

**邻里成分分析(Neighbourhood components analysis,Nca)**是一种监督式学习的方法,根据一种给定的距离度量算法对样本数据进行度量,然后对多元变量数据进行分类。在功能上其和k近邻算法的目的相同,直接利用随即近邻的概念确定与测试样本临近的有标签的训练样本。
定义邻里成分分析是一种距离度量学习方法,其目的在于通过在训练集上学习得到一个线性空间转移矩阵,在新的转换空间中最大化平均留一(LOO)分类效果。该算法的关键是与空间转换矩阵相关的的一个正定矩阵A,该矩阵A可以通过定义A的一个可微的目标函数并利用迭代法(如共轭梯度法、共轭梯度下降法等)求解得到。该算法的好处之一是类别数K可以用一个函数f(确定标量常数)来定义。因此该算法可以用来解决模型选择的问题。1
解释说明为了定义转换矩阵A,我们首先定义一个在新的转换矩阵中表示分类准确率的目标函数,并且尝试确定A使得这个目标函数最大化。
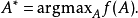
留一分类对一个单一的数据点进行类别预测时,我们需要考虑有一种给定的距离度量确定的K个最近邻居,根据k个近邻的类别标签投票得到该样本的类别。这就是留一(Loo)分类算法。但是对所有数据集进行一个线性空间变换之后,新空间中的同一样本的最近邻居集可能跟原空间的最近邻居集有很大差别。特别的,为了平滑A中元素的变化,我们可以使该样本的最近邻居集离散化,也就是说任意一个基于一个点的最近邻居集的目标函数f都是离散的,因此也是不连续的。
解决方法我们可以用一种受随机梯度下降法算法的启示得到的方法解决该问题。在新的转换空间中,我们并不是对每个样本点用留一分类方法求取k个最近邻居,而是在新空间中考虑整个数据集作为随机最近邻居。我们用一个平方欧氏距离函数来定义在新的转换空间中的留一数据点与其他数据的距离,该函数定义如下:
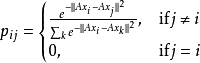
输入点i的分类准确率是与其相邻的最近邻居集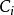 的分类准确率:
的分类准确率: 其中
其中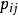 是j是i的最近邻居的概率。 定义用全局数据集作为随机最近邻的留一分类方法确定的目标函数如下:
是j是i的最近邻居的概率。 定义用全局数据集作为随机最近邻的留一分类方法确定的目标函数如下:
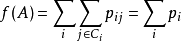
由随机近邻理论知,与单一样本点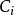 的同类别的在随机近邻域样本点j可以表示为:
的同类别的在随机近邻域样本点j可以表示为:
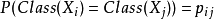 。因此,单一样本点i的预测类别是随机近邻集中其他样本类别的某种组合,其准确率与随机近邻域中与i同类别的y所占的比例有关。 因此,目标函数可以更好的选为:
。因此,单一样本点i的预测类别是随机近邻集中其他样本类别的某种组合,其准确率与随机近邻域中与i同类别的y所占的比例有关。 因此,目标函数可以更好的选为:
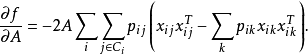
这里用到了连续梯度下降算法。
目标函数优化最大化函数f(.)相当于最小化预测的类分布和真正的类分布之间的差距,即使两者更接近。故目标函数和梯度可以重新写作:
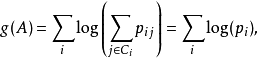
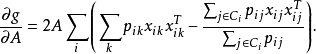
在实际应用中运用此方法得到优化的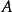 与之前的方法得到的有相似的预测结果。2
与之前的方法得到的有相似的预测结果。2
历史和背景邻里成分分析是由Jacob Goldberger, Sam Roweis, Ruslan Salakhudinov和Geoff Hinton 等人在2004年在多伦多大学计算机系创建的。3
相关研究和理论Cluster analysis
K-Nearest Neighbours
Spectral clustering
本词条内容贡献者为:
李嘉骞 - 博士 - 同济大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国