

有限信息最大似然法(LIML)是求过度识别方程式的结构参数的一致估计量的一种单方程估计方法。用它来估计方程时,通常先将结构式方程化为简单式方程,然后求结构式参数和简化式参数的关系,建立似然函数,最后求出参数的有限信息最大似然估计量。此方法得到的参数估计量是有偏的,但是一致的1。
基本介绍有限信息最大似然法指在只考虑所估计方程的约束的前提下,用最大似然法估计结构方程的参数。有限信息最大似然法是一种单方程估计法,它适用于过度识别的方程系统。这种方法通常是先将结构式方程化为简化式方理,然后求结构式参数和简化式参数的关系,建立似然的数,最后求似然函数在约束条件下的极大似然值。
有限信息最大似然法,可以说是FIML的简化。它只考虑部分结构式所提供的有限信息,然后利用最大似然法。它属于估计单一结构式参数的又一方法。所得估计量具有一致性。随机项满足正态分布的话则具有渐近有效的大样本特性。在计算上比FIML简单些,但仍然较繁杂。
相关分析有限信息最大似然法是对联立方程式体系中的每一个方程式运用最大似然法求参数估计值的一种方法。在采用这一方法的时候,是将有关包含于方程式体系中的先决变量的信息作为约束条件,在此基础上进行最大似然估计。
这里,先决变量包括先决内生变量和外生变量。
现在,在联立方程式体系中使用k个先决变量,而有p个先决变量存在于想要估计的个别方程式之中( ),因此,想要估计的方程式里没有包含的先决变量就有(k-p)个。在这种场合。可把这(k-p)个先决变量的参数解释为“0”。这就叫做“零系数约束”。(实际上,联立方程式体系里也包含了内生变量是相互关连的这一信息。但在有限信息最大似然法的场合,却无视这点。在这个意义上来说,并没有完全利用该体系所具有的全部信息。这就是“有限信息”的来由)。
),因此,想要估计的方程式里没有包含的先决变量就有(k-p)个。在这种场合。可把这(k-p)个先决变量的参数解释为“0”。这就叫做“零系数约束”。(实际上,联立方程式体系里也包含了内生变量是相互关连的这一信息。但在有限信息最大似然法的场合,却无视这点。在这个意义上来说,并没有完全利用该体系所具有的全部信息。这就是“有限信息”的来由)。
为了理解有限信息最大似然法,我们稍梢改变一下思路,导入“最小方差比”这一概念。
现在,假定想估计的方程式如下:
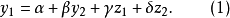
式中, 表示内生变量,
表示内生变量,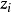 表示先决变量。
表示先决变量。
这里将对两种情形加以比较。一种情形是将内生变量的线性组合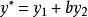 对体系内的所有先决变量进行回归,另一种情形是将仅对方程式所含的先决变量
对体系内的所有先决变量进行回归,另一种情形是将仅对方程式所含的先决变量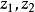 进行回归。如果前提是该方程仅含
进行回归。如果前提是该方程仅含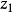 与
与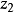 (其它先决变量的参数为0:零系数约束)的先验判断是正确的,则上述两种场合下的方程式之解释能力不会有多大差别(就是说,即使把与之外的先决变量
(其它先决变量的参数为0:零系数约束)的先验判断是正确的,则上述两种场合下的方程式之解释能力不会有多大差别(就是说,即使把与之外的先决变量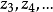 也加到解释变量之中,也不能提高方程式的解释能力)。 ·
也加到解释变量之中,也不能提高方程式的解释能力)。 ·
于是,可以考虑方差比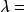 用与回归
用与回归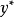 时的残差之方差/用全部先决变量回归时的残差之方差,并决定的权重和的参数,以使
时的残差之方差/用全部先决变量回归时的残差之方差,并决定的权重和的参数,以使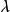 为最小(这与在认为
为最小(这与在认为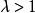 的情况下使接近于
的情况下使接近于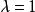 的场合是一致的)。
的场合是一致的)。
这样求得的估计量就叫做“最小方差比估计量”。这种估计量在结果上与用有限信息最大似然法求得的“有限信息最大似然估计量”是一致的。
另外,有限信息最大似然估计量是一致估计量,在数据充分多的场合,这一估计量与用二阶段最小二乘法求得的估计量是一致的2。
本词条内容贡献者为:
刘军 - 副研究员 - 中国科学院工程热物理研究所
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国