

概述
最大似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。这个方法最早是遗传学家以及统计学家罗纳德·费雪爵士在1912年至1922年间开始使用的。
“似然”是对likelihood 的一种较为贴近文言文的翻译,“似然”用现代的中文来说即“可能性”。故而,若称之为“最大可能性估计”则更加通俗易懂。
最大似然法明确地使用概率模型,其目标是寻找能够以较高概率产生观察数据的系统发生树。最大似然法是一类完全基于统计的系统发生树重建方法的代表。该方法在每组序列比对中考虑了每个核苷酸替换的概率。
例如,转换出现的概率大约是颠换的三倍。在一个三条序列的比对中,如果发现其中有一列为一个C,一个T和一个G,我们有理由认为,C和T所在的序列之间的关系很有可能更接近。由于被研究序列的共同祖先序列是未知的,概率的计算变得复杂;又由于可能在一个位点或多个位点发生多次替换,并且不是所有的位点都是相互独立,概率计算的复杂度进一步加大。尽管如此,还是能用客观标准来计算每个位点的概率,计算表示序列关系的每棵可能的树的概率。然后,根据定义,概率总和最大的那棵树最有可能是反映真实情况的系统发生树。1
原理给定一个概率分布D,假定其概率密度函数(连续分布)或概率聚集函数(离散分布)为fD,以及一个分布参数θ,我们可以从这个分布中抽出一个具有n个值的采样X1,X2,...,Xn,通过利用fD,我们就能计算出其概率:
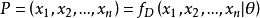 但是,我们可能不知道θ的值,尽管我们知道这些采样数据来自于分布D。那么我们如何才能估计出θ呢?一个自然的想法是从这个分布中抽出一个具有n个值的采样X1,X2,...,Xn,然后用这些采样数据来估计θ。
但是,我们可能不知道θ的值,尽管我们知道这些采样数据来自于分布D。那么我们如何才能估计出θ呢?一个自然的想法是从这个分布中抽出一个具有n个值的采样X1,X2,...,Xn,然后用这些采样数据来估计θ。
一旦我们获得,我们就能从中找到一个关于θ的估计。最大似然估计会寻找关于 θ的最可能的值(即,在所有可能的θ取值中,寻找一个值使这个采样的“可能性”最大化)。这种方法正好同一些其他的估计方法不同,如θ的非偏估计,非偏估计未必会输出一个最可能的值,而是会输出一个既不高估也不低估的θ值。
要在数学上实现最大似然估计法,我们首先要定义可能性:
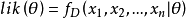 并且在θ的所有取值上,使这个函数最大化。这个使可能性最大的值即被称为θ的最大似然估计。1
并且在θ的所有取值上,使这个函数最大化。这个使可能性最大的值即被称为θ的最大似然估计。1
性质泛函不变性(Functional invariance)如果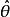 是 θ的一个最大似然估计,那么α =g(θ)的最大似然估计是
是 θ的一个最大似然估计,那么α =g(θ)的最大似然估计是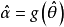 。函数g无需是一个——映射。1
。函数g无需是一个——映射。1
渐近线行为最大似然估计函数在采样样本总数趋于无穷的时候达到最小方差(其证明可见于Cramer-Rao lower bound)。当最大似然估计非偏时,等价的,在极限的情况下我们可以称其有最小的均方差。对于独立的观察来说,最大似然估计函数经常趋于正态分布。1
偏差最大似然估计的非偏估计偏差是非常重要的。考虑这样一个例子,标有1到n的n张票放在一个盒子中。从盒子中随机抽取票。如果n是未知的话,那么n的最大似然估计值就是抽出的票上标有的n,尽管其期望值的只有(n + 1) / 2。 为了估计出最高的n值,我们能确定的只能是n值不小于抽出来的票上的值。1
最大似然估计的一般求解步骤基于对似然函数L(θ)形式(一般为连乘式且各因式>0)的考虑,求θ的最大似然估计的一般步骤如下:
(1)写出似然函数
总体X为离散型时:
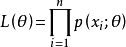
总体X为连续型时:
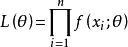
(2)对似然函数两边取对数有
总体X为离散型时:
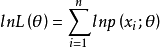
总体X为连续型时:
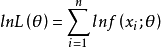
(3)对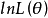 求导数并令之为0:
求导数并令之为0:
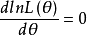
此方程为对数似然方程。解对数似然方程所得,即为未知参数 的最大似然估计值。1
例题设总体X~N(μ,σ2),μ,σ为未知参数,X1,X2...,Xn是来自总体X的样本,X1,X2...,Xn是对应的样本值,求μ与σ2的最大似然估计值。1
**解:**X的概率密度为
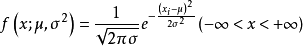
可得似然函数如下:
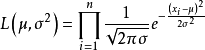
取对数,得
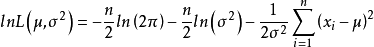
令
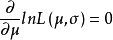
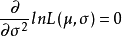
解得
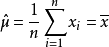
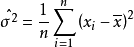
故μ和σ的最大似然估计量分别为
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国