

简介
纵向数据作为一种特殊形式的数据,广泛地产生于医学和社会学等领域。它主要来自于是每个个体在不同时间点上的观测值。参数混合模型(也叫随机效应模型)是分析纵向数据的有力工具。纵向数据研究的一个难点是怎样考虑组内相关,而线性和非线性混合效应模型很好地解决了这个问题,所以线性和非线性混合效应模型被广泛的应用于纵向数据的研究。1
传统纵向数据分析方法重复测量方差分析重复测量的方差分析在实际中有非常广泛的应用,其中的一个作用就是用来分析重复测量实验设计(又称被试内设计,混合设计等)得来的数据。该方法通过把总的变异分解为被试内和被试间两部分,对被试的平均增长趋势进行分析,可以通过多项式比较分析线性增长趋势和非线性增长趋势。如果研究中我们只关心不同时间点的平均数间是否存在差异可,以用单变量方差分析解决这一问题。但是值得注意的是,应用重复测量的方差分析时,必须满足协方差矩阵球形sphericity的假设条件,也就是说,MANOVA要求所有重复测量的总体的方差相等并且所有重复测量总体之间的协方差也相等。如这一条件不满足,那么得到的F检验统计量的值正偏,拒绝虚无假设的概率增大,也就是说如果观测变量协方差矩阵球形假设条件不满足,传统重复测量的方差分析的统计检验力降低,F检验犯第一类错误的概率增大。另外,MANOVA不能用来处理依时间变化的协变量对因变量的影响。关于重复测量方差分析的详细介绍在大多数的统计资料中都有较详细的介绍。
时间序列分析时间序列分析是对纵向研究数据进行分析的另外一类非常重要的统计分析技术。它在许多领域都有十分重要的应用,尤其在预测和控制应用方面有着其它方法不可比拟的优点。时间序列分析以回归分析为基础,目的在于测定时间序列中存在的长期趋势、季节性变动、循环波动及不规则变动并进行统计预测。
为了对时间序列中不同的变化趋势进行分析,主要有两大类模型经典模型:KineticModel和动态模型。DynamicalModel经典模型是将时间序列{xt,t∈T}看作是时间的函数xt=f(t);而动态模型是将t时刻的观测看成是t时刻前观测值,可以与t时刻的观测类型相同也可以不同的函数,xt=f(xt-1,xt-2...)
通常所说的AR,ARMA,ARMIA模型都属于这一类。为了便于和其他几种方法比较,只简单介绍第一种类型模型。对于第一种类型的模型,常用的模型有加法模型,即假定各构成部分对时间序列的影响是相互独立的。这时可以将时间序列表示为xt=T+C+S+I,其中T、S、C、I分别代表时间
时间序列中存在的长期趋势、季节性变动、循环波动及不规则变动;另一类是乘法模型,即假设各组成部分对时间序列的影响均按比例变化,从而可以把时间序列表示为xt=T×C×S×I。除上面的加法模型和乘法模型外,还有其它混合模型,不再一一列举。进行时间序列分析,如果要测定长期趋势,可以是直线的,也可以是非直线的,可以通过移动平均法时、距扩大法或数学模型法,剔除时间序列中循环波动C、季节性变动S及不规则变动I,使得时间序列的长期增长趋势显现出来,对于时间序列中的第二类模型在实际中有许多应用模型,分类也比较复杂,需要对时间序列的平稳性进行分析,并且要求研究者有较高的数学素养。另外由于时间序列分析往往要求较多的连续观测时间点,所以在心理学和教育学中用的不是很多。
目前常用的统计软件SAS、SPSS和BMDP都含有时间序列分析过程。可以对常见的几种时间序列模型进行统计分析。2
新型纵向数据处理方法潜变量增长曲线模型潜变量增长曲线模型是用于固定情形(fixedoccasion)纵向研究数据的一种统计分析方法,也就是说,该方法适用于在某几个固定时间点观测得来的纵向研究资料。在潜变量增长曲线模型中,用潜变量来描述总体的平均增长趋势和依时间变化的情况。基本模型可以用下图表示(图):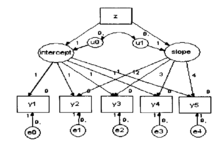
图描述的是含有五个测试时间点的潜变量增长模型,Y1i,Y2i,Y3i,Y4i,Y5i分别表示第i个被试的5次测量结果,上述模型可以表示为:
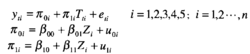
其中π0i,π1i分别表示截距和斜率,在上面的模型中,这一截距和斜率为随机参数,(2)和(3)进一步解释上述截距π0i和斜率π1i的变化。
从上面模型的描述可以看出潜变量增长曲线模型同时考虑因素的平均值和方差,也就是说,潜变量增长曲线模型不仅分析了总体的发展趋势,而且可以分析总体之间存在的差异。
事实上,在上述的潜变量模型中,只是简单地定义了线性增长模型,在实际中,可以不固定斜率测量的因素载荷(如在图中让固定为2,3,4的斜率载荷自由估计)得到增长曲线模型,还可以定义测量误差之间的不同关系(如限定测量误差相等,误差间存在一阶自相关,二阶自相关等等)。有关潜变量增长曲线的更详细的和深入的介绍,可以参看Duncan的著作。
潜变量增长曲线模型可以用协方差结构模型(SEM)软件进行分析,常用的软件有Lisrelt,AMOS,EQS和MPLUS等。2
多层线性模型多层线性模型是用于分析具有嵌套结构特点数据的一种统计分析技术,近年来在教育、管理等领域有相当广泛的应用。当对相同的观测对象进行重复测量时,可以将这些重复测量的数据本身看成是具有嵌套结构特点的。如对生长发育期儿童身高和体重变化情况的追踪调查等,可将这些重复测量数据构造出一个两水平的层次结构,其重复测量或测量点为水平1的单位,观测个体为水平2的单位,这时就可用多层分析的方法对纵向数据进行分析。
对于重复测量的数据,用层次分析法描述数据之间的关系,对应的两水平重复测量模型,可以用下式表示(下面只给出最简单的一种多层模型形式,实际上,可以进一步考虑更多的不同水平预测变量和更复杂的随机残差之间的关系):
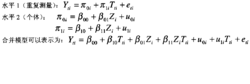
从上面的模型中可以看出,与潜变量增长曲线模型类似,多层分析不仅可以分析总体上个体随时间的变化(截距β00和斜率β00,而且可以将个体之间增长的差异进行分析(截距的差异u0i,斜率的差异u1i),并将这一差异的原因进行解释(β00解释截距的差异和β00解释斜率的差异)。
可以在上述模型中包含更多的水平I的随机误差。这主要是由于在重复测量的模型,测量与测量之间往往是相关的而不是独立的(如在个体水平上的多次测量,由于具有相同的个体特征和测量间的相互影响,存在的测量误差(第一水平的随机误差)之间的“自相关”。
对于多层线性模型的数据分析,可以采用专门的软件进行分析,常用的用于多层分析的统计分析软件有:HLM,MLn,VARCL,SAS和Mplus。2
纵向数据处理方法述评上面介绍的用于纵向研究的常用方法,各有优缺点,简述如下:
重复测量的方差分析主要用来比较均值间的差异,一般不对增长的变异情况进行分析,也就是说,重复测量的方差分析主要用来描述总体的平均增长趋势,而不关注个体增长曲线存在的差异,有计算简单,易于理解等优点。最主要的缺点是不能就个体之间存在差异的原因进行分析和解释,数据中的缺失值不能得到精确的估计,在数据缺失量较大时,分析所用数据信息损失较大。另外,重复测量方差分析不能处理分段间距不等或测量次数不等的数据。
时间序列分析是一类很有用的分析数据随时间变化趋势的统计技术,在自然科学和社会科学各个领域都有非常重要的应用价值,但是由于其理论比较复杂、要求测试的时间点相对具有连续性和要求较多的测试时间点等特点,所以在心理学和教育学的研究中用的不是特别普遍。
采用多层分析的方法处理重复测量数据与时间变量之间的关系,在多层结构中,可以对非平衡测量数
据得到参数的有效估计,因此用多层分析法处理重复测量的数据,不要求所有的观测个体有相同的观测数,在纵向调查研究中,由于各种各样的原因,被试个体观测值部分缺失的情况时有发生,因此多层分析法处理缺失数据而不影响参数估计精度的这一特征,使得多层分析法处理在处理纵向观测数据时,比传统多元重复测量方法有很大的优势。与传统的用于处理多元重复测量数据的方差分析和回归分析方法相比,多层分析法至少具有以下优点:多层分析法通过考虑测量水平和个体水平不同的差异,明确表示出个体
在水平1(不同测量点)的变化情况,因而对于数据的解释(个体随时间的增长趋势)是在个体与重复测量交互作用基础上的解释,即不仅包含了不同测量点的差异,而且包含了个体之间存在的差异;多层分析法对数据资料较传统多元重复测量方法有较低的要求,对于重复测量的次数和重复测量之间的时间跨度都没有严格的限制,不同个体可以有不同的测量次数,测量与测量之间的时间跨度也可以不同;多层分析模型可以定义重复观测变量之问复杂的协方差结构,并且对所定义的不同的协方差结构进行显著性检验,在多层分析模型中,通过定义第一水平和第二水平的随机变异来解释个体随时间的复杂变化情况;当数据满足传统多变量重复测量模型对数据的要求和假设时,层次分析法得到与传统固定效应多元重复测量模型相同的参数估计和假设检验结果;用多层分析模型可以考虑更高一层的变量(如不同地区儿童)对个体增长的影响。但是多层分析模型也有缺点,首先用于多层分析模型的参数估计方法较传统估计参数的方法要复杂得多,而且与后面介绍的LGM方法相比也不能处理变量之间间接的影响关系和处理复杂的观测变量和潜变量之间的关系。
潜变量增长曲线模型(LGM)可以直接处理变量之间复杂的因果关系,即不仅可以对变量之间直接的影响关系进行分析,而且可以将变量之间间接的因果关系进行分析;另外,由于潜变量结构模型是基于协方差结构模型的理论,所以不仅可以分析观测变量之间的关系,而且可以在考虑测量误差的基础上对潜变量之间的因果关系进行考察;上面介绍的多层分析模型只能分析变量之间的直接因果路径,对于潜变量之间关系的分析要比LGM复杂得多,并且在测量模型上也有更多的限定条件。LGM模型可以简便地处理变量测量误差(残差)之间的关系,而不必限定残差之间相互独立,如可以直接定义类似于AR和ARMA模型中所要求的残差之间的关系类型;用HLM虽然没有残差之间相互独立的要求,但是用现有的多层分析软件定义起来要比LGM复杂得多。LGM的另外一个优点是,因为LGM分析可以采用标准的用于SEM的分析软件,所以可以得到模型整个拟合的情况,并且可以根据提供的修正指数对模型进行修改。LGM不仅就个体的发展轨迹进行描述,而且可以分析个体之间存在的差异以及存在差异的原因;LGM不仅可以对给定的增长趋势进行检验,而且在观测时间点多于两点的情况下可以对个体随时间变化的趋势类型(如直线或曲线)进行探索。LGM可以分析依时间变化的预测变量对因变量的影响,并且可以用类似于SEM中多样本比较的方法对多个样本之间的差异进行检验,可以有效处理缺失值。但是LGM也有如下缺点,因为LGM用SEM的基本原理对变量之间的关系进行分析,所以为了得到可靠的分析和检验结果,往往要求比较大的样本容量:对于所有个体的评估要求测试时间间隔相同,如果个体的变化随时间变化趋势不是很明显,LGM方法与传统方法相比没有明显的优势。2
应用前景在心理学应用中,对于纵向研究的资料,我们往往不仅对个体增长的平均趋势感兴趣,而且希望分析个体之间增长存在的差异。作为综合分析方法,应当能够同时解决这两个问题。潜变量增长曲线模型和多层分析模型是在传统分析方法基础上发展起来的综合分析的统计技术,这两种方法可以同时解决上面提到的两个问题。从国外纵向研究的发展趋势来看,这两种方法近年来越来越受到重视,其原因不仅是因为这两种方法是一种新的统计分析技术,更重要的是他们可以帮助我们发现事物发展的更深一层的规律,可以对个体之间的发展变化进行进一步的分析和解释,为理论研究提供更加有意义的实证研究的成果。国内心理学研究中,多层分析方法处于起步阶段,潜变量增长曲线模型还没有见有介绍。
在心理学研究中,人们已经不满足于现象的描述(横断数据资料的分析)和简单的差异的检验,要对人类心理现象发展的内在心理机制进行研究,把握事物发展的内在规律,纵向研究必然越来越受到研究者们的重视。随着纵向研究方法的应用,用于纵向数据分析的综合统计分析技术——潜变量增长曲线模型和多层分析法必然受到研究者们的青睐。2
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国