

基本概念
数据处理已迅速普及到工业、商业和刷一会的各个领域,不过由于受到软件发展的限制,还不能进一步发展。但是,在科学技术的应用上,计算机还有严重的缺点,即使是现有的大型计算机系统,在计算效率上还差几个数量级。要想适应新的问题推的需要,使计算效率有根木的提高,那就只有呆用一种绝然不同的计算机体系结构,以摆脱指令和数据串行处理的“冯诺依曼瓶预”,当然还要改变现行的程序设计语言。计算机体系结构,如以并行处理原理为基础,在结构上就具有把计算效率提高到必要量级的潜在可能性。
并行处理器指可以一次可处理多个运算的处理器。双核处理器也是并行处理器,因为其一次可运行两个运算(以此类推),但其本质上还是串行处理器的组合,所以提起并行处理器,一般指经特殊设计的多线程处理器。
国内外并行处理器发展现状Stanford大学的Imagine流处理器。它的主要计算结构为8个SIMD(Single Instruction Multiple Date)模式工作的处理单元簇。处理单元簇使用VLIW(Very Long Instruction word)方式控制,其特点是利用长指令对多个功能单元同时操作,达到并行的目的,VLIW有助于发掘ILP(Instruction Level Parallel)。另一方面,利用SIMD发掘DLP(Data Level Parallel)。 Imagine使用了3级存储器层次结构,并在数据流控制上提出来流处理的概念,缓解了处理器对外存带宽的依赖。
Motorola Labs主持研制的RSVP流处理器与Imagine有些区别。RSVP只有一组功能单元,每个功能单元64位,可以划分为最多4个片(slice),每一组slice有自己的控制流,所以RSVP是一个MIMD(Multiple Instruction Multiple Date)结构。
国内的流处理器主要由国防科技大学研究。其提出了X流处理器,FT64和MASA。这3种流处理器结构类似,都是以Imagine为基础加以改进的设计。其中MASA-I实现了与Imagine的指令兼容,而X流处理器、FT64实现了双精度浮点科学运算。
GPU也是一种典型的并行处理器。在应用方面GPU偏重于数据并行和任务级并行,因此GPU中一般将8一16个处理单元组合成一个SIMD模块,每个处理单元包含1个或多个运算单元。整体采用多个这样的SIMD模块组合成MIMD以更好地支持任务级并行。如NVIDIA的Fermi处理器,比起上一代的GT200系列处理器,Fermi采用了超标量的结构,一个时钟可以向计算阵列发射2~4条指令,同时Fermi开始支持可读写的数据Cache。与NVIDIA不同,AMD的HD5000系列处理器没有采用超标量的结构,而是采用了VLIW技术,最多可以同时在每个SIMD阵列执行5条指令。SIMD模块间通讯方式前者主要采用L2 Caehe或者片外存储器,后者还可以使用一块较小的全局片上存储器通讯。通过对GPU的组织可以发现,本应注重数据级并行的GPU也开始使用一些CPU的技术来提高指令并行性和通用计算能力,进一步提升性能1。
并行处理器结构并行处理器结构图如图所示:

这种系统有N个处理部件(PE),M个主存存赊体(M个内存模块)和一些或者N个控制部件(CU)以及输入/输出通道;最重要的系统部件是互速网络,它可以使各个部件进行数据或按制信号方面的通信。
并行处理系统所有的并行处理系统均可视为以处理器为节点的网络。设计并行处理时必须考虑许多问题,其中的两个重要问题是处理系统的网络拓扑结构和节点处理器的设计。高速数字信号处动系蛛属于专用机,其拓扑结构和节点设计与所要实现的算法有密切的关系,且对其通用性不需要而且也不应该有很高的要求(通用机有很高的通用性,但相应地有很大的管现开销)。良好的专用并行处理系统应具有如下一些共同特点。
(1)模块化处理系统由种类不多的模块组成。这既便于节点及通讯硬软件设计,又便子系统的扩展,而且也降低了系统的复杂性;
(2)流水处理这可以大大提高处理速度,是并行系统必须具有的特点之一;
(3)局域性这包括局域的数据流和控制流。由于无论在芯片级还是系统级,通讯问题均是关键,因而局域性非常重要。
并行处理系统的框图如图:
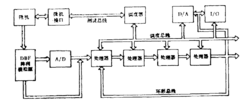
处理系统的中心部分由一个调度器及四个处理器组成,系统设计成可以很易扩展其处理器的数量,系统还包含A/D、D/A及串口和并口。系统的重构通过对调度器和其它处理器的软件设置实现。系统可设置成线性、环形、星形、车轮形等各种结构形式,以适于多种应用。
调度器亦是一个处理器,用于系统的调度和控制,也可完成一定的处理运算。它主要用于向处理器发出各种控制命令,控制调度总线的复用,转发微机和各处理器之间的控制和数据。所有程序和初始数据均由微机产生,再经由调度器转至各处理器。要显示打印的结果亦由调度器转至微机。
系统的运算主要由处理器完成。现系统有 个接水上一样的处理器,只是在第一个处理器中加入FIFO,用于作为输入数据通道。处理器的组成如图:
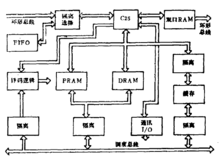
系统共有三种总线: 测试总线、调度总线和环形总线。测试总线用于传输微机和处理系统间的数据、微机向处理系统传送程序、初始化信息及控制命令;调度总线完成调度器和其余处理器的信息传输;环形总线将四个处理器连接成环形结构2。
并行处理器是实时实现许多需要完成复杂计算(如矩阵计算)的数字信号处理系统的不可避免的选择。
并行处理器系统的种类如果按性质来进行分类,则有些处理器是模凌两可的:既可算作这一类,又可算作另一类;按照费林的意见,又可分为单指命流多数据流系统和多指令流多数据流系统。这里列出的只是一些重要的应算作并行处理器的系统3:
(1)向量/流水线处理器:
STAR-100(CDC公司)
CYBER 203/205(CDC公司)
T1-ASC(德克萨斯仪表公司)
Cray-1(克雷研究公司)
(2)并行处理器系统
ILLIAC IV(依里诺斯大学,布劳斯公司)
SOLOMOM(西屋公司)
PEPE(贝尔实验室、布劳斯公司系统发展公司)
BSP(布劳斯公司)
DAP(ICL公司)
CHOPP(哥伦比亚大学;苏里万学会)
C.mmp.Cm(卡内其/梅隆大学)
T16(Tandem公司)
EGPA(埃尔朗根/诺尔贝尔格大学)
(3)相联处理器
STARAN(古得依尔宇航公司)
ECAM(霍尼威尔公司)
OMEN(商特尔公司)
ALAP(休斯飞机公司)
(4)算法数组处理器(流水线计算机)
IBM 2938/3835(IBM公司)
MAP III(数据控制公司)
UAP(尤尼瓦克公司)
AP-120B/190L(浮点系统公司)
FPS-164(浮点系统公司)
ATP(Datawest公司)
基于并行处理器的快速车道线检测系统如图为本文提出的并行快速车道线检测片上系统的构架图。
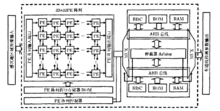
它包含一个32X32的PE阵列、阵列程序存储器ROM和阵列控制器、双RISC核子系统、仲裁器和多路选择器MUX等模块。PE阵列包含有阵列输入和输出端口。整个阵列构成一个并行单指令多数据(SIMD)系统,在阵列控制器的控制下,通过阵列程序存储器ROM供给指令,实现各种图像并行预处理。双RISC核子系统则有两个RISC处理器及相应的指令存储器ROM和数据存储器RAM构成,它们通过AHB总线互联。双RISC核通过仲裁器控制多路选择器MUX,实现和PE阵列以及外部的互连。双RISC核子系统从PE阵列获取图像预处理结果并行进行高级图像处理,并将处理结果通过多路选择器MUX输出。PE阵列控制器和双RISC子系统之间能够互相通信,实现PE阵列并行处理和双RISC核并行处理之间的同步,从而使整个系统协调一致工作。
这个系统充分考虑检测过程图像处理的并行特征。基于图像处理的检测过程,包含有大数据量低复杂度的图像预处理和小数据量高复杂度的高级图像处理。图像预处理是由整块图像所有像素共同参与的过程,呈现出数据量的庞大,而每个像素的处理仅仅是和相邻像素之间按一定权重因子的加减运算,属于低复杂度的局部运算。因而图像预处理是一个适合于2维并行的处理。本系统中,采用PE阵列的2维并行结构来实现图像的预处理,从而显著提高图像预处理的速度。而高级图像处理实现检测的过程,是基于预处理结果获取的特征信息,因而数据量大为减小,且数据量之间相关性不大,需要做各种变换,涉及多次的乘法,查询,统计,排序等4。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国