

盲信号分离最早由Herault和Jutten在1985年提出,指的是从多个观测到的混合信号中分析出没有观测的原始信号。通常观测到的混合信号来自多个传感器的输出,并且传感器的输出信号独立性(线性不相关)。盲信号的“盲”字强调了两点:1)原始信号并不知道;2)对于信号混合的方法也不知道。
简介从字面意思理解,信号分离就是从接收到的混合信号(典型情况下是感兴趣信号+干扰+噪声)中分别分离或恢复出原始源信号。信号分离是信号处理中的一个基本问题。各种时域滤波器、频域滤波器、空域滤波器或码域滤波器都可以看作是一种信号分离器,完成信号分离任务。只不过这时的“分离”仅仅是分离出需要的感兴趣的信号而已,与前面讲的“分离”稍有不同。由此可见,信号分离是许多信号处理共性的体现。在已知源信号和传输通道的先验知识时,上述通过滤波的信号处理能够在一定程度上完成信号分离的任务。然而,在没有源信号和传输通道先验信息时,通过滤波的方法根本就无法完成信号分离的任务,必须通过盲信号分离技术来解决。盲信号分离也可以称为盲源分离(BSS,Blind Signal/Source Separation),其含义是在不知道源信号及信号混合参数的情况下,仅根据观测到的混合信号估计源信号。独立分量分析(ICA,Independent Component Analysis)是为了解决盲信号分离问题而逐渐发展起来的一种新技术。盲信号分离大部分都采用独立分量分析的方法,即将接收到的混合信号按照统计独立的原则通过优化算法分解为若干独立分量,这些独立分量作为源信号的一种近似估计。事实上,盲信号分离中要处理的问题在数学上是欠定的,因此结果不可能只有一个1,即分离结果存在两个不确定性:分离结果排列顺序不确定、分离结果幅度不确定。由于要传送的信息往往包含在信号波形中,因此这两个不确定性并不影响在实际中的应用。
问题基本描述如果可以对信号混合的方式直接建模,当然是最好的方法。但是,在盲信号分离中我们并不知道,信号混合的方式,所以,只能采用统计的方法。算法做出了如下的假定:具有 m个独立的信号源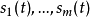 和
和 个独立的观察量
个独立的观察量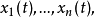 观察量和信号源具有如下的关系
观察量和信号源具有如下的关系
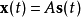
其中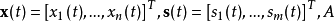 是一个
是一个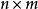 的系数矩阵,原问题变成了已知
的系数矩阵,原问题变成了已知 和
和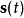 的独立性,求对
的独立性,求对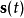 的估计问题。假定有如下公式
的估计问题。假定有如下公式
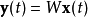
其中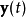 是对
是对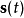 的估计,W是一个
的估计,W是一个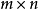 系数矩阵,问题变成了如何有效的对矩阵W做出估计。
系数矩阵,问题变成了如何有效的对矩阵W做出估计。
问题的基本假设如下:1)各源信号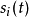 均为零均值信号,实随机变量,信号之间统计独立。如果源信号
均为零均值信号,实随机变量,信号之间统计独立。如果源信号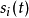 的概率密度为
的概率密度为 则
则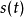 的概率密度为:
的概率密度为: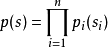 。2)源信号数目
。2)源信号数目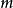 小于等于观察信号数目
小于等于观察信号数目 ,即
,即 。混合矩阵
。混合矩阵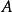 是一个
是一个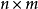 的矩阵。假定
的矩阵。假定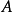 满秩。3)源信号中只允许有一个高斯分布,当多于一个高斯分布时,源信号变得不可分。
满秩。3)源信号中只允许有一个高斯分布,当多于一个高斯分布时,源信号变得不可分。
自然梯度法的计算公式为: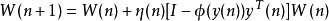
其中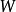 为我们需要估计的矩阵。
为我们需要估计的矩阵。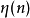 为步长
为步长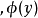 是一个非线性变换,比如
是一个非线性变换,比如 ,实际计算时
,实际计算时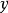 为一个
为一个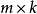 矩阵,
矩阵,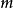 为原始信号个数,
为原始信号个数,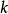 为采样点个数。算法基本步骤为:
为采样点个数。算法基本步骤为:
1)初始化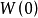 为单位矩阵
为单位矩阵
2)循环执行如下的步骤,直到 与
与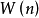 差异小于规定值
差异小于规定值 (计算矩阵差异的方法可以人为规定),有时候也人为规定迭代次数
(计算矩阵差异的方法可以人为规定),有时候也人为规定迭代次数
3)利用公式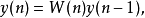 (其中
(其中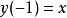 )
)
4)利用公式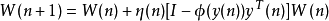
发展盲分离的真正进展是在20世纪80年代后期,先驱性的工作主要由Jutten和Herault在1986年完成:他们提出一种自适应的算法,完成了两个混迭源信号的分离。后来,Jutten,Herault,Comon,Sorouchyari等人于1991年在“ SignalProcessing”上发表了关于盲源分离的3篇经典文章,标志着盲分离问题研究获重大进展。与此同时,L.Tong等人于1991年对盲分离问题的可辨识性进行了初步研究,直到1996年曹希仁才彻底解决了盲分离的可解性条件。1994年,Comon系统地分析了瞬时盲信号分离问题,同时明确地引入独立分量分析(ICA)的概念,证明了只要恢复出混合信号中各个信号之间的相互独立性,就可以完成对源信号的分离。可以说,Comon的工作实际上使得对盲信号分离算法的研究变成了对独立分量分析的代价函数以及其优化算法的研究,使得以后的算法设计开始有了明确的理论依据。之后,涌现了一大批优秀的盲分离算法。A.J.Bell和T.J.Sejnowski于1995年提出了信息最大化法(Informax),T.Lee于1999年对此算法进行了改进(ExInformax);J.F.Cardoso于1996年提出了非线性PCA算法,并于1997年提出了最大似然算法。Amari于1998年提出了基于自然梯度的互信息最小算法,降低了算法计算量。Hyvarinen和Oja于1997年提出了盲分离中的定点算法FastICA,为进一步的实际应用打下了坚实基础。进入新世纪后,随着基本盲分离理论的逐渐成熟,越来越多的学者投入到扩展的盲分离问题的研究中,促进了含噪盲分离、欠定盲分离、卷积盲分离及非线性盲分离等的发展。在此基础上,相关的理论总结和专著不断涌现,进一步促进了学科的发展。“ Proceedings of IEEE” 1998年10月的论文集是盲信号处理专辑,Haykin,Hyvarinen,Cichocki等人相继出版了盲信号分离方面的专著。
基于统计信息方法分类自从Herault和Jutten的开创性工作以来,人们在这一领域进行了大量的研究工作,从不同角度提出了很多有效的盲分离算法。为了更好地理解并比较这些算法的原理与特点,根据一定的原则对它们进行分类是必要的。根据所用BSS的统计信息分类通常情况下,根据算法所依赖的源信号的统计信息,盲源信号分离算法可以分为如下三类:
基于信息论或似然估计的盲分离算法
这类算法以信息论为基础,判断信号分离的准则是分离系统输出信号的统计独立性最大化(互信息最小化、负熵最大化等)。这类算法除了要求源信号间相互独立外,还要求源信号中最多只能包含一个高斯信号。Cardoso等人证明,似然估计算法等价于信息论算法,因此可以把似然估计算法与信息论算法归到同一类中。基于信息论的典型算法有Amari的基于神经网络的自然梯度算法,Imformax算法等。此外,非线性算法也归到此类。虽然非线性方法与信息论及似然估计方法的出发点不同,但它们在算法上很相似,而且都用非线性神经网络实现。
基于信息论的盲分离算法通常都是自适应在线学习算法。这类算法的不足之处在于非线性激励函数与信号的统计分布特性(是亚高斯分布还是超高斯分布)有关。当源信号中同时存在亚高斯信号和超高斯信号时会带来麻烦。解决的办法有两种,其一是自适应地估计激励函数的类型,然后在给定的激励函数中选择合适的函数方法。另一种方法是对源信号的概率密度函数进行Edegworth或Gram Charlier展开,从而把非线性激励函数表示为分离信号各阶累积量的函数,并自适应地估计这些统计量。基于信息论的BSS方法通常具有较好的稳定性和收敛性。
基于二阶统计量的盲分离算法
这类算法也称为去相关算法。这类算法要求源信号间具有统计不相关性。此外,还要求源信号具有非白性或非平稳性。换言之,去相关算法不能分离统计独立的、平稳的白噪声过程(无论其概率分布如何)。去相关算法的主要优点是算法比较简单,并具有较好的稳定性,适用于具有任何概率分布的源信号。在二阶矩理论框架下,要想完整描述一个非白且非平稳的随机过程,必须用它的二维自相关函数。从盲信号分离角度来看,源信号的非白性与非平稳性具有等价性2。
基于高阶统计量(HOS)的盲分离算法
在盲信号分离领域,HOS算法占有重要地位。事实上,BSS算法的早期工作是从高阶统计量算法似一网络开始的。这类算法利用源信号的高阶统计量的性质来分离信号。最常用的是信号四阶累积量,也有人用信号的三阶累积量来分离信号。这类算法除了要求源信号具有统计独立性外,源信号中最多只能有一个高斯信号,即利用源信号的非高斯性。而对于源信号的非白特性及非平稳特性没有做任何考虑。因此可以说,HOS算法可以用来分离任何统计独立的非高斯信号或准确地说,不多于一个高斯信号。
独立成分分析统计学中,独立成分分析或独立分量分析(Independent components analysis,缩写:ICA) 是一种利用统计原理进行计算的方法。它是一个线性变换。这个变换把数据或信号分离成统计独立的非高斯的信号源的线性组合。独立成分分析是盲信号分离(Blind source separation)的一种特例。独立成分分析的最重要的假设就是信号源统计独立。这个假设在大多数盲信号分离的情况中符合实际情况。即使当该假设不满足时,仍然可以用独立成分分析来把观察信号统计独立化,从而进一步分析数据的特性。独立成分分析的经典问题是“鸡尾酒会问题”(cocktail party problem)。该问题描述的是给定混合信号,如何分离出鸡尾酒会中同时说话的每个人的独立信号。当有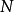 个信号源时,通常假设观察信号也有个(例如个麦克风或者录音机)。该假设意味着混合矩阵是个方阵,即
个信号源时,通常假设观察信号也有个(例如个麦克风或者录音机)。该假设意味着混合矩阵是个方阵,即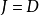 ,其中
,其中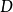 是输入数据的维数,
是输入数据的维数,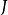 是系统模型的维数。对于
是系统模型的维数。对于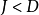 和
和 的情况,学术界也分别有不同研究。独立成分分析并不能完全恢复信号源的具体数值,也不能解出信号源的正负符号、信号的级数或者信号的数值范围。独立成分分析是研究盲信号分离(blind signal separation)的一个重要方法,并且在实际中也有很多应用。
的情况,学术界也分别有不同研究。独立成分分析并不能完全恢复信号源的具体数值,也不能解出信号源的正负符号、信号的级数或者信号的数值范围。独立成分分析是研究盲信号分离(blind signal separation)的一个重要方法,并且在实际中也有很多应用。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国