

查询策略选择的重要性
由于不同的查询策略通信时间相差很大,达数个量级,因此查询策略的选择尤为重要。一个好的查询策略应该使数据的传输量和通信次数量少,以减少数据传输和通信的时间,从而减少查询的总代价。我们通过关系account来讨论选择查询策略的重要性。
关系account的模式为:
Account一schema=(account一number, branchname, blance)。
考虑一个极其简单的查询:“找出account关系中的所有元组”。虽然这个查询很简单,但对它的处理却不是微不足道的,因为在分布式数据库中account关系可能被分片,被复制,也可能既分片又复制。如果account关系被复制,我们就需要对副本进行选择。如果所有的副本都没有被分片,我们就选择使传输代价最小的那个副本;但是,如果副本被分片了,进行选择就不那么容易,因为我们需要进行一些连接运算来重构account关系。这种情况下,我们这个简单例子的执行策略可能会很多。这时,通过穷举所有可能的策略来对查询进行优化是不可能的。显然,我们需要根据不同查询要求来选择不同的查询策略,以减少查询的总代价。
简单的连接处理选择查询策略的一个主要方面就是选择连接策略。考虑下面的关系代数表达式:
accountc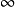 depositorc
depositorc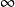 branch·
branch·
假设这三个关系既没有被复制,也没有被分片,且account存储在站点S1上,depositor存储在站点S2上,branch存储在站点S3上。设S1表示提出查询的站点。系统需要在站S1点产生结果。下面是处理这个查询可采取策略中的几个:
1)将三个关系的副本都送到站点SI,使用集中式的查询处理技术,在站点SI上选择一个本地处理整个查询的策略。
2)将关系account的一个副本送到站点S2,在S2上计算temp1=account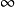 deposit。将temp1从S2送到S3,在S3上计算temp2= temp1
deposit。将temp1从S2送到S3,在S3上计算temp2= temp1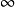 branch。最后将结果temp2送到S1。
branch。最后将结果temp2送到S1。
3)设计与上一个策略类似的策略,只是交换S1, S2, S3的角色。
没有一个策略总是最好的。我们需要考虑的因素中包括运送的数据量、在一对站点间传输数据块的代价以及各站点上处理的相对速度。考虑上面列出的前两个策略。如果我们将三个关系都送到站点S1,并且在这些关系上存在索引,我们可能需要在S1上重新创建索引。重新创建索引带来了额外的处理开销和额外的磁盘访问。然而,第二种策略也存在缺点,那就是一个可能很大的关系( customer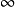 account)必须从S2送到S3。此关系中,客户每拥有一个账户,其地址就要重复一次。因此同第一种策略相比,第二种策略可能导致额外的网络传输。
account)必须从S2送到S3。此关系中,客户每拥有一个账户,其地址就要重复一次。因此同第一种策略相比,第二种策略可能导致额外的网络传输。
查询优化查询优化就是从这些策略中找出最有效查询计划的一种过程。一个好的查询策略往往比一个坏的查询策略在执行效率(基于执行时间)上高几个数量级。以关系数据库系统为例,查询优化处理是关系数据库系统的基本优势所在。关系数据库的查询使用SQL语句实现,对于同一个用SQL表达的查询要求,通常可以有多个不同形式但相互“等价”的关系代数表达式。对于描述同一个查询要求但形式不同的关系代数表达式来说,由于存取路径不同,相应的查询效率就会产生差异,有时这种差异可以相当巨大。在关系数据库中,为了提高查询效率需要对一个查询要求寻求“好的”查询路径(查询计划),或者说“好的”、等效的关系代数表达式。这种“查询优化”是关系数据库的关键技术,也是其巨大的优势。1
在关系数据库中,用户使用的查询语句主要表达查询条件和查询结果,而查询的具体实施过程及其查询策略选择都由数据库管理系统负责完成,因此查询具有非过程性的突出特征。
数据查询是数据库中最基本、最常用和1最复杂的数据操作,从实际应用角度来看,必须考察系统用于数据查询处理的开销代价。查询处理的代价通常取决于查询过程对磁盘的访问。磁盘访问速度相对于内存速度要慢得多。在数据库系统中,用户查询通过相应的查询语句提交给数据库管理系统执行。一般而言,相同的查询要求和结果存在着不同的实现策略,系统在执行这些查询策略时所付出的开销通常有很大差别,甚至可能相差好几个数量级。实际上,对于任何一个数据库系统来说,这种“择优”的过程就是“查询处理过程中的优化”,简称为查询优化。
查询优化技术查询优化的基本方式可分为用户手动优化和系统自动优化两类。手动优化还是自动优化,在技术实现上取决于相应表达式语义层面的高低。
在基于格式化数据模型的层次和网络数据库系统中,由于用户通常使用较低层面上的语义表述查询要求,系统难以自动完成查询策略的选择,只能由用户自己完成,由此可能导致的问题有二:其一,当用户做出了明显的错误查询决策时,系统对此无能为力;其二,用户必须相当熟悉有关编程问题,这样就加重了用户的负担,妨碍了数据库的广泛使用。关系数据库的查询语言是高级语言,具有更高层面上的语义特征,有可能完成查询计划的自动选择。
与手动优化比较,系统自动优化有如下的明显优势:
(1)能够从数据字典中获取统计信息,根据这些信息选择有效的执行计划。用户手工优化时的程序则难以得到这些信息。
(2)当数据库物理统计信息改变时,系统可以自动进行重新优化以选择相适应的执行计划,而手工优化必须重新编写程序。
(3)可以从多种(如数百种)不同的执行计划中进行选择;而手工优化时.程序员一般只能考虑数种可能性。
(4)优化过程可能包含相当复杂的各种优化技术,这需要受过良好训练的专业人员才能掌握,而系统的自动优化使每个数据库使用人员(包括不具有专业训练的普通用户)都能拥有相应的优化技术。
一个“好”的数据库系统,其中的查询优化应当是自动的,即由系统的数据库管理系统自动完成查询优化过程。
查询优化器查询优化器和三类优化技术自动进行查询优化是数据库管理系统的关键技术。由数据库管理系统自动生成若干候选查询计划并且从中选取较“优”的查询计划的程序称为查询优化器。
查询优化器所使用的技术可以分为三类。
(1)规则优化技术
如果查询仅仅涉及查询语句本身,根据某些启发式规则,例如“先选择、投影和后连接”等就可以完成优化,称之为规则优化。这类优化的特点是对查询的关系代数表达式进行等价变换,以减少执行开销,所以也称为代数优化。
(2)物理优化技术
如果优化与数据的物理组织和访问路径有关,例如,在已经组织了基于查询的专门索引或者排序文件的情况下,就需要对如何选择实现策略进行必要的考虑,诸如此类的问题就是物理优化。
(3)代价估算优化技术
对于多个候选策略逐个进行执行代价估算,从中选择代价最小的作为执行策略,就称为代价估算优化。
物理优化涉及数据文件的组织方法,代价估算优化开销较大,因此它们都只适用于一定的场合。
关系查询优化的可行性我们已经知道,查询表达式具语义层面的高低决定查询优化是否自动。关系数据模型本质上基于集合论,从而使得关系数据的自动查询优化具有了必要的理论基础。相应的关系查询语言是一种高级语言,具有很高层面上的语义表现,从而又使由机器处理查询优化具有可实现的技术基础。因此,在关系数据库系统中进行自动查询优化是可行的。
当关系查询语言表示的查询操作基于集合运算时,可称其为关系代数语言;而基于关系演算时,可称其为关系演算语言。这两种语言本身是有过程性的,但由于所依据理论本身不同义各有差异。
关系代数具有5种基本运算,这些运算自身和相互间满足一定的运算定律,例如,结合律、交换律、分配率和串接率等,这就意味着不同的关系代数表达式可以得到同一结果,因此用关系代数语言进行的查询就有进行优化的可能。
关系演算中需要使用“存在”和“任意”两个量词,这两个量词也有自身的演算规则,例如,两个量词之间的先后顺序,只不过这里的涉及面较窄,运算规则较为整齐,在“等价”的关系演
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国