

背景
随着计算机应用范围的日益扩大,分布式异构系统(DHS DistributedHeterogeneous System)逐渐成为解决复杂应用问题的有效工具。DHS利用一组异构的计算机来协作完成应用任务,以期获得最好的执行效果。DHS中的任务调度问题,对发挥系统的并行性能和保持负载平衡具有非常重要的意义。该问题已被证明是NP完全问题,无法在多项式时间内找到最优解,所以促使人们不懈地研究如何设计调度算法,用有限的代价获得更好的解。目前常用的方法就是启发式算法和随机搜索的近似方法。
异构数据库系统异构数据库系统是相关的多个数据库系统的集合,可以实现数据的共享和透明访问,每个数据库系统在加入异构数据库系统之前本身就已经存在,拥有自己的DBMS。异构数据库的各个组成部分具有自身的自治性,实现数据共享的同时,每个数据库系统仍保有自己的应用特性、完整性控制和安全性控制。异构数据库系统的异构性主要体现在以下几个方面:
1、计算机体系结构的异构
各个参与的数据库可以分别运行在大型机、小型机、工作站、PC或嵌入式系统中。
2、基础操作系统的异构
各个数据库系统的基础操作系统可以是Unix、Windows NT、 Linux等。
3、DBMS本身的异构
可以是同为关系型数据库系统的Oracle、 SQL Server等,也可以是不同数据模型的数据库,如关系、模式、层次、网络、面向对象,函数型数据库共同组成一个异构数据库系统。
----异构数据库系统的目标在于实现不同数据库之间的数据信息资源、硬件设备资源和人力资源的合并和共享。其中关键的一点就是以局部数据库模式为基础,建立全局的数据模式或全局外视图。这种全局模式对于建立高级的决策支持系统尤为重要。
----大型机构在许多地点都有分支机构,每个子机构的数据库中都有着自己的信息数据,而决策制订人员一般只关心宏观的、为全局模式所描述的信息。建立在数据仓库技术基础上的异构数据库全局模式的描述是一种好的解决方案。数据仓库可以从异构数据库系统中的多个数据库中收集信息,并建立统一的全局模式,同时收集的数据还支持对历史数据的访问,用户通过数据仓库提供的统一的数据接口进行决策支持的查询。
分布式系统分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统。透明性是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程。在分布式数据库系统中,用户感觉不到数据是分布的,即用户不须知道关系是否分割、有无副本、数据存于哪个站点以及事务在哪个站点上执行等。
在一个分布式系统中,一组独立的计算机展现给用户的是一个统一的整体,就好像是一个系统似的。系统拥有多种通用的物理和逻辑资源,可以动态的分配任务,分散的物理和逻辑资源通过计算机网络实现信息交换。系统中存在一个以全局的方式管理计算机资源的分布式操作系统。通常,对用户来说,分布式系统只有一个模型或范型。在操作系统之上有一层软件中间件(middleware)负责实现这个模型。一个著名的分布式系统的例子是万维网(World Wide Web),在万维网中,所有的一切看起来就好像是一个文档(Web页面)一样。
在计算机网络中,这种统一性、模型以及其中的软件都不存在。用户看到的是实际的机器,计算机网络并没有使这些机器看起来是统一的。如果这些机器有不同的硬件或者不同的操作系统,那么,这些差异对于用户来说都是完全可见的。如果一个用户希望在一台远程机器上运行一个程序,那么,他必须登陆到远程机器上,然后在那台机器上运行该程序。
分布式系统和计算机网络系统的共同点是:多数分布式系统是建立在计算机网络之上的,所以分布式系统与计算机网络在物理结构上是基本相同的。
他们的区别在于:分布式操作系统的设计思想和网络操作系统是不同的,这决定了他们在结构、工作方式和功能上也不同。网络操作系统要求网络用户在使用网络资源时首先必须了解网络资源,网络用户必须知道网络中各个计算机的功能与配置、软件资源、网络文件结构等情况,在网络中如果用户要读一个共享文件时,用户必须知道这个文件放在哪一台计算机的哪一个目录下;分布式操作系统是以全局方式管理系统资源的,它可以为用户任意调度网络资源,并且调度过程是“透明”的。当用户提交一个作业时,分布式操作系统能够根据需要在系统中选择最合适的处理器,将用户的作业提交到该处理程序,在处理器完成作业后,将结果传给用户。在这个过程中,用户并不会意识到有多个处理器的存在,这个系统就像是一个处理器一样。
数据库转换
----对于异构数据库系统,实现数据共享应当达到两点:一是实现数据库转换;二是实现数据的透明访问。由华中科技大学开发的,拥有自主版权的商品化数据库管理系统DM3系统,通过所提供的数据库转换工具和API接口实现了这两点。
----DM3提供了数据库转换工具,可以将一种数据库系统中定义的模型转化为另一种数据库中的模型,然后根据需要再装入数据,这时用户就可以利用自己熟悉的数据库系统和熟悉的查询语言,实现数据共享的目标。数据库转换工具首先进行类型转换,访问源数据库系统,将源数据库的数据定义模型转换为目标数据库的数据定义模型,然后进行数据重组,即将源数据库系统中的数据装入到目的数据库中。
----在转换的过程中,有时要想实现严格的等价转换是比较困难的。首先要确定两种模型中所存在的各种语法和语义上的冲突,这些冲突可能包括:
命名冲突:即源模型中的标识符可能是目的模型中的保留字,这时就需要重新命名。
格式冲突:同一种数据类型可能有不同的表示方法和语义差异,这时需要定义两种模型之间的变换函数。
结构冲突:如果两种数据库系统之间的数据定义模型不同,如分别为关系模型和层次模型,那么需要重新定义实体属性和联系,以防止属性或联系信息的丢失。
----总之,在进行数据转换后,一方面源数据库模式中所有需要共享的信息都转换到目的数据库中,另一方面这种转换又不能包含冗余的关联信息。
----数据库转换工具可以实现不同数据库系统之间的数据模型转换,需要进一步研究的问题是:如果数据库转换同时进行数据定义模式转换和数据转换,就可能引起同一数据集合在异构数据库系统中存在多个副本,因此需要引入新的访问控制机制。在保证各个参与数据库自治,维护其完整性、安全性的基础上,对于异构数据库系统提供全局的访问控制、并发机制和安全控制。
----如果数据库转换只进行数据定义转换,不产生数据的副本,那么在新的目的数据库定义模型的框架下访问数据,实现上仍是对源数据库系统中数据的访问。这时利用新的数据库系统中的数据处理语言实现的事务,不能直接访问源数据库,必须进行事务级的翻译才可以执行。
数据的透明访问
----在异构数据系统中实现了数据的透明访问,用户就可以将异构分布式数据库系统看成普通的分布式数据库系统,用自己熟悉的数据处理语言去访问数据库,如同访问一个数据库系统一样。但目前还没有一种广泛使用的数据定义模型和数据查询语言,实现数据的透明访问可以采用多对一转换、双向的中间件等技术。开放式数据库互连(Open DataBaseconnectivity,简称ODBC)是一种用来在相关或不相关的数据库管理系统中存取数据的标准应用程序接口(API)。ODBC为应用程序提供了一套高层调用接口规范和基于动态链接库的运行支持环境。目前,常用的数据库应用开发的前端工具如Power Builder、 Delphi等都通过开放数据库互联(ODBC)接口来连接各种数据库系统。而多数数据库管理系统(如:Oracle、Sybase、SQL Server等)都提供了相应的ODBC驱动程序,使数据库系统具有很好的开放性。ODBC接口的最大优点是其互操作能力,理想情况下,每个驱动程序和数据源应支持完全相同的ODBC函数调用和SQL语句,使得ODBC应用程序可以操作所有的数据库系统。然而,实际上不同的数据库对SQL语法的支持程度各不相同,因此,ODBC规范定义了驱动程序的一致性级别,ODBC API的一致性确定了应用程序所能调用的ODBC函数种类,ODBC 2.0规定了三个级别的函数,目前 DM3 ODBC API支持 ODBC 2.0规范中第二级扩展的所有函数。
----随着Internet应用的不断普及,Internet的异构分布式信息系统正在迅速发展,Java以其平台无关性、移植性强,安全性高、稳定性好、分布式、面向对象等优点而成为Internet应用开发的首选语言。在Internet环境下,实现基于异种系统平台的数据库应用,必须提供一个独立于特定数据库管理系统的统一编程界面和一个基于 SQL的通用的数据库访问方法。Java与数据库接口规范JDBC(Java Database Connectivity)是支持基本SQL功能的一个通用的应用程序编程接口,它在不同的数据库功能模块的层次上提供了一个统一的用户界面,为对异构数据库进行直接的Web访问提供了新的解决方案。 JDBC已被越来越多的数据库厂商、连接厂商、Internet服务厂商及应用程序编制者所支持。
动态任务调度策略静态调度策略在调度前,并行程序的各子任务执行位置己经确定,而且经常用于任务关系比较确定的情况,但实际的并行程序较难满足此限制,并在执行中存在众多不确定因素,如:1
1.并行程序任务中的循环次数事先不能确定。
2.条件分支语句到底执行哪个分支,在程序执行前不能完全了解。
3.每个任务的负载大小事先不能确定。
4.任务间的数据通讯量大小只有在运行时才能确定。
而且在结点机的负载波动较大时,应考虑采用动态负载平衡的任务调度策略。在分布式系统中,动态负载平衡就是系统根据当前的系统状态与负载分布的情况,对各个结点上的工作负载进行动态的调整,使待分配的或者已分配给重载结点的任务,通过通讯设备迁移到轻载结点上去,从而提高系统资源的利用率,减少任务的平均响应时间。
动态任务分配策略具有超过静态调度策略的执行潜力,能够相互交换系统的状态信息决定系统负载的分配,能够适应系统负载变化情况,比静态调度策略更灵活、有效。动态调度策略利用系统状态的短期波动来提高性能,由于它必须收集、储存并分析状态信息,因此动态调度策略会产生比静态调度策略更多的系统开销,但这种开销常常可以被抵消掉。
任务复制技术在异构分布式系统中,任务复制技术是实现容错的主要手段,最具代表性的主/副版技术(Primary/Backup Copy,P/B)广泛应用于容错调度方法。它通过在备份处理器上执行备份任务来实现容错。2
P/B复制技术有3种执行方式:主动复制方式(ActiveBackup Copy、被动复制方式(Passive BackupCopy)和混合复制方式(P/B Overlapping BackupCopy)。目前学术界对DAU任务容错调度的研究也都是基于任务复制机制,针对副版数复制数量来区分,主要有2种复制方式.
每个任务仅有一个副版DAU可靠性代价驱动的eFRCD(efficient Fault tolerant Reliability Cost Driven)算法,该算法对DAU中的每一个任务都有一个分配在不同处理器上的副版任务。为了提高性能,对于主版不在同一个处理器上的多个任务,系统允许在同一个处理器上的这些任务的副版可以重叠。然而,这种方法必须假设这些任务之间是相互独立的,不能满足DAU中有优先级约束任务的需要,因此在eFRCD算法基础上,又提出了改进的eFRD(efficient Fault tolerant Reliability Driven)算法,该算法采用主副版重叠机制,即允许任务的副版与此任务的所有后继任务的主版重叠,可以进一步降低调度长度。在eFRD算法的基础上提出了基于最早完成时间的最小复制开销的MRC-ECT(Minimum Replication Cost with EarlyCompletion Time)算法和基于最小复制开销的最小完成时间的MCT-LRC(Minimum Completion Timewith Less Replication Cost)算法分别对DAU中的非独立任务和独立任务进行容错调度。
首先,上述研究针对可靠性问题,假设某一个时刻最多只有一个处理器出现故障,且在下个故障出现时,前一个故障己经排除,假设较为理想导致实用性不强。同时也只考虑DAU的可调度性,没有考虑可靠性目标。给出可靠性目标的定义,即系统任务集里的每个任务都有。个副版,一个任务成功分配的条件是该任务的。个副版分配到不同的处理器上,且没有导致这些处理器的利用率超过1,在满足任务副版时间约束和系统高可靠性条件的基础上,最大化成功的分配任务。
其次,上述算法都是采用被动复制方式,只有当主版任务调度失败后才能启动副版任务,被动复制在主版任务失效时,需要选择一个新副版任务恢复到失效前状态,造成失效恢复时间较长.因此从截止期限和失效恢复时间考虑,主动复制优于被动复制叫。主动复制能够在运行失效时直接屏蔽失效的任务版,失效恢复时间几乎接近于零,调度长度也相对较短。
每个任务有多个副版提出基于主动复制的FTSA ( FaultTolerant Scheduling Algorithm)算法,此算法是经典的非任务复制的DAU调度算法HEFT( Heterogeneous Earliest Finish Time)的扩展。FTSA容忍ε个错误的发生,并且有ε+1个版本允许在不同的处理器上,但FTSA算法每次只选择一个优先级最高的就绪任务调度。提出了同样基于主动复制的CAFT(Contention Awareness and Fault Tolerant)算法,与FTSA算法每次只选择一个优先级最高的就绪任务不同,CAFT选择一组就绪任务,在同一决策过程中分配其所有副版到相应的处理器,这样能够产生更好的负载均衡.但是FTSA和CAFT算法为了使系统能够达到容忍多个故障,采用了盲目的复制策略,即对于每个任务需要复制的版本个数,并没有精确的量化,而是盲目地使每个任务拥有ε+1个副版,容忍系统中任务可能存在的ε个故障。虽提高了系统的可靠性却易造成任务冗余过高,使得调度过程中既付出了昂贵的计算资源,又造成调度长度过长而可能错过任务的截止期限。盲目的复制策略应用到多个DAU,将造成更加剧了系统的冗余程度过高。
针对主动复制采用ε+1个副版容忍ε个故障的情况,拥有更多的副版并不意味更高的可靠性。其提出的MaxRe算法针对不同的任务,基于可靠性目标而采用不同的副版次数,在满足系统的可靠性目标的前提下,能够最小化资源的使用。但是该算法认为每个任务的可靠性目标为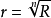 ,其中R为DAG的可靠性需求,n为任务个数,但是由于DAU中的任务存在优先级约束,对于有前驱的任务,需要考虑其直接前驱任务的影响,不能依靠简单的开方就能断定。
,其中R为DAG的可靠性需求,n为任务个数,但是由于DAU中的任务存在优先级约束,对于有前驱的任务,需要考虑其直接前驱任务的影响,不能依靠简单的开方就能断定。
Flex+Java企业的应用系统主要分为三层:
展现层
领域层(业务层)
数据源层
Flex+Java企业应用中,“展线层”逻辑完全运行在客户端的Flash虚拟机中,而“领域层”和“数据访问层”逻辑则运行在服务器端的Java虚拟机中,客户端系统与服务端系统完全用不同的语言实现,因此系统是异构的。同时,客户端代码运行在客户端的ActionScript虚拟机中,而服务器的代码则运行在服务器上的Java虚拟集中,因此,系统又是分布式的。
这与传统Web应用完全不同,传统(JSP/Servlet)应用中所有代码,包括业务逻辑代码和生成人机界面的代码都是在服务器Java虚拟机中执行,如图:
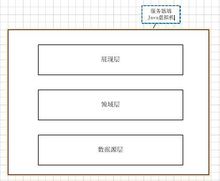
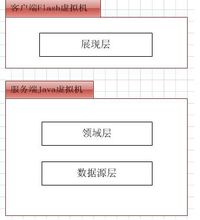
Flex+Java与传统jsp/servlet/struts系统区别是:
使用Flex+java开发的B/S应用系统中,B系统(客户端系统)和S系统(服务器端系统)完全分离。B系统负责“展示层”逻辑,而 s 系统主要负责“领域层”和“数据源层”逻辑。因此,flex+java所开发的系统是异构的分布式系统。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国