

维奥拉-琼斯目标检测框架(Viola–Jones object detection framework)是第一种可以实时处理并给出很好的物体检出率的物体检测的方法,由保罗·维奥拉和迈克尔·琼斯于2001年提出12。值得一提的是,提出该方法的论文于2011年的CVPR会议上评为龙格-希金斯奖。虽然它可以被训练来寻找多种物体,它的主要应用还是在解决人脸检测方面。这个方法在OpenCV中被实现为cvHaarDetectObjects()。
框架的组成特征类型和进化检测框架使用的特征涉及到图像上矩形区域的像素和,就是哈尔特征,而这些特征以前多用于基于图像的物体检测领域3。然而,由于维奥拉和琼斯使用的特征包含不止一个矩形区域,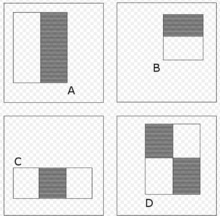 就显得更为复杂。如图1所示的图像是四种不同的特征。每一个特征的值就是白色矩形的像素值之和与深色矩形像素值之和的差值。所以,相比那些复杂的方向可变滤波器(steerable filters),这种矩形特征是十分原始的。虽然他们对水平和竖直方向比较敏感,它们的反馈是比较粗粒度的。最后,使用一个称为积分图的数据结构,矩形特征的计算可以在常数时间内完成,也就使得它们很具有速度优势。例如,2矩形特征需要六次查询,3矩形特征需要八次,而4矩形特征则需要九次。
就显得更为复杂。如图1所示的图像是四种不同的特征。每一个特征的值就是白色矩形的像素值之和与深色矩形像素值之和的差值。所以,相比那些复杂的方向可变滤波器(steerable filters),这种矩形特征是十分原始的。虽然他们对水平和竖直方向比较敏感,它们的反馈是比较粗粒度的。最后,使用一个称为积分图的数据结构,矩形特征的计算可以在常数时间内完成,也就使得它们很具有速度优势。例如,2矩形特征需要六次查询,3矩形特征需要八次,而4矩形特征则需要九次。
学习算法选择哪些特征作为最终用于分类的过程十分漫长。例如,在一个24x24像素的窗口内,一共有45,396个可能的特征。因此,目标检测框架使用了一个称为AdaBoost的机器学习算法来选择特征并训练分类器。
级联架构在学习阶段强分类器的进化可以很快完成,但是还不够进行实时计算。基于这个原因,强分类器按照复杂性的顺序被组成一种级联结构,每一个后续分类器的训练样本都是通过了之前所有分类器的样本。如果级联的任何一个分类器拒绝了一个检测窗口,则该窗口不再进行任何的进一步检测。因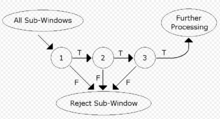 此,这种级联结构类似于一种退化的树。在人脸检测中,第一级分类器(也称为attentional operator)只使用了2个特征,就达到了将近0%的漏检率(false negative rate)1以及40%的误检率(false positive rate)[5]。这一个分类器就可以简单的过滤掉要检测窗口的一半。
此,这种级联结构类似于一种退化的树。在人脸检测中,第一级分类器(也称为attentional operator)只使用了2个特征,就达到了将近0%的漏检率(false negative rate)1以及40%的误检率(false positive rate)[5]。这一个分类器就可以简单的过滤掉要检测窗口的一半。
这个级联结构对每一个分类器的性能有着有趣的影响。由于每一个分类器是否使用完全取决于它的前驱,因此,整体的误检率是:
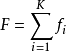
类似地,检测率(detection rate)是:
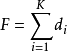
因此,对于每一个分类器的检测效果的要求是惊人的低。例如,对于一个32层的级联分类器,为了达到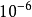 的误检率,每一个分类器只需要达到65%的误检率。同时,为了满足系统的检测率,对于单个分类器的检测率要求很高。例如,为了达到整体90%的检测率,每一个分类器的检测率需要达到99.7%。
的误检率,每一个分类器只需要达到65%的误检率。同时,为了满足系统的检测率,对于单个分类器的检测率要求很高。例如,为了达到整体90%的检测率,每一个分类器的检测率需要达到99.7%。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国