

训练数据(Train Data)即数据挖掘过程中用于数据挖掘模型构建的数据。在数据挖掘过程中,除了训练数据还有测试数据(Test Data),即用于检测模型构建,此数据只在模型检验时使用,用于评估模型的准确率。绝对不允许用于模型构建过程,否则会导致过渡拟合。验证数据(Validation Data):可选,用于辅助模型构建,可以重复使用。当数据集较小,会采用一些方法来来弥补这个缺点,如自助法。
数据挖掘数据挖掘(Data mining)是一个跨学科的计算机科学分支。数据挖掘有以下这些不同的定义:
“从数据中提取出隐含的过去未知的有价值的潜在信息”1,
“一门从大量数据或者数据库中提取有用信息的科学”。
数据挖掘运行是使用数据挖掘的设置对数据挖掘模型的计算。数据挖掘标准依据数据挖掘技术可 处理运行的过程,提出并规范了通常所用的四个计 算阶段:
(1)训练阶段(training phase): 2这是所有数据挖掘技术公用的,用于计算数据挖掘模型的阶段。该 阶段在建立模型前需要准备数据并做预处理。在预 处理时要定义识别字段分配给有关的信息,如挖掘 类型和特定的控制字段。在分类和回归技术中用的 训练阶段还要有一个确认处理,称确认阶段,作为 数据挖掘分类和回归技术训练阶段的一部分。它给数据挖掘模型输入另外的数值组,可作为测试阶段 的描述,其结果作为实例以决定运算法则结束时间。
(2)模型自查阶段(model introspection phase): 也是所有数据挖掘技术普遍使用,用以解释和评估 模型。将模型与目标一起细查,揭示训练阶段中数 据的相关性,以期达到两个目的: ①找出数据中潜 在的规律,有助于进一步解释模型; ②找出有统计 价值的特性,有助于评估模型的质量。
(3)测试阶段(testing phase): 只用于分类和回 归。测试时为模型的对象字段读入系列数值组,在 应用中评估每个数值组,将预测数值和对象字段里 的实际数值做比较,其结果可为使用者或应用提供 实例,以此决定模型以质量为基础能否应用于实际。
(4)应用阶段(application phase): 模型应用期间 输入数据组用来评估模型,或用较多的数据组来计 算模型。为了能正确地使用模型的输入值,必须将 其分配到训练阶段确认的相关字段中。一个预定课 题的模型应用,产生一个表可以控制相关的其他课 题。模型由一个或多个规则的特定输入而得出推论, 推论结果可与附加特性一并提交。特定情况下,推 论是对模型可信度的支持。
这几个阶段不是一次完成的,数据挖掘运行当 包括训练阶段时调用训练阶段运行,当包括测试阶 段时调用测试阶段运行。其中某些阶段要反复多次, 各项功能也不是独立实现的,有时要几种方法互相 联系才能发挥作用。
自助法自助法由Bradley Efron于1979年在《Annals of Statistics》上发表。是以自助采样(bootstrap sampling)为基础。给定包含m个样本的数据集D,我们对它进行采样产生数据集 D′:每次随机从D中挑选出一个样本,将其拷贝放入D′, 然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采样到;这个过程重复执行m次后,我们就得到可包含m个样本数据的数据集D′,这就是自助采样的结果.样本在m次采样中始终不被采到到概率为
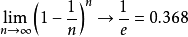
由此可知通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D′中。于是我们可将D′ 用作训练集,D∖D′用作测试集。
优缺点:自助法在数据集较小,难以有效划分训练/测试集时很有用,但是,自助法改变了初始数据集的分布,这会引入估计偏差,所以在数据量足够时,一般采用留出法和交叉验证法。3

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国