

在采用贝叶斯公式来估计后验概率P(c|x)的主要困难是:类条件概率P(x|c)是所有属性上的联合概率,难以从有限的训练样本直接估计得到。
为了避开这个障碍,朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。
但在现实任务中,这个假设往往很难成立,于是人们尝试对属性条件独立性假设进行一定程度的放松,由此产生了一类“半朴素贝叶斯分类器”的学习方法。1
正则化在朴素贝叶斯中,计算联合概率时,为了避免其他属性携带的信息被训练集中从未出现的属性值“抹去”,在估计概率值时通常要进行“平滑”,常用“拉普拉斯修正”。具体来说,令N表示训练集D中可能的类别数,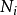 表示第i个属性可能的取值数,则1
表示第i个属性可能的取值数,则1
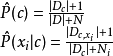
半朴素贝叶斯的基本思想是:适当考虑一部分属性间的相互依赖信息,从而既不需要进行完全联合概率计算,又不至于彻底忽略了比较强的相互依赖关系。“独依赖估计”是半朴素贝叶斯分类器中最常用的一种策略。顾名思义,所谓“独依赖”,就是假设每个属性在类别之外最多依赖于一个其他属性。1
最直接的做法是假设所有属性都依赖于同一个属性,称为“超父”(super-parent),然后通过交叉验证等模型方法来确定超父属性,由此形成了SPODE(Super-Parent ODE)方法。
TAN(Tree Augmented naive Bayes)则是在最大带权生成树(maximum weighted spanning tree)的基础上,通过以下步骤将属性间依赖关系约简为如图所示(c)的树形结构:
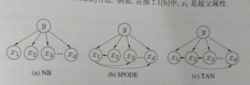
上图是朴素贝叶斯与两种半朴素贝叶斯分类器所考虑的属性关系,其中,(a)是NB,(b)是SPEDE,(c)是TAN
步骤:
1)计算两个属性之间的条件互信息(conditional mutual information)
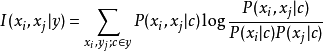
2)以属性为结点,构建完全图,任意两个结点之间边的权重设为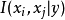
3)构建此完全图的最大权生成树,挑选根变量,将边置为有向。
4)加入类别结点 y,增加从 y 到每个属性的有向边。
容易看出,条件互信息刻画了属性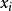 和
和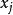 在已知类别情况下的相关性,因此,通过最大生产树算法,TAN实际上保留了强相关属性之间的依赖性。
在已知类别情况下的相关性,因此,通过最大生产树算法,TAN实际上保留了强相关属性之间的依赖性。
贝叶斯网络亦称“信念网”,它借助有向无环图来刻画属性之间的依赖关系,并使用条件概率表来描述属性的联合概率分布。1
具体来说,一个贝叶斯网B由结构G和参数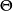 两部分构成,即
两部分构成,即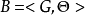 。网络结构G是一个有向无环图,其每个结点对应一个属性,若两个属性有直接依赖关系,则它们由一条边连接起来;参数定量描述这种依赖关系。假设属性在G中的父结点集为
。网络结构G是一个有向无环图,其每个结点对应一个属性,若两个属性有直接依赖关系,则它们由一条边连接起来;参数定量描述这种依赖关系。假设属性在G中的父结点集为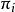 ,则包含了每个属性的条件概率表
,则包含了每个属性的条件概率表
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国