

基本概念
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。不含任何元素的栈称为空栈。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素1。
如图1所示:假设一个栈S中的元素为 ,则称a1为栈底元素,an为栈顶元素。
,则称a1为栈底元素,an为栈顶元素。
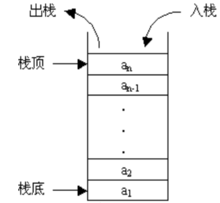 图1
图1
栈地址是指栈顶的地址。在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
栈与栈地址的操作栈是由系统自动分配和回收的内存。如一个子函数被调用时,系统会将函数内的局部变量的内存单元分配到栈上,当函数执行完毕时系统自动释放所分配的栈地址单元。栈的修改是按后进先出的原则进行的。栈又称为后进先出(Last In First Out)表,简称为LIFO表。
在计算机系统中,栈则是一个具有以上属性的动态内存区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。在i386机器中,栈顶由称为esp的寄存器进行定位。压栈的操作使得栈顶的地址增大,弹出的操作使得栈顶的地址减小。
栈和栈地址的特点以下是栈和栈地址在程序运行中的特点:
(1)栈经常与 sp 寄存器一起工作,最初 sp 指向栈顶(栈的高地址),即栈地址。
(2)CPU 用 push 指令来将数据压栈,用 pop 指令来弹栈。当用 push 压栈时,sp 值减少(向低地址扩展)。当用 pop 弹栈时,sp 值增大。存储和获取数据都是 CPU 寄存器的值。
(3)当函数被调用时,CPU使用特定的指令把当前的 IP 压栈。即执行代码的地址。CPU 接下来将调用函数地址赋给 IP ,进行调用。当函数返回时,旧的 IP 被弹栈,CPU 继续去函数调用之前的代码。
(4)当进入函数时,sp 向下扩展,扩展到确保为函数的局部变量留足够大小的空间。如果函数中有一个 32-bit 的局部变量会在栈中留够四字节的空间。当函数返回时,sp 通过返回原来的位置来释放空间。
(5)如果函数有参数的话,在函数调用之前,会将参数压栈。函数中的代码通过 sp 的当前位置来定位参数并访问它们。
(6)函数嵌套调用和使用魔法一样,每一次新调用的函数都会分配函数参数,返回值地址、局部变量空间、嵌套调用的活动记录都要被压入栈中。函数返回时,按照正确方式的撤销。
(7)栈要受到内存块的限制,不断的函数嵌套/为局部变量分配太多的空间,可能会导致栈溢出。当栈中的内存区域都已经被使用完之后继续向下写(低地址),会触发一个 CPU 异常。这个异常接下会通过语言的运行时转成各种类型的栈溢出异常。
栈地址的分配栈的分配和释放可以这样子理解:栈内存块在计算机中不可能会移动,它的地址已经被固定。系统分不分配它,它就在那里。当为局部变量分配栈内存时,系统就将局部变量存入到栈的某个内存块中;当子函数运行结束局部变量应当被释放时,系统再将这些存入局部变量的栈内存中的数据清除掉,恢复原来没有被初始化的状态。
在函数调用时,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向函数的返回地址,也就是主函数中的下一条指令的地址,程序由该点继续运行。
栈、堆、静态存储区和常量存储区在C++中,内存分成4个区,他们分别是堆、栈、静态存储区和常量存储区。下面是四个区的特点与区别:
(1)栈:就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
(2)堆:又叫自由存储区,它是在程序执行的过程中动态分配的,它最大的特性就是动态性。堆就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
(3)静态存储区:所有的静态对象,全局对象都于静态存储区分配。
(4)常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。常量字符串都存放在静态存储区,返回的是常量字符串的首地址。
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国