

基本概念
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。它与内部存储器(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。
CPU操作指令的处理流程大概分为:取指、译码、执行、访存、写回等几步。每条指令需要1~6个字节不等,这取决于需要哪些字段。每条指令的第一个字节表明指令的类型:高4位是代码部分(例:6为整数类操作指令),低4位是功能部分(例:1为整数类中的减法指令) 61合起来即为sub指令。
处理指令流程指令集的一个重要性质就是字节编码必须有唯一的解释。任意一个字节序列要么是一个唯一的指令序列的编码,要么就不是一个合法的字节序列。因为每条指令的第一个字节有唯一的代码和功能组合,给定这个字节,我们就可以决定所有其他附加字节的长度和含义。
每条指令需要1~6个字节不等,这取决于需要哪些字段。每条指令的第一个字节表明指令的类型:高4位是代码部分(例:6为整数类操作指令),低4位是功能部分(例:1为整数类中的减法指令) 61合起来即为sub指令。
下面是处理每条指令的流程图:
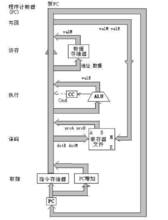
取指(fetch)取值阶段从存储器读取指令字节,放到指令存储器(CPU中)中,地址为程序计数器(PC)的值。它按顺序的方式计算当前指令的下一条指令的地址(即PC的值加上已取出指令的长度)。
译码(decode)ALU从寄存器文件(通用寄存器的集合)读入最多两个操作数。(即一次最多读取两个寄存器中的内容)
执行(execute)在执行阶段会根据指令的类型,将算数/逻辑单元(ALU)用于不同的目的。对其他指令,它会作为一个加法器来计算增加或减少栈指针,或者计算有效地址,或者只是简单地加0,将一个输入传递到输出。
条件码寄存器(CC)有三个条件位。ALU负责计算条件码新值。当执行一条跳转指令时,会根据条件码和跳转类型来计算分支信号cnd。
访存(memory)访存阶段,数据存储器(CPU中)读出或写入一个存储器字。指令和数据存储器访问的是相同的存储器位置,但是用于不同的目的。
写回(write back)写回阶段最多可以写两个结果到寄存器文件。寄存器文件有两个写端口。端口E用来写ALU计算出来的值,而端口M用来写从数据存储器中读出的值。
更新PC(PC update)根据指令代码和分支标志,从前几步得出的信号值中,选出下一个PC的值。
工作过程CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码。它把指令分解成一系列的微操作,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行。指令是计算机规定执行操作的类型和操作数的基本命令。指令是由一个字节或者多个字节组成,其中包括操作码字段、一个或多个有关操作数地址的字段以及一些表征机器状态的状态字以及特征码。有的指令中也直接包含操作数本身。
提取第一阶段,提取,从存储器或高速缓冲存储器中检索指令(为数值或一系列数值)。由程序计数器(Program Counter)指定存储器的位置。(程序计数器保存供识别程序位置的数值。换言之,程序计数器记录了CPU在程序里的踪迹。)
解码CPU根据存储器提取到的指令来决定其执行行为。在解码阶段,指令被拆解为有意义的片段。根据CPU的指令集架构(ISA)定义将数值解译为指令。一部分的指令数值为运算码(Opcode),其指示要进行哪些运算。其它的数值通常供给指令必要的信息,诸如一个加法(Addition)运算的运算目标。
执行在提取和解码阶段之后,紧接着进入执行阶段。该阶段中,连接到各种能够进行所需运算的CPU部件。
例如,要求一个加法运算,算术逻辑单元(ALU,Arithmetic Logic Unit)将会连接到一组输入和一组输出。输入提供了要相加的数值,而输出将含有总和的结果。ALU内含电路系统,易于输出端完成简单的普通运算和逻辑运算(比如加法和位元运算)。如果加法运算产生一个对该CPU处理而言过大的结果,在标志暂存器里可能会设置运算溢出(Arithmetic Overflow)标志。
写回最终阶段,写回,以一定格式将执行阶段的结果简单的写回。运算结果经常被写进CPU内部的暂存器,以供随后指令快速存取。在其它案例中,运算结果可能写进速度较慢,但容量较大且较便宜的主记忆体中。某些类型的指令会操作程序计数器,而不直接产生结果。这些一般称作“跳转”(Jumps),并在程式中带来循环行为、条件性执行(透过条件跳转)和函式。许多指令会改变标志暂存器的状态位元。这些标志可用来影响程式行为,缘由于它们时常显出各种运算结果。例如,以一个“比较”指令判断两个值大小,根据比较结果在标志暂存器上设置一个数值。这个标志可藉由随后跳转指令来决定程式动向。在执行指令并写回结果之后,程序计数器值会递增,反覆整个过程,下一个指令周期正常的提取下一个顺序指令。
CPU指令集CPU指令集主要有:MMX、SSE、SSE2、SSE3、3DNow!、AMD64、EM64T等。
MMX:MMX(Multi Media eXtension 多媒体扩展指令)指令集是Intel公司在1996年为旗下的Pentium系列处理器所开发的一项多媒体指令增强技术。MMX指令集中包括了57条多媒体指令,通过这些指令可以一次性处理多个数据,在处理结果超过实际处理能力的时候仍能够进行正常处理,如果在软件的配合下,可以得到更强的处理性能。
使用MMX指令集的好处就是当时所使用的操作系统可以在不做任何改变的情况下执行MMX指令。但是,MMX指令集的问题也是比较明显的,MMX指令集不能与X86的浮点运算指令同时执行,必须做密集式的交错切换才可以正常执行,但是这样一来,就会造成整个系统运行速度的下降。
SSE:SSE是Streaming SIMD Extension(SIMD扩展指令集)的缩写,而其中SIMD的为含意为Single Istruction Multiple Data(单指令多数据),所以SSE指令集也叫单指令多数据流扩展。该指令集最先运用于Intel的Pentium III系列处理器,其实在Pentium III推出之前,Intel方面就已经泄漏过关于KNI(Katmai New Instruction)指令集的消息。这个KNI指令集也就是SSE指令集的前身,当时也有不少的媒体将该指令集称之为MMX2指令集,但是Intel方面却从没有发布有关MMX2指令集的消息。
最后在Intel推出Pentium III处理器的时候,SSE指令集也终于水落石出。SSE指令集是为提高处理器浮点性能而开发的扩展指令集,它共有70条指令,其中包含提高3D图形运算效率的50条SIMD浮点运算指令、12条MMX 整数运算增强指令、8条优化内存中的连续数据块传输指令。理论上这些指令对当时流行的图像处理、浮点运算、3D运算、多媒体处理等众多多媒体的应用能力起到全面提升的作用。
SSE指令与AMD公司的3DNow!指令彼此互不兼容,但SSE包含了3DNow!中的绝大部分功能,只是实现的方法不同而已。SSE也向下兼容MMX指令,它可以通过SIMD和单时钟周期并行处理多个浮点数据来有效地提高浮点运算速度。
3DNow!:3DNow!指令集最由AMD公司所推出的,该指令集应该是在SSE指令之前推出的,被广泛运用于AMD的K6、K6-2和K7系列处理器上,拥有21条扩展指令集。在整体上3DNow!的SSE非常相相似,它们都拥有8个新的寄存器,但是3DNow!是64位的,而SSE是128位。所以3DNow!它只能存储两个浮点数据,而不是四个。
但是它和SSE的侧重点有所不同,3DNow!指令集主要针对三维建模、坐标变换和效果渲染等3D数据的处理,在相应的软件配合下,可以大幅度提高处理器的3D处理性能。AMD公司后来又在Athlon系列处理器上开发了新的Enhanced 3DNow!指令集,新的增强指令数达了52个,以致目前最为流行的Athlon 64系列处理器还是支持3DNow!指令的。
SSE2:在PentiumIII发布的时候,SSE指令集就已经集成在了处理器的内部,但因为各种原因一直没有得到充分的发展。直到Pentium 4发布之后,开发人员看到使用SSE指令之后,程序执行性能将得到极大的提升,于是Intel又在SSE的基础上推出了更先进的SSE2指令集。
SSE2包含了144条指令,由两个部分组成:SSE部分和MMX部分。SSE部分主要负责处理浮点数,而MMX部分则专门计算整数。SSE2的寄存器容量是MMX寄存器的两倍,寄存器存储数据也增加了两倍。在指令处理速度保持不变的情况下,通过SSE2优化后的程序和软件运行速度也能够提高两倍。由于SSE2指令集与MMX指令集相兼容,因此被MMX优化过的程序很容易被SSE2再进行更深层次的优化,达到更好的运行效果。
SSE2对于处理器的性能的提升是十分明显的,虽然在同频率的情况下,Pentium 4和性能不如Athlon XP,但由于Athlon XP不支持SSE2,所以经过SSE2优化后的程序Pentium 4的运行速度要明显高于Athlon XP。而AMD方面也注意到了这一情况,在随后的K-8系列处理器中,都加入SSE2指令集。
SSE3:SSE3指令是目前规模最小的指令集,它只有13条指令。它共划分为五个应运层,分别为数据传输命令、数据处理命令、特殊处理命令、优化命令、超线程性能增强五个部分,其中超线程性能增强是一种全新的指令集,它可以提升处理器的超线程的处理能力,大大简化了超线程的数据处理过程,使处理器能够更加快速的进行并行数据处理。 上面介绍的基本上就是Intel和AMD公司在X86架构处理器上主要的扩展指令集,虽然它们对于处理器的性能提升有着一定程度的帮助,但是由于受到IA-32体系的限制,X86架构基本上不会再有具有革命性意义的指令集出现,而双方都已经把重心转向了64位体系架构的处理器指令集开发上。
AMD64:AMD的athlon 64系列处理器的64位技术是在X86指令集的基础上加入了X86-64的64位扩展X86指令集,这就使得athlon 64系列处理器可兼容原来的32位的X86软件,并同时支持X86-64的扩展64位计算,并且具有64位的寻址能力,使得它成为真正的64位X86构架处理器。在采用X86-64架构的Athlon 64处理器中,X86-64指令集中新增了几组处理器寄存器,它能够提供更加快速的执行效率。
寄存器是处理器用来创建和储存CPU运算结果和其他运算结果的地方,标准的X86构架中包括8组通用寄存器,而在AMD的X86-64架构中又增加了8组,将通过寄存器的数目提高到了16组。在这基础之上,X86-64指令集还另外增加了8组128位的XMM寄存器,也叫做SSE寄存器。
它能够给单指令多数据流技术(SIMD)运算提供更多的存储空间,这些128位的寄存器能够提供在矢量和标量计算模式下进行128位双精度处理,这也为3D数据处理、矢量分析和虚拟技术提供了良好的硬件基础。由于提供了更多的寄存器,按照X86-64标准生产的处理器可以更有效率的处理数据,在一个时钟周期内能够传输更多的信息。
EM64T :EM64T(Extended Memory 64 Technology)也就是Intel公司开发的64位内存扩展技术。它实际上就是Intel IA-32构架体系的扩展,即IA-32E(Intel Architectur-32 Extension)。Intel的IA-32处理器通过加入EM64T技术便可在兼容IA-32软件的情况下,允许软件程序利用更多的内存地址空间,并且允许程序进行32 位线性地址写入1。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国