Smoothing Regularization(LSR)就是为了缓解由label不够soft而容易导致过拟合的问题,使模型对预测less confident。LSR的方法原理:
假设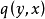 表示label
表示label  的真实分布;
的真实分布;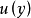 表示一个关于label ,且独立于观测样本
表示一个关于label ,且独立于观测样本 (与无关)的固定且已知的分布,通过下面公式(1)重写label y的分布:
(与无关)的固定且已知的分布,通过下面公式(1)重写label y的分布:
 (1)
(1)
其中, 属于[0,1]。把label 的真实分布与固定的分布按照
属于[0,1]。把label 的真实分布与固定的分布按照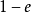 和
和 的权重混合在一起,构成一个新的分布。这相当于对label 中加入噪声,y值有e的概率来自于分布
的权重混合在一起,构成一个新的分布。这相当于对label 中加入噪声,y值有e的概率来自于分布 。为方便计算,一般服从简单的均匀分布,则
。为方便计算,一般服从简单的均匀分布,则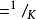 ,
,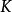 表示模型预测类别数目。因此,公式(1)表示成公式(2)所示:
表示模型预测类别数目。因此,公式(1)表示成公式(2)所示:
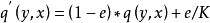 (2)
(2)
注意,LSR可以防止模型把预测值过度集中在概率较大类别上,把一些概率分到其他概率较小类别上。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国