

决策树归纳法根据数据的值,把数据分层组织成树型结构,即用树形结构来表示决策集合,这些决策集合通过对数据集的分类产生规则。在决策树中每一个分支代表一个子类,树的每一层代表一个概念。1
决策树归纳法一般以方框和圆圈为结点,并由直线连接而成的一种像树枝形状的结构。方框结点叫做决策点,由决策点引出若干条树枝(直线)。每条树枝代表一个方案,故叫方案枝。在每个方案枝的末端画上一个圆圈就是圆圈结点,圆圈结点叫做机会点。由机会点引出若干条树枝(直线),每条树枝为概率枝。在概率枝的末端列出不同状态下的收益值或损失值。2
DTI常用于分析构建模型的可行性与可信度,相应地根据观察推出其逻辑表达式及结构,通过其简单清晰的逻辑推理和分割信息值,能够快捷地对大数据集进行高效的数据划分。但针对连续型数据和多类别集合,划分效率就会随复杂度的升高而降低。3
DTI算法原理决策树归纳法( GTI) 是一组规则集合,使用递归的方式将训练样本集( TS) 划分成更小的子集合(Sub-TS) ,直到每一个子集合拥有独有的所属类别标签。
DTI算法通常采用信息论(IT)作为属性选择方法,根节点TS的选择是基于训一算出的所具有最高信息增益的属性。给定一个N维训练样本集T={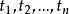 },
},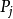 表示样本实例
表示样本实例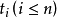 属于类别
属于类别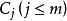 的先验概率,可根据下式得出对给定的样本实例进行分类所需要的期望信息Info(T)。
的先验概率,可根据下式得出对给定的样本实例进行分类所需要的期望信息Info(T)。
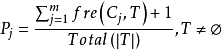
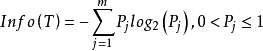
相应地,训练样本集T根据属性A={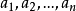 }迭代地被划分成N个不同的子集合{
}迭代地被划分成N个不同的子集合{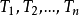 },其中
},其中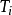 为样本集合T中属性A=
为样本集合T中属性A=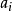 时的样本子集合。可根据权重值
时的样本子集合。可根据权重值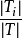 计算出属性A划分T的期望信息,从而根据原始信息要求Info (T)和新的信息要求的偏移量计算得出信息增益InfoGain(A)。根据样本集T中的属性值,逐一地计算出每个属胜值对T进行划分的信息增益,从中选择出具有最高信息增益的属性
计算出属性A划分T的期望信息,从而根据原始信息要求Info (T)和新的信息要求的偏移量计算得出信息增益InfoGain(A)。根据样本集T中的属性值,逐一地计算出每个属胜值对T进行划分的信息增益,从中选择出具有最高信息增益的属性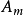 。作为最佳属性来划分子集合,递归整个过程直到所有集合都被正确归类。3
。作为最佳属性来划分子集合,递归整个过程直到所有集合都被正确归类。3
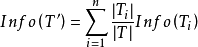
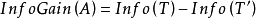
程序名:DTI
samples代表以离散值属性表示的训练样本,attribute_list指候选属性集合。
(1) 建立一节点N;
(2) 若samples含相同分类c,则:
(3) 返回N表示含c类的叶节点;
(4) 若attribute_list为空集合则:
(5) 返回N含samples中最大类的叶节点;
(6) 选test_ attribute,即attribute_ list中含最大信息增益的属性;
(7) 将节点N标记为test attribute;
(8) 对test attribute的每一已知值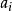 分割样本;
分割样本;
(9) 由节点N产生一分支表示test attribute=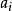 ;
;
(10) 令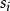 为samples中test_attribute=
为samples中test_attribute=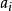 的样本集合;
的样本集合;
(11) 若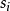 为空集合,则:
为空集合,则:
(12) 新增一叶节点且标记以samples中最大类;
(13) 否则新增一节点(由DTI(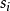 ,attribute_ list,test_attribute)产生)。
,attribute_ list,test_attribute)产生)。
树由一单一节点表示训练样本开始(步骤 1),若样本含相同类,则节点为叶且注标为此类(步骤 2、 3); 否则,算法使用系统乱度导向称为信息增益法为经验法则,以选出最能将样本分成两类的属性(步骤 6)。该属性变成该节点的“测试”或“决策”属性(步骤 7)。算法的各属性均被分类, 每一测试属性的已知值建立一分支,样本依此被分割(步骤 8-10)。 算法以递归式形成样本中每一分割而成决策树。节点产生一属性后,则不需考虑该节点的子孙(步骤 13)。当满足下列条件时停止递归:
(a) 样本的任一已知节点皆属于某一固定类(步骤 2、3)或
(b) 样本中没有其它属性可供进一步分割(步骤 4),此时,引用胜者攘括(步骤 5),将该节点转换成叶节点且标记为胜者的类别,否则储存该节点的类分布。
(c) 分支 test_attribute=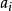 (步骤 11)无样本。此时,叶依据样本中主要类别建立(步骤 12)。
(步骤 11)无样本。此时,叶依据样本中主要类别建立(步骤 12)。
树中每一节点所选的测试属性均以信息增益加以衡量,这种衡量称为属性选择度量或度量一完善的分割。含最高信息增益的属性(或最大量的减少)被选为该节点的测试属性。该属性能将样本分类所需信息最小化,且使分类所含杂质最小化。这种信息论方法使分割对象所需测试最小化且保证能得到一简化树。4
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国