

汽车是一个复杂的系统,其间近千种零部件在工作,这些零部件运转的数据信息来源多样,格式不同,因此,对汽车的技术研发人员来说,要掌握这些供研发使用,就必须建设一个可向汽车产业人士开放的多语言多生产体系对应的汽车零部件名称信息查询平台;在这个数据平台上,同时可以查询关联技术、典型图例、配套车型、零部件编号、产品品牌、生产厂家名称等信息,形成一个开放性的网络数据库服务。
而要对这么多来源的数据源信息进行整合并开发出一个平台,势必要进行数据处理——数据清洗、数据转换、及数据验证算法等,即需要零部件数据处理系统1。
零部件数据处理目的零部件数据处理的目的,有两个方面的含义,其一是得到标准的零部件数据,标准指各项属性符合规范,如日期数据含有年月日信息。品牌数据对于不同的语言如福特,针对中文品牌,Ford针对英文(或国际)品牌。同样,福特蒙迪欧和福特嘉年华针对的是中文的车型;其二是发现新的零部件词汇,并将新的零部件名称添加到词汇表中,用于零部件搜索。
内容零部件数据处理主要分为数据格式分析、数据读取、数据清洗、数据转换、数据验证、数据分析、数据入库等部分。在处理过程中,数据首先需要经过格式分析,以确定数据读取的方式,数据的读取根据匹配的格式规则进行;数据清洗和转换是将数据中的垃圾信息清除,并将数据变为标准数据。如“嘉年华3厢”和“嘉年华三厢”是典型的零部件数据的中文车型,这两个数据需要对应到标准的“福特嘉年华三厢”,称这类标准数据为主数据;最后对转换后的数据进行必要的验证,以确保数据的一致性。如零部件数据的车型数据应和品牌数据一致。否则可能出现车型是“福特嘉年华三厢”而品牌却为“上海通用别克”的笑话。此外数据分析的目的,是发现零部件新的词汇,根据固定词汇搭配及出现的频率,自动筛选出新的词汇1。
零部件数据处理系统的总体结构零部件数据处理系统的总体结构如图1,浅色部分为处理的数据处理单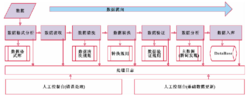 元。数据输入到平台中,依 此 经 过:
元。数据输入到平台中,依 此 经 过:
(1)数据格式分析:对输入数据的格式进行分析,以确定数据读取的对应方式;
(2)数据读取:根据格式分析处理单元得到的格式,读取数据;
(3)数据清洗:根据清洗规则,将数据中含有的非法字符、控制字符过滤;
(4)数据转换:根据转换规则将数据转换为标准数据;
(5)数据验证:根据数据验证规则将一条的数据记录中不同的数据属性进行比较,查找属性相互矛盾的数据记录;
(6)数据分析:根据主数据,及出现频率达到一定值的数据确定为新出现的词,供人工审核后入库;
(7)数据入库:将处理完成的数据如正式库。
数据处理单元,在处理完成后,会将处理的状态写入处理日志。人工控制台随后读取数据处理日志,对相关数据进行人工处理。人工处理根据数据的性质不同主要分为错误数据处理和基础数据的更新。错误数据处理,是指对数据本身进行维护,如日期写成09-01-28,显然数据指2009年1月28日。此外还需要对基础数据进行维护,上述数据的出现主要在数据转换中出现了问题,现有的转换规则不能识别09-01-28这样的日期数据,需要将新发现的规则加入到基础数据的转换规则中去2。
数据处理单元每一个数据处理单元具有相似的结构。实际上在真实的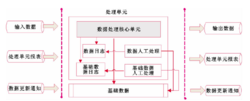 环境中,数据在一个处理单元处理完后,需要将一些相关的信息提交给下一个处理单元,而不仅仅是处理的结果数据。
环境中,数据在一个处理单元处理完后,需要将一些相关的信息提交给下一个处理单元,而不仅仅是处理的结果数据。
如图2所示,处理单元输入由输入数据、处理单元报表和数据更新通知三个部分组成;同样它的输出由输出数据和其他两类组成;中间部分为处理单元的执行实体。
数据的输入、输出输入数据是上一个处理单元处理成功的数据;处理单元报表是本次数据的处理状态统计,含有本次处理的输入数 据 量、处理成功数量、错误数据数量、不能识别的数据量、人工更新数量、基础数据修改数量等信息,它的详细信息在数据、基础数据和日志的内部。处理单元报表建立的主要目的是监控数据的处理状态,使数据处理的过程可以从结果中追述;数据更新通知,是指上一个处理单元中的错误数据或不能识别的数据经过人工修改后,成为成功的数据,这类数据在上一个处理单元前次处理中并没有作为输入进入到本处理单元中,因此需要本处理单元重新处理。
其中,基础数据是规则和主数据的统称,规则含格式规则、清洗规则、转换规则和验证规则四个部分。
数据处理的执行实体数据输入到数据处理单元后,首先由数据处理核心单元进行处理,过程中需要读取基础数据,并对输入数 据 进 行 运 算,将结果数据输出。然后更新数据处理日志和基础数据日志。日志中含需要人工处理的信息,人工处理过程中,如需要对基础数据进行修改,则更新基础数据2。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国