

在概率统计理论中, 生成模型是指能够随机生成观测数据的模型,尤其是在给定某些隐含参数的条件下。它给观测值和标注数据序列指定一个联合概率分布。在机器学习中,生成模型可以用来直接对数据建模(例如根据某个变量的概率密度函数进行数据采样),也可以用来建立变量间的条件概率分布。条件概率分布可以由生成模型根据贝叶斯定理形成。
简介概率生成模型,简称生成模型(Generative Model),是概率统计和机器学习中的一类重要模型,指一系列用于随机生成可观测数据的模型1。生成模型的应用十分广泛,可以用来不同的数据进行建模,比如图像、文本、声音等。比如图像生成,我们将图像表示为一个随机向量X,其中每一维都表示一个像素值。假设自然场景的图像都服从一个未知的分布pr(x),希望通过一些观测样本来估计其分布。高维随机向量一般比较难以直接建模,需要通过一些条件独立性来简化模型。深度生成模型就是利用深层神经网络可以近似任意函数的能力来建模一个复杂的分布。方法:从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度;生成方法还原出联合概率分布,而判别方法不能;生成方法的学习收敛速度更快、即当样本容量增加的时候,学到的模型可以更快地收敛于真实模型;当存在隐变量时,扔可以用生成方法学习,此时判别方法不能用。
例如,香农 (1948) 给出了有一个英语双词频率表生成句子的例子。可以生成如“representing and speedily is an good”这种句子。一开始并不能生成正确的英文句子,但随着词频表由双词扩大为三词甚至多词,生成的句子也就慢慢的成型了。
判别模型在机器学习领域判别模型是一种对未知数据 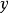 与已知数据
与已知数据  之间关系进行建模的方法。判别模型是一种基于概率理论的方法。已知输入变量
之间关系进行建模的方法。判别模型是一种基于概率理论的方法。已知输入变量  ,判别模型通过构建条件概率分布
,判别模型通过构建条件概率分布 预测
预测 。生成模型的定义与判别模型相对应:生成模型是所有变量的全概率模型,而判别模型是在给定观测变量值前提下目标变量条件概率模型。因此生成模型能够用于模拟(即生成)模型中任意变量的分布情况,而判别模型只能根据观测变量得到目标变量的采样。判别模型不对观测变量的分布建模,因此它不能够表达观测变量与目标变量之间更复杂的关系。因此,生成模型更适用于无监督的任务,如分类和聚类。如果观测数据是由生成模型中采样的,那么最大化数据似然概率是一个常见的方法。但是,大部分统计模型只是近似于真实分布,如果任务的目标是在已知一部分变量的值的条件下,对另一部分变量的推断,那么可以认为这种模型近似造成了一些对于当前任务来说不必要的假设。在这种情况下,使用判别模型对条件概率函数建模可能更准确,尽管具体的应用细节会最终决定哪种方法更为适用。
。生成模型的定义与判别模型相对应:生成模型是所有变量的全概率模型,而判别模型是在给定观测变量值前提下目标变量条件概率模型。因此生成模型能够用于模拟(即生成)模型中任意变量的分布情况,而判别模型只能根据观测变量得到目标变量的采样。判别模型不对观测变量的分布建模,因此它不能够表达观测变量与目标变量之间更复杂的关系。因此,生成模型更适用于无监督的任务,如分类和聚类。如果观测数据是由生成模型中采样的,那么最大化数据似然概率是一个常见的方法。但是,大部分统计模型只是近似于真实分布,如果任务的目标是在已知一部分变量的值的条件下,对另一部分变量的推断,那么可以认为这种模型近似造成了一些对于当前任务来说不必要的假设。在这种情况下,使用判别模型对条件概率函数建模可能更准确,尽管具体的应用细节会最终决定哪种方法更为适用。
典型模型高斯混合模型(Gaussian Mixture Model)
为单一高斯概率密度函数的延伸,用多个高斯概率密度函数(正态分布曲线)精确地量化变量分布,是将变量分布分解为若干基于高斯概率密度函数(正态分布曲线)分布的统计模型。
隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。在正常的马尔可夫模型中,状态对于观察者来说是直接可见的。这样状态的转换概率便是全部的参数。而在隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量则是可见的。每一个状态在可能输出的符号上都有一概率分布。因此输出符号的序列能够透露出状态序列的一些信息。
朴素贝叶斯分类器
在机器学习中,朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器。
朴素贝叶斯自20世纪50年代已广泛研究。在20世纪60年代初就以另外一个名称引入到文本信息检索界中, 并仍然是文本分类的一种热门(基准)方法,文本分类是以词频为特征判断文件所属类别或其他(如垃圾邮件、合法性、体育或政治等等)的问题。通过适当的预处理,它可以与这个领域更先进的方法(包括支持向量机)相竞争。它在自动医疗诊断中也有应用。
朴素贝叶斯分类器是高度可扩展的,因此需要数量与学习问题中的变量(特征/预测器)成线性关系的参数。最大似然训练可以通过评估一个封闭形式的表达式来完成,只需花费线性时间,而不需要其他很多类型的分类器所使用的费时的迭代逼近。
在统计学和计算机科学文献中,朴素贝叶斯模型有各种名称,包括简单贝叶斯和独立贝叶斯。所有这些名称都参考了贝叶斯定理在该分类器的决策规则中的使用,但朴素贝叶斯不(一定)用到贝叶斯方法;《Russell和Norvig》提到朴素贝叶斯有时被称为贝叶斯分类器,这个马虎的使用促使真正的贝叶斯论者称之为傻瓜贝叶斯模型。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国