

野值点为采样值的变化梯度在实际系统中一个采样周期内无法达到的点。在数学领域,野值点被记为第一类奇异点。
一般认为,若设 D={Y(T1),...Y(TN)} 为对动态目标的一序列跟踪测t数据所组成的集合,D中严重偏离大部分数据所呈现变化趋势的一小部分数据点称为野值点。
野值点伪数据的特性是(1)产生是随机的,在一次试验任务中以小概率发生,一般常见于初始段和目标刚刚消失后几秒到十几秒内;
(2)在某时刻伪数据相对于其它跟踪上目标设备的测量数据可以看作是离群值;
(3)由于伪数据在(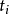 ,
,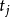 )(i
)(i
(4)当i=j时就是野值点.可见,伪数据不同于异常数据,有伪数据参与实时解算的结果在一段时间内严重偏离真实结果,且由于其具有确定性趋势滤波器一般是无法滤除伪数据的,同时,伪数据隐蔽性强,用常规方法不易识别.
**标题:**图1位置估计误差及标出的野值点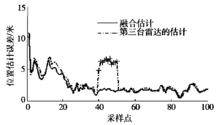 **篇名:**多传感器目标跟踪的实时剔野方法
**篇名:**多传感器目标跟踪的实时剔野方法
**说明:**图1给出了剔野后融合估计和用第三台雷达的跟踪数据结合反馈信息给出的估计的残差图的比较及标记出的野值点,由图中可以看出,虽然有准确的域1。
野值点的建模什么是野值?在探索性数据分析和数据处理领域中,野值又称异常值(Outliers)。其定义一直不很明确,持不同态度的应用统计学家对其定义也不一样。对几种常用的定义进行过较为详尽的剖析和比较。建议采用野值点的定义为:集合D中严重偏离大部分数据所呈现趋势的小部分数据点。这一定义强调主体数据所呈现的“趋势” ,以偏离数据集合主体的变化趋势为判别异常数据依据,并明确指出野值在集合D中只占小部分(即最多不超过一半),这从直观上是合理的。本定义不但可以覆盖简单随机抽样情形,包括Edeworth (1887)的定义,而且也覆盖了时间序列及随机系统中的野值数据情形,具有较为广泛的适应性。
野值点的成因分析采样数据集合中出现野值点的原因很多。就航天靶场试验的外测数据而言,产生野值主要有如下几个方面的原因:
(1)操作和记录时的过失,以及数据复制和计算处理时所出现的过失性错误。由此产生的误差称为过失误差(Gross Error)。
(2)采样环境的变化。取样母体的突然改变使得部分数据与原先样本的模型不符合,例如大地测量时地震或其它突变现象的出现、雷达跟踪时应答机工作状态的不稳定、靶场试验时飞行目标的变轨与各级关机点附近的取样,等等。
(3)实际采样数据中也可能出现另一类异常数据,它既不是来自操作和处理的过失也不是由突发性强影响因素导致的,而是某些服从长尾分布(long-tailed distribution)的随机变量(例如,服从t分布的随机变量)作用的结果。
野值点的分类工程采样数据中出现的野值点,比较常见的有如下几种类型:
(1)离群点又称跳点,是统计诊断领域中研究得最多也比较成熟的一类。简单随机抽样情形下,野值点主要表现为离群点。
(2)孤立型野值 它的基本特点是,某一采样时刻ti处的测量数据是否为野值与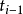 及
及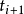 时刻数据的质量无必然联系。而且,比较常见的是当
时刻数据的质量无必然联系。而且,比较常见的是当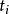 时刻的测量数据呈现异常时,在ti时刻的一个邻域内(如
时刻的测量数据呈现异常时,在ti时刻的一个邻域内(如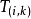 = {
= { ,… ,
,… ,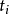 ,…
,…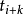 }等时刻)采样数据质量是好的,即野值点的出现是孤立的。母体不相依情形下,动态测量数据中孤立(isolated)异常值的出
}等时刻)采样数据质量是好的,即野值点的出现是孤立的。母体不相依情形下,动态测量数据中孤立(isolated)异常值的出
现也是比较普遍的情形之一。
(3)野值斑点 简称斑点(Patchy),是指成片出现的异常数据。它的基本特征是,在 时刻出现的野值,也可能带动y( -p+ 1),… , y( )均严重偏离真值。雷达跟踪高仰角目标的测量数据序列中,野值斑点的出现是比较常见的故障现象2。
野值点的统计诊断对于简单随机抽样情况下野值点的识别,孤立野值的诊断问题,也已经有大量的研究成果可供采用;对于多个野值点(特别是斑点型野值)的诊断与处理,因涉及到误差的前后相依性,见诸文献的成功的处理方法或程序尚不多见。
考虑到斑点型野值点统计诊断的技术难度和工程实用价值,本文将对此进行一些初步的探索和研究。本文的基本想法是,将长弧段测量数据集合中野值点的诊断和处理工作分成三个阶段:
①容错处理:构造一条稳健的“柱心”轨线;
②可疑点的筛选:通过实测数据与该“柱心”轨线的比较,初步确定出可能包含野值点个数s及其所在位置(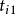 ,… ,
,… ,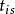 );
);
③统计诊断:构造检验统计量和检验门限,进一步核实②中所确定的s个测量数据确实为异常数据.
本词条内容贡献者为:
杜强 - 高级工程师 - 中国科学院工程热物理研究所
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国