

数据流概念
传统计算机冯·诺依曼计算机以控制流计算模型为基础, 它是某些计算模型的实现。这种计算机进行计算, 必须规定操作或程序序列以控制机器。近些年来, 已深入研究另外一些计算模型, 如数据流模型。在数据流模型中, 实现操作取决于数据的内部依赖性和资源的可利用性。数据流机单处理单元的框图可说明基本数据流系统结构。如图所示。
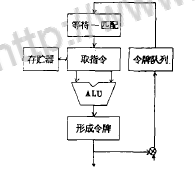
数据流图是一种有向图, 用来表示数据驱动计算。在数据流图中,每个节点表示一个算子。数据和控制被封装在令牌内它在连接节点的弧上流动。当输人令牌出现在节点的所有输人弧上时, 实现操作,也就是说节点被点火。节点点火条件的语句描述称为点火规则。一个节点的点火引起数据和控制新令牌的产生。最终导致进一步计算的发生。
数据流的主要优点有:
(1)发挥了并行性。
(2)用数据流语言写一个程序比较简单。
(3)说明并行控制并不要求程序员了解全部操作和测定数据的内部依赖性, 这样简化了编程。
(4)使通信手段和同步机制成为其系统结构的不可分割部分, 它比现存的机器更可靠。
(5)保证多处理机计算以可重复的方式运行, 而现存的江多处理机不提供这种保证。
(6)解决了存贮等待时间问题,以分阶段方式实现输人存贮。
(7)提高了机器的性能和计算机专业人员的生产率。
数据流系统MIT静态数据流MIT静态结构的框图如图所示。
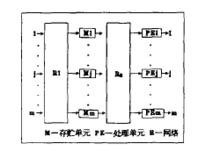
存贮部件分成若干模块, 每个模块保存操作和操作数以及节点的目标地址。如同传统计算机那样, 程序装人存贮器内。被启动的指令通过R2从存贮器送到凡。其结果通过R1从PEs传送到存贮器。当没有指令被启动时, 程序执行完成。用这种结构设计成的系统支持虚存和多用户系统页面调度。这种设计的优点包括指令的显同步和保证多处理机以再现方式运行。静态结构不能最完善地发挥并行性, 因为任何给定时刻任意输人弧上仅有一个令牌。这就禁止不同功能行为和迭代的同时执行。
关联模型数据流系统结构关联模型数据流ATD(Associative model data flow)避免使用令牌作同步工具, 而利用在有效通道上传播的信息修正所有分布控制状态以响应每个操作的执行。关联存贮机制如内容可定址的存贮器用来实现存贮, 对全部修正传送加以监测, 如果修正同关联存贮器的数据单元有关, 那么, 进行修正, 否则, 信息被忽略。
ATD其它最重要的特征是以每个操作为基础,避免争夺共享资源如存贮器读和写缓冲器的争夺。ATD是一种静态系统结构, 它具有静态系统结构的所有优点。在成为一种健壮的计算机模型以前还必须作更进一步的研究和仿真。
P-RISC系统结构并行P-RISC系统结构完全删除了等待和匹配单元, 而对所有操作使用一个RISC状的APU。P-RISC系统结构的主要特性有使用一个RISC状指令集;改变系统结构支持多道计算;加入分叉和联结结构管理多通道;用指令实现完全存贮以分阶段方式实现输人存贮指令。
P-RISC系统结构由一组呢和许多存贮单元组成, 通过一组开关网将他们联结起来。P-RISC没有等待一匹配单元, 取而替之, 它将计算顺序键有关的全部运算数存贮一组存贮器内。为解决存贮器争夺问题以分阶段方式实现输人存贮指令。在等待输人结果到达时, 处理器不封锁,它仅仅执行下一条被启动的指令。每当输人到达, 中止的指令将再被启动并且, 最终将平稳地执行。每个现存的程序都能在P-RISC上执行, 这一事实总结了这种系统结构的优点, 此外, 它还保持数据流机发挥并行性方面的优点。
数据流计算数据流计算来自于一个概念:数据的价值随着时间的流逝而降低,所以事件出现后必须尽快地对它们进行处理,最好数据出现时便立刻对其进行处理,发生一个事件进行一次处理,而不是缓存起来成一批处理。例如商用搜索引擎,像Google、Bing和Yahoo 等,通常在用户查询响应中提供结构化的Web结果,同时也插入基于流量的点击付费模式的文本广告。为了在页面上最佳位置展现最相关的广告,通过一些算法来动态估算给定上下文中一个广告被点击的可能性。上下文可能包括用户偏好、地理位置、历史查询、历史点击等信息。一个主搜索引擎可能每秒钟处理成千上万次查询,每个页面都可能会包含多个广告。为了及时处理用户反馈,需要一个低延迟、可扩展、高可靠的处理引擎。
对于这些实时性要求很高的应用,若把持续到达的数据简单地放到传统数据库管理系统(DBMS)中,并在其中进行操作,是不太切实的。传统的DBMS并不是为快速连续的存放单独的数据单元而设计的,而且也并不支持“持续处理”,而“持续处理”是数据流应用的典型特征。另外,现在人们都认识到,“近似性”和“自适应性”是对数据流进行快速查询和其他处理(如数据分析和数据采集)的关键要素,而传统DBMS的主要目标恰恰与之相反:通过稳定的查询设计,得到精确的答案。
另外一些方案是采用MapReduce来进行实时数据流处理。但是,尽管MapReduce做了实时性改进,仍然很难稳定地满足应用需求。这是因为MapReduce(Hadoop)框架为批处理做了高度优化,系统典型地通过调度批量任务来操作静态数据,任务不是常驻服务,数据也不是实时流入;而数据流计算的典型范式之一是不确定数据速率的事件流流入系统,系统处理能力必须与事件流量匹配。
最近Facebook在SIGMOD’ 2011上发表了利用Hbase/Hadoop进行实时处理数据的论文,通过一些实时性改造,让批处理计算平台也具备实时计算的能力。这类基于MapReduce流式处理的特点有三:
1)将输入数据分隔成固定大小的片段,再由MapReduce平台处理,缺点在于处理延迟与数据片段的长度、初始化处理任务的开销成正比。小的分段会降低延迟,增加附加开销,并且分段之间的依赖管理更加复杂(例如一个分段可能会需要前一个分段的信息);反之,大的分段会增加延迟。最优化的分段大小取决于具体应用。
2)为了支持流式处理,MapReduce需要被改造成Pipeline的模式,而不是reduce直接输出;考虑到效率,中间结果最好只保存在内存中等等。这些改动使得原有的MapReduce框架的复杂度大大增加,不利于系统的维护和扩展。
3)用户被迫使用MapReduce的接口来定义流式作业,这使得用户程序的可伸缩性降低。
综上所述,流式处理的模式决定了要和批处理使用非常不同的架构,试图搭建一个既适合流式计算又适合批处理的通用平台,结果可能会是一个高度复杂的系统,并且最终系统可能对两种计算都不理想。
数据流计算有两种不同方法。第一种方法是数据驭动法, 一旦操作要求的全部输人数据是有效的,操作被点火。另一种方法是需求驱动法,仅当某些操作需要它的结果时,操作被点火,必要时进行计算。这样避免了许多冗余计算, 从而减少了循环的令牌数。但大量研究已集中在数据驱动上,这种计算是两种方法中不太复杂的一种。1
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国