

性能度量(performance measure)是衡量模型泛化能力的评价标准,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。
最常见的性能度量查准率、查全率与F1在异常检测的机器学习模型中,如图1所示,1表示检测为正常(positive),0表示检测为异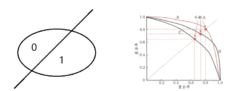 常(negative)。那么,查准率(precision)是预测为正例的样本中预测正确的概率;查全率(recall,亦称召回率)是正例样本被预测正确的概率。顾名思义,对于检测正常(检测1)的查准率越大,检测为正常的样本越可信;查全率越大,检测出来的正常样本越多。对于检测异常(检测0)也是一个道理。以信息检索为例,根据检索结果中感兴趣词条和不感兴趣词条可以计算precision,根据检索结果中感兴趣词条和所有感兴趣词条数目(包括未检索出来的) 可以计算recall1。
常(negative)。那么,查准率(precision)是预测为正例的样本中预测正确的概率;查全率(recall,亦称召回率)是正例样本被预测正确的概率。顾名思义,对于检测正常(检测1)的查准率越大,检测为正常的样本越可信;查全率越大,检测出来的正常样本越多。对于检测异常(检测0)也是一个道理。以信息检索为例,根据检索结果中感兴趣词条和不感兴趣词条可以计算precision,根据检索结果中感兴趣词条和所有感兴趣词条数目(包括未检索出来的) 可以计算recall1。
F1度量F1是基于precision与recall的调和平均(harmonic mean):
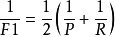
混淆矩阵关于2分类的混淆矩阵如图2所示。True positive(TP)中P是指预测为正例,T是指预 测正确; False negative(FN)中N是指预测为反例,F是指预测错误。
测正确; False negative(FN)中N是指预测为反例,F是指预测错误。
ROC与AUC学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,若将这些实值排序,则排序的好坏决定了学习器的性能高低。ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。
TPR与FPR下表说明P、R与TPR、FPR的对比。同时,我以判断西瓜好坏为例(正例是预测为好瓜,反例是预测为坏瓜),简要说明其作用。
|| ||
假设,我是买家,我想要买一个好瓜。那么,我要考虑学习器的准确率,以保证买到的更可能是好瓜。
假设,我是商户,我想把一批西瓜分成好坏两类 方便定不同的价格。那么,我要考虑学习器的查全率,以保证好瓜都能卖高价。
假设,我是水果店HR,我想招一个员工来做 西瓜分好坏的工作。那么,我要考虑员工(学习器)的真正例率越高越好,但是挑出的好瓜越多,就会使坏瓜被误判为好瓜的错误越多(假正例率越高),顾客就会不满意。
本词条内容贡献者为:
王沛 - 副教授、副研究员 - 中国科学院工程热物理研究所
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国