

文件缓冲区是用以暂时存放读写期间的文件数据而在内存区预留的一定空间。通过磁盘缓存来实现,磁盘缓存本身并不是一种实际存在的存储介质,它依托于固定磁盘,提供对主存储器存储空间的扩充,即利用主存中的存储空间, 来暂存从磁盘中读出(或写入)的信息。 主存也可以看做是辅存的高速缓存, 因为,辅存中的数据必须复制到主存方能使用;反之,数据也必须先存在主存中,才能输出到辅存。
一个文件的数据可能出现在存储器层次的不同级别中,例如,一个文件数据通常被存储在辅存中(如硬盘),当其需要运行或被访问时,就必须调入主存,也可以暂时存放在主存的磁盘高速缓存中。大容量的辅存常常使用磁盘,磁盘数据经常备份到磁带或可移动磁盘组上,以防止硬盘故障时丢失数据。有些系统自动地把老文件数据从辅存转储到海量存储器中,如磁带上,这样做还能降低存储价格。
缓冲的引入在设备管理中,引入缓冲区的主要原因可归结为以下几点:
(1) 缓和 CPU 与 I/O 设备间速度不匹配的矛盾。事实上,凡在数据到达速率与其离去速率不同的地方,都可设置缓冲区,以缓和它们之间速率不匹配的矛盾。众所周知,CPU的运算速率远远高于 I/O 设备的速率,如果没有缓冲区,则在输出数据时,必然会由于打印机的速度跟不上而使 CPU 停下来等待;然而在计算阶段,打印机又空闲无事。显然,如果在打印机或控制器中设置一缓冲区,用于快速暂存程序的输出数据,以后由打印机“慢慢地”从中取出数据打印,这样,就可提高 CPU 的工作效率。类似地,在输入设备与 CPU 之间也设置缓冲区,也可使 CPU 的工作效率得以提高。
(2) 减少对 CPU 的中断频率,放宽对 CPU 中断响应时间的限制。在远程通信系统中,如果从远地终端发来的数据仅用一位缓冲来接收,如图 5-10(a)所示,则必须在每收到一位数据时便中断一次 CPU, 这样, 对于速率为 9.6 Kb/s 的数据通信来说, 就意味着其中断 CPU的频率也为 9.6 Kb/s, 即每 100 μs 就要中断 CPU 一次, 而且 CPU 必须在 100 μs 内予以响应,否则缓冲区内的数据将被冲掉。倘若设置一个具有 8 位的缓冲(移位)寄存器,如图 5-10(b)所示, 则可使 CPU 被中断的频率降低为原来的 1/8; 若再设置一个 8 位寄存器, 如图所示,则又可把 CPU 对中断的响应时间放宽到 800 μs。
(3) 提高 CPU和 I/O 设备之间的并行性。缓冲的引入可显著地提高 CPU 和 I/O 设备间的并行操作程度,提高系统的吞吐量和设备的利用率。例如,在 CPU 和打印机之间设置了缓冲区后,便可使 CPU 与打印机并行工作。
缓冲区机制根据应用程序对文件的访问方式,即是否存在缓冲区,对文件的访问可以分为带缓冲区的操作和非缓冲区的文件操作:
a) 带缓冲区文件操作:高级标准文件I/O操作,将会在用户空间中自动为正在使用的文件开辟内存缓冲区。
b) 非缓冲区文件操作:低级文件I/O操作,读写文件时,不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),当然用于可以在自己的程序中为每个文件设定缓冲区。
两种文件操作的解释和比较
1、非缓冲的文件操作访问方式,每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
2、ANSI标准C库函数 是建立在底层的系统调用之上,即C函数库文件访问函数的实现中使用了低级文件I/O系统调用,ANSI标准C库中的文件处理函数为了减少使用系统调用的次数,提高效率,采用缓冲机制,这样,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,即需要少量的CPU状态切换,提高了效率。
缓冲类型单缓冲(Single Buffer)在单缓冲情况下,每当用户进程发出一 I/O 请求时,操作系统便在主存中为之分配一缓冲区,如图所示。在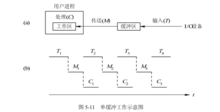 块设备输入时,假定从磁盘把一块数据输入到缓冲区的时间为 T,操作系统将该缓冲区中的数据传送到用户区的时间为 M,而 CPU 对这一块数据处理(计算)的时间为 C。由于 T 和 C 是可以并行的(见图 ),当 T>C 时,系统对每一块数据的处理时间为 M+T,反之则为 M+C,故可把系统对每一块数据的处理时间表示为Max(C,T)+M。
块设备输入时,假定从磁盘把一块数据输入到缓冲区的时间为 T,操作系统将该缓冲区中的数据传送到用户区的时间为 M,而 CPU 对这一块数据处理(计算)的时间为 C。由于 T 和 C 是可以并行的(见图 ),当 T>C 时,系统对每一块数据的处理时间为 M+T,反之则为 M+C,故可把系统对每一块数据的处理时间表示为Max(C,T)+M。
在字符设备输入时,缓冲区用于暂存用户输入的一行数据,在输入期间,用户进程被挂起以等待数据输入完毕;在输出时,用户进程将一行数据输入到缓冲区后,继续进行处理。当用户进程已有第二行数据输出时,如果第一行数据尚未被提取完毕,则此时用户进程应阻塞1。
双缓冲(Double Buffer)为了加快输入和输出速度,提高设备利用率,人们又引入了双缓冲区机制,也称为缓冲对换(Buffer Swapping)。在设备输入时,先将数据送入第一缓冲区,装满后便转向第二缓冲区。此时操作系统可以从第一缓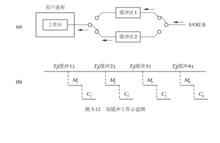 冲区中移出数据,并送入用户进程(见图)。接着由 CPU 对数据进行计算。在双缓冲时,系统处理一块数据的时间可以粗略地认为是Max(C,T)。如果 CT,则可使 CPU 不必等待设备输入。对于字符设备,若采用行输入方式,则采用双缓冲通常能消除用户的等待时间,即用户在输入完第一行之后,在 CPU 执行第一行中的命令时,用户可继续向第二缓冲区输入下一行数据。
冲区中移出数据,并送入用户进程(见图)。接着由 CPU 对数据进行计算。在双缓冲时,系统处理一块数据的时间可以粗略地认为是Max(C,T)。如果 CT,则可使 CPU 不必等待设备输入。对于字符设备,若采用行输入方式,则采用双缓冲通常能消除用户的等待时间,即用户在输入完第一行之后,在 CPU 执行第一行中的命令时,用户可继续向第二缓冲区输入下一行数据。
当输入与输出或生产者与消费者的速度基本相匹配时,采用双缓冲能获得较好的效果,可使生产者和消费者基本上能并行操作。但若两者的速度相差甚远,双缓冲的效果则不够理想,不过可以随着缓冲区数量的增加,使情况有所改善。因此,又引入了多缓冲机制。可将多个缓冲组织成循环缓冲形式。对于用作输入的循环缓冲,通常是提供给输入进程或计算进程使用,输入进程不断向空缓冲区输入数据,而计算进程则从中提取数据进行计算。
循环缓冲的组成
(1) 多个缓冲区。在循环缓冲中包括多个缓冲区,其每个缓冲区的大小相同。作为输入的多缓冲区可分为三种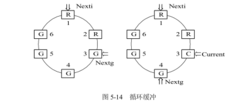 类型:用于装输入数据的空缓冲区 R、已装满数据的缓冲区 G 以及计算进程正在使用的现行工作缓冲区 C,如图所示。
类型:用于装输入数据的空缓冲区 R、已装满数据的缓冲区 G 以及计算进程正在使用的现行工作缓冲区 C,如图所示。
(2) 多个指针。作为输入的缓冲区可设置三个指针:用于指示计算进程下一个可用缓冲
区 G 的指针 Nextg、指示输入进程下次可用的空缓冲区 R 的指针 Nexti,以及用于指示计算
进程正在使用的缓冲区 C 的指针 Current。
循环缓冲区的使用
计算进程和输入进程可利用下述两个过程来使用循环缓冲区。
(1) Getbuf 过程。当计算进程要使用缓冲区中的数据时,可调用 Getbuf 过程。该过程将由指针 Nextg 所指示的缓冲区提供给进程使用,相应地,须把它改为现行工作缓冲区,并令 Current 指针指向该缓冲区的第一个单元, 同时将 Nextg 移向下一个 G 缓冲区。 类似地,每当输入进程要使用空缓冲区来装入数据时,也调用 Getbuf 过程,由该过程将指针 Nexti所指示的缓冲区提供给输入进程使用,同时将 Nexti 指针移向下一个 R 缓冲区。
(2) Releasebuf 过程。当计算进程把 C 缓冲区中的数据提取完毕时,便调用 Releasebuf过程,将缓冲区 C 释放。此时,把该缓冲区由当前(现行)工作缓冲区 C 改为空缓冲区 R。类似地,当输入进程把缓冲区装满时,也应调用 Releasebuf 过程,将该缓冲区释放,并改为 G缓冲区。
进程同步
使用输入循环缓冲,可使输入进程和计算进程并行执行。相应地,指针 Nexti 和指针Nextg 将不断地沿着顺时针方向移动,这样就可能出现下述两种情况:
(1) Nexti 指针追赶上 Nextg 指针。这意味着输入进程输入数据的速度大于计算进程处理数据的速度,已把全部可用的空缓冲区装满,再无缓冲区可用。此时,输入进程应阻塞,直到计算进程把某个缓冲区中的数据全部提取完,使之成为空缓冲区 R,并调用 Releasebuf过程将它释放时,才将输入进程唤醒。这种情况被称为系统受计算限制。
(2) Nextg 指针追赶上 Nexti 指针。这意味着输入数据的速度低于计算进程处理数据的速度,使全部装有输入数据的缓冲区都被抽空,再无装有数据的缓冲区供计算进程提取数据。这时,计算进程只能阻塞,直至输入进程又装满某个缓冲区,并调用 Releasebuf 过程将它释放时,才去唤醒计算进程。这种情况被称为系统受 I/O 限制。
缓冲池上述的缓冲区仅适用于某特定的 I/O 进程和计算进程, 因而它们属于专用缓冲。 当系统较大时,将会有许多这样的循环缓冲,这不仅要消耗大量的内存空间,而且其利用率不高。为了提高缓冲区的利用率,目前广泛流行公用缓冲池(Buffer Pool),在池中设置了多个可供若干个进程共享的缓冲区。
缓冲池的组成
对于既可用于输入又可用于输出的公用缓冲池,其中至少应含有以下三种类型的缓冲区:
① 空(闲)缓冲区;
② 装满输入数据的缓冲区;
③ 装满输出数据的缓冲区。
为了管理上的方便,可将相同类型的缓冲区链成一个队列,于是可形成以下三个队列:
(1) 空缓冲队列 emq。这是由空缓冲区所链成的队列。其队首指针 F(emq)和队尾指针L(emq)分别指向该队列的首缓冲区和尾缓冲区。
(2) 输入队列 inq。这是由装满输入数据的缓冲区所链成的队列。其队首指针 F(inq)和队尾指针 L(inq)分别指向该队列的首缓冲区和尾缓冲区。
(3) 输出队列 outq。这是由装满输出数据的缓冲区所链成的队列。其队首指针 F(outq)和队尾指针 L(outq)分别指向该队列的首缓冲区和尾缓冲区。
除了上述三个队列外, 还应具有四种工作缓冲区: ① 用于收容输入数据的工作缓冲区;② 用于提取输入数据的工作缓冲区;③ 用于收容输出数据的工作缓冲区;④ 用于提取输出数据的工作缓冲区。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国