

模糊联想记忆(Fuzzy Associative Memory,简称FAM)即通过一定的对应关系将一个论域中的模糊子集映射到另一个论域中,即要将一个立方体映射到另一个立方体,这种映射关系叫做“联想记忆”,在模糊系统里具体称为模糊联想记忆。模糊联想记忆模型是一个两层前馈异联想模糊分类器,或者说是一个模糊映射系统。
模糊联想记忆模型模糊联想记忆(FAM)模型( Kosko , 1991)是一个两层前馈异联想模糊分类器,或者说是一个模糊映射系统。如图1所示,输入为模糊变量A,它是一个n维矢量,通过m条规则,映射到p维模糊矢量B上。FAM系统通过学习可存储任意模糊空间模式对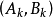 ,用模糊集表达的第k个模式对为:
,用模糊集表达的第k个模式对为:
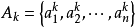
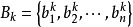
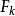 为:
为:
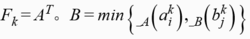
这里,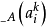 是模糊变量A中第i个元素的隶属度,
是模糊变量A中第i个元素的隶属度,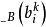 是模糊变量B中第i 个元素的隶属度,“。”表示合成运算, 是一个n×p的模糊矩阵。在FAM中, 代表了第k 条推理规则,它是蕴函句" If X is
是模糊变量B中第i 个元素的隶属度,“。”表示合成运算, 是一个n×p的模糊矩阵。在FAM中, 代表了第k 条推理规则,它是蕴函句" If X is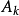 then Y is
then Y is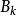 "的简写形式。FAM规则也可表达多前提规则,如
"的简写形式。FAM规则也可表达多前提规则,如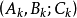 ,即表示"If X is and Y is then Z is
,即表示"If X is and Y is then Z is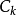 "。
"。
每一条规则都对应了一个模糊矩阵 ,各条规则独立存放在FAM系统中,这样做的好处是可以灵活方便地增、删或修改规则,在推理时又可以清楚地了解FAM系统中每条规则对输出模糊矢量B的贡献是多少1。
由FAM学习网络得到的规则可供FAM推理机进行推理。
如图1所示,若在FAM系统中有m条规则,输入为一个P维的模糊矢量A(通常输入为确切的数值,需经模糊化处理)。它不同程度地并行激活相应的FAM规则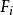 ,并得到输出
,并得到输出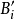 ,这样,m条规则可能产生m个子结论
,这样,m条规则可能产生m个子结论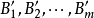 。将m 个子结论按下式进行归一化加权求和便得到FAM的最后输出B
。将m 个子结论按下式进行归一化加权求和便得到FAM的最后输出B

其中, 权系数 反映了第k条规则在推理或联想中的强度值,最后经过去模糊化得到具体的数值
反映了第k条规则在推理或联想中的强度值,最后经过去模糊化得到具体的数值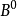 。通常去模糊化(清晰化)方法一般有两种:
。通常去模糊化(清晰化)方法一般有两种:
(1)最大隶属函数法
若以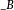 表示B的隶属函数,则按峰值法确定的数值 为
表示B的隶属函数,则按峰值法确定的数值 为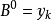 。其中,
。其中,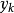 满足
满足
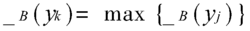
最大隶属函数法存在两个主要问题:第一, 当 的形状有多个等高峰值时,按上式求得 的不唯一;第二,该方法在很大程度上忽略了 形状所包含的信息。
(2)重心法
与最大隶属函数法相比较,重心法注重的不是 的峰值,而是 的整个形状。这时 为
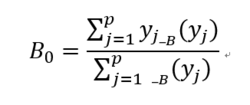
一个模糊联想记忆网络2用于存储p个模糊模式对 ,k =1 , … ,p,其中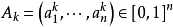 ,
,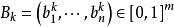 。网络的拓扑结构如图所示,图中的
。网络的拓扑结构如图所示,图中的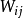 为第i个输人神经元到第j个输出神经元之间的连接权,其值也在(0,1)范围内。对于由最大一最小合成神经元组成的模糊联想记忆网络,完整的模式对回想意味着存在连接权矩阵W使下式成立
为第i个输人神经元到第j个输出神经元之间的连接权,其值也在(0,1)范围内。对于由最大一最小合成神经元组成的模糊联想记忆网络,完整的模式对回想意味着存在连接权矩阵W使下式成立
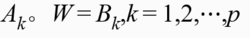
式中“ 。”表示最大-最小合成运算,上式实际上为一组最大-最小合成模糊关系方程,因此,确定模糊联想记忆网络的连接权矩阵W,也就是求解模糊关系方程组。直观地,连接权矩阵W可由下式求出
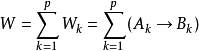 式中“
式中“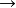 ”表示某种蕴涵运算,中间矩阵用于记录第k个模式对联想
”表示某种蕴涵运算,中间矩阵用于记录第k个模式对联想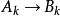 。
。
当给网络提供输入模式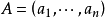 时,网络用最大一最小合成运算回想出输出模式
时,网络用最大一最小合成运算回想出输出模式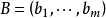 ,用逐点方式可表示为
,用逐点方式可表示为

式中“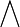 ” 表示最小运算, “
” 表示最小运算, “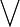 ” 表示最大运算。
” 表示最大运算。
Kosko采用最小蕴涵将第k个模式对 编码到中间矩阵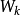 中, 然后用最大叠加运算将p个 组合到连接权矩阵W中。用逐点方式,模糊赫布规则可表示为
中, 然后用最大叠加运算将p个 组合到连接权矩阵W中。用逐点方式,模糊赫布规则可表示为
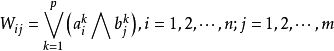
从上述式子可以看出,对于任意的输入模式A,回想出的模式B总是下边模式的子集:
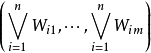
(1)都是model-free
(2)都可以从样本或实例中学习
(3)都使用数值运算
不同点(1)所用的样本形式不同
(2)存储的形式不同
(3)如何联想(推理)或如何把输入映射到输出的方式不同
应用FAM模糊神经网络的使用,在实际进行学习时还需注意如下几点:
(1)输入、输出语言值集合的划分应根据样本的群集情况,划分时要尽可能将群集的样本划在一个虚规则区域内。
(2)竞争突触向量数目q应大于虚规则数。通常q太大时,学习迭代时间长;q过小时,结论重复性差。实际学习时可取q=1~2N ,这里N为学习样本数。
(3)学习次数n对学习结果也有一定影响。 n太大时,学习时间长;n太小时,结论重复性差,通常应选取n≥ 1000次。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国