

多任务学习(MTL)是一个很有前景的机器学习领域,通过使用包含在相关任务的监督信号中的领域知识来改善泛化性能。
引言利用历史数据中的有用信息来帮助分析未来数据的机器学习,通常需要大量有标签数据才能训练出一个优良的学习器。深度学习模型是一种典型的机器学习模型,因为这类模型是带有很多隐藏层和很多参数的神经网络,所以通常需要数以百万计的数据样本才能学习得到准确的参数。但是,包括医学图像分析在内的一些应用无法满足这种数据要求,因为标注数据需要很多人力劳动。在这些情况下,多任务学习(MTL)可以通过使用来自其它相关学习任务的有用信息来帮助缓解这种数据稀疏问题。
MTL 是机器学习中一个很有前景的领域,其目标是利用多个学习任务中所包含的有用信息来帮助为每个任务学习得到更为准确的学习器。我们假设所有任务(至少其中一部分任务)是相关的,在此基础上,我们在实验和理论上都发现,联合学习多个任务能比单独学习它们得到更好的性能。根据任务的性质,MTL 可以被分类成多种设置,主要包括多任务监督学习、多任务无监督学习、多任务半监督学习、多任务主动学习、多任务强化学习、多任务在线学习和多任务多视角学习。
多任务监督学习任务(可能是分类或回归问题)是根据训练数据集(包含训练数据实例和它们的标签)预测未曾见过的数据的标签。多任务无监督学习任务(可能是聚类问题)是识别仅由数据构成的训练数据集中的有用模式。多任务半监督学习任务与多任务监督学习类似,只是其训练集中不仅包含有标签数据,也包含无标签数据。多任务主动学习任务是利用无标签数据来帮助学习有标签数据,这类似于多任务半监督学习,其差异在于主动学习会选择无标签数据来主动查询它们的标签从而降低标注开销。多任务强化学习任务是选择动作以最大化累积奖励。多任务在线学习任务是处理序列数据。多任务多视角学习任务是处理多视角数据——其中每个数据实例都有多组特征。
MTL 可以看作是让机器模仿人类学习行为的一种方法,因为人类常常将一个任务的知识迁移到另一个相关的任务上。例如,根据作者自身经验,打壁球和打网球的技能可以互相帮助提升。与人类学习类似,(机器)同时学习多个学习任务是很有用的,因为一个任务可以利用另一个相关任务的知识。
MTL 也与机器学习的某些其它领域有关,包括迁移学习、多标签学习和多输出回归,但 MTL 也有自己不同的特点。比如说,类似于 MTL,迁移学习的目标也是将知识从一个任务迁移到另一个任务,但不同之处在于迁移学习希望使用一个或多个任务来帮助另一个目标任务,而 MTL 则是希望多个任务彼此助益。当多任务监督学习的不同任务使用了同样的训练数据时,这就变成了多标签学习或多输出回归。从这个意义上看,MTL 可以被看作是多标签学习和多输出回归的一种泛化。1
提出动机提出多任务学习的出发点是多种多样的:2
(1)从生物学来看,我们将多任务学习视为对人类学习的一种模拟。为了学习一个新的任务,我们通常会使用学习相关任务中所获得的知识。例如,婴儿先学会识别脸,然后将这种知识用来识别其他物体。
(2)从教学法的角度来看,我们首先学习的任务是那些能够帮助我们掌握更复杂技术的技能。这一点对于学习武术和编程来讲都是非常正确的方法。具一个脱离大众认知的例子,电影Karate Kid中Miyagi先生教会学空手道的小孩磨光地板以及为汽车打蜡这些表明上没关系的任务。然而,结果表明正是这些无关紧要的任务使得他具备了学习空手道的相关的技能。
(3)从机器学习的角度来看,我们将多任务学习视为一种归约迁移(inductive transfer)。归约迁移(inductive transfer)通过引入归约偏置(inductive bias)来改进模型,使得模型更倾向于某些假设。举例来说,常见的一种归约偏置(Inductive bias)是L1正则化,它使得模型更偏向于那些稀疏的解。在多任务学习场景中,归约偏置(Inductive bias)是由辅助任务来提供的,这会导致模型更倾向于那些可以同时解释多个任务的解。
定义定义 (多任务学习):给定 m 个学习任务,其中所有或一部分任务是相关但并不完全一样的,多任务学习的目标是通过使用这 m 个任务中包含的知识来帮助提升各个任务的性能。
基于这一定义,我们可以看到 MTL 有两个基本因素。
第一个因素是任务的相关性。任务的相关性是基于对不同任务关联方式的理解,这种相关性会被编码进 MTL 模型的设计中。
第二个因素是任务的定义。在机器学习中,学习任务主要包含分类和回归等监督学习任务、聚类等无监督学习任务、半监督学习任务、主动学习任务、强化学习任务、在线学习任务和多视角学习任务。因此不同的学习任务对应于不同的 MTL 设置。1
多任务监督学习多任务监督学习(MTSL)意味着 MTL 中的每个任务都是监督学习任务,其建模了从数据到标签的函数映射。
基于特征的 MTSL在这一类别中,所有 MTL 模型都假设不同的任务都具有同样的特征表示,这是根据原始特征学习得到的。根据这种共有的特征表示的学习方式,我们进一步将多任务模型分为了三种方法,包括特征变换方法、特征选择方法和深度学习方法。特征变换方法学习到的共有特征是原始特征的线性或非线性变换。特征选择方法假设共有特征是原始特征的一个子集。深度学习方法应用深度神经网络来为多个任务学习共有特征,该表征会被编码在深度神经网络的隐藏层中。1
基于参数的 MTSL基于参数的 MTSL 使用模型参数来关联不同任务的学习。根据不同任务的模型参数的关联方式,我们可将其分成 5 种方法,包括低秩方法、任务聚类方法、任务关系学习方法、脏方法(dirty approach)和多层次方法。具体而言,因为假设任务是相关的,所以参数矩阵 W 很可能是低秩的,这是低秩方法提出的动机。任务聚类方法的目标是将任务分成多个集群,并假设其中每个集群中的所有任务都具有同样的或相似的模型参数。任务关系学习方法是直接从数据中学习任务间的关系。脏方法假设参数矩阵 W 可以分解成两个分量矩阵,其中每个矩阵都由一种稀疏类型进行正则化。多层次方法是脏方法的一种泛化形式,是将参数矩阵分解成两个以上的分量矩阵,从而建模所有任务之间的复杂关系。1
基于实例的 MTSL这一类别的研究很少,其中 [61] 提出的多任务分布匹配方法是其中的代表。具体来说,它首先评估每个实例来自其自己的任务的概率和来自所有任务的混合的概率之比。在确定了此比率之后,这种方法会利用此比率针对每一个任务来加权所有任务的数据,并利用加权的数据来学习每一个任务的模型参数。3
多任务无监督学习不同于每个数据实例都关联了一个标签的多任务监督学习,多任务无监督学习的训练集仅由数据样本构成,其目标是挖掘数据集中所包含的信息。典型的无监督学习任务包括聚类、降维、流形学习(manifold learning)和可视化等,而多任务无监督学习主要关注多任务聚类。聚类是指将一个数据集分成多个簇,其中每簇中都有相似的实例,因此多任务聚类的目的是通过利用不同数据集中包含的有用信息来在多个数据集上同时执行聚类。3
多任务半监督学习在很多应用中,数据通常都需要很多人力来进行标注,这使得有标签数据并不很充足;而在很多情况下,无标签数据则非常丰富。所以在这种情况下,可以使用无标签数据来帮助提升监督学习的表现,这就是半监督学习。半监督学习的训练集由有标签和无标签的数据混合构成。在多任务半监督学习中,目标是一样的,其中无标签数据被用于提升监督学习的表现,而不同的监督学习任务则共享有用的信息来互相帮助。3
多任务主动学习多任务主动学习的设置和多任务半监督学习几乎一样,其中每个任务的训练集中都有少量有标签数据和大量无标签数据。但是不同于多任务半监督学习,在多任务主动学习中,每个任务都会选择部分无标签数据来查询一个 oracle 以主动获取其标签。因此,无标签数据的选择标准是多任务主动学习领域的主要研究重点。3
多任务强化学习受行为心理学的启发,强化学习研究的是如何在环境中采取行动以最大化累积奖励。其在很多应用上都表现出色,在围棋上击败人类的 AlphaGo 就是其中的代表。当环境相似时,不同的强化学习任务可以使用相似的策略来进行决策,因此研究者提出了多任务强化学习。3
多任务在线学习当多个任务的训练数据以序列的形式出现时,传统的 MTL 模型无法处理它们,但多任务在线学习则可以做到。3
多任务多视角学习在计算机视觉等一些应用中,每个数据样本可以使用不同的特征来描述。以图像数据为例,其特征包含 SIFT 和小波(wavelet)等。在这种情况下,一种特征都被称为一个视角(view)。多视角学习就是为处理这样的多视角数据而提出的一种机器学习范式。与监督学习类似,多视角学习中每个数据样本通常都关联了一个标签。多视角学习的目标是利用多个视角中包含的有用信息在监督学习的基础上进一步提升表现。多任务多视角学习是多视角学习向多任务的扩展,其目标是利用多个多视角学习问题,通过使用相关任务中所包含的有用信息来提升每个多视角学习问题的性能。3
深度学习中MTL模式参数的硬共享机制参数的硬共享机制是神经网络的多任务学习中最常见的一种方式4。一般来讲,它可以应用到所有任务的所有隐层上,而保留任务相关的输出层。硬共享机制降低了过拟合的风险。事实上,文献5证明了这些共享参数过拟合风险的阶数是N,其中N为任务的数量,比任务相关参数的过拟合风险要小。直观来将,这一点是非常有意义的。越多任务同时学习,我们的模型就能捕捉到越多任务的同一个表示,从而导致在我们原始任务上的过拟合风险越小。2

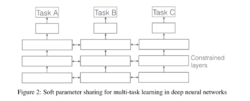
参数的软共享机制每个任务都由自己的模型,自己的参数。我们对模型参数的距离进行正则化来保障参数的相似。文献6使用L2距离正则化,而文献7使用迹正则化(trace norm)。用于深度神经网络中的软共享机制的约束很大程度上是受传统多任务学习中正则化技术的影响。2
MTL有效原因即使从多任务学习中获得归约偏置的解释很受欢迎,但是为了更好理解多任务学习,我们必须探究其深层的机制。大多数机制早在1998年被Caruana提出。为了便于说明,我们假设有两个相关的任务A与B,两者共享隐层表示F。2
(1)隐世数据增加机制。
多任务学习有效的增加了训练实例的数目。由于所有任务都或多或少存在一些噪音,例如,当我们训练任务A上的模型时,我们的目标在于得到任务A的一个好的表示,而忽略了数据相关的噪音以及泛化性能。由于不同的任务有不同的噪音模式,同时学习到两个任务可以得到一个更为泛化的表示。如果只学习任务A要承担对任务A过拟合的风险,然而同时学习任务A与任务B对噪音模式进行平均,可以使得模型获得更好表示F。
(2)注意力集中机制。
若任务噪音严重,数据量小,数据维度高,则对于模型来说区分相关与不相关特征变得困难。多任务有助于将模型注意力集中在确实有影响的那些特征上,是因为其他任务可以为特征的相关与不相关性提供额外的证据。
(3)窃听机制。对于任务B来说很容易学习到某些特征G,而这些特征对于任务A来说很难学到。这可能是因为任务A与特征G的交互方式更复杂,或者因为其他特征阻碍了特征G的学习。通过多任务学习,我们可以允许模型窃听(eavesdrop),即使用任务B来学习特征G。最简单的实现方式是使用hints8,即训练模型来直接预测哪些是最重要的特征。
(4)表示偏置机制。
多任务学习更倾向于学习到一类模型,这类模型更强调与其他任务也强调的那部分表示。由于一个对足够多的训练任务都表现很好的假设空间,对来自于同一环境的新任务也会表现很好,所以这样有助于模型展示出对新任务的泛化能力9。
(5)正则化机制。
多任务学习通过引入归纳偏置(inductive bias)起到与正则化相同的作用。正是如此,它减小了模型过拟合的风险,同时降低了模型的Rademacher复杂度,即拟合随机噪音的能力。
MTL共享内容大多数的多任务学习中,任务都是来自于同一个分布的。尽管这种场景对于共享是有益的,但并不总能成立。为了研发更健壮的多任务模型,我们必须处理那些不相关的任务。
早期用于深度学习的多任务模型需要预定义任务间的共享结构。这种策略不适合扩展,严重依赖于多任务的结构。早在1997年就已经提出的参数的硬共享技术在20年后仍旧是主流。尽管参数的硬共享机制在许多场景中有用,但是若任务间的联系不那么紧密,或需要多层次的推理,则硬共享技术很快失效。最近也有一些工作研究学习哪些可以共享,这些工作的性能从一般意义上将优于硬共享机制。此外,若模型已知,学习一个任务层次结构的容量也是有用的,尤其是在有多粒度的场景中。
一旦我们要做一个多目标的优化问题,那么我们就是在做多任务学习。多任务不应仅仅局限于将所有任务的知识都局限于表示为同一个参数空间,而是更加关注于如何使我们的模型学习到任务间本应该的交互模式。2
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国