

最近,AI英雄榜又喜迎一位重量级新成员。在大家逐渐接受了人工智能“阿尔法狗”(AlphaGo)先后完虐人类两大顶尖棋手李世石和柯洁的事实,并开始逐渐淡定之时,8月11日,由埃隆·马斯克(Elon Musk)推出的一位AI玩家——OpenAI Bot高调出席了Dota2国际邀请赛“The International”),并在1v1比赛环节中于第一局比赛开场的十分钟之内,就迅速“吊打”了乌克兰现役Dota2顶级职业玩家Danylo Ishutin(绰号“Dendi”)。媒体当即哀鸿遍野,Dota2战场正式“被”宣布沦陷。

(Dendi与OpenAI Bot的“世纪之战”,图片截图自优酷视频)
于此同时,谷歌DeepMind联手暴雪娱乐也发出官方声明,欲训练AI挑战《星际争霸2》世界顶级玩家。
人工智能代表着计算机领域发展的制高点,在各行各业具有着无限潜力和应用价值,但不难发现,近几年来新闻中出镜率颇高的AI(人工智能)技术突破往往总和各类游戏联系在一起,从传统的棋牌类游戏(象棋、围棋、德州扑克)到电子游戏(星际、Dota),投资商及软件开发精英似乎总是偏爱从与人类生活关系并不密切的游戏入手,通过开发,如AlphaGo这样的游戏AI,在娱乐中促使我们思考诸如人类与人工智能的关系、人工智能的发展方向与未来等深奥的科学哲学问题。
那么问题来了,为何AI的开发总要以游戏为切入点呢?
正如AlphaGo之父,谷歌旗下DeepMind公司CEO哈萨比斯所说:“游戏是测试AI算法的完美平台,这里有无限的训练数据,不存在测试偏差,能够实施并行测试,并且还能记录每个可以量化的进展”。
"Games are the perfect platform for testing AI algorithms. There's unlimited training data, no testing bias, parallel testing, and you can record measurable progress."
-- Demis Hassabis, CEO and co-founder of DeepMind

(AI研究者与游戏挑战的关系,图片来自网络)
由此可见,与其说是AI 研究者爱跳游戏挑战的坑,不如说是游戏挑战平台高效、安全和可测的运行环境就是为AI 研究者跳坑而生。例如,在开发在自动驾驶系统中可以自动识别交通标志的AI时,为了避免在现实环境中进行测试为正常的车辆和行人造成困扰,普林斯顿大学(Princeton University)的研究团队更倾向于选择在《侠盗车手》(Grand Theft Auto)游戏中对AI识别交通标志的能力进行开发和测试。
由此可见,在这些游戏中胜出的AI,其意义远不仅局限于赢得比赛本身,而是想通过AI算法的开发,让其像人脑一样不仅具备处理各种问题的能力,还兼具自我学习和进化的能力,再利用其算法为人类做出更多的贡献。
事实上,自2014年以来,连续举办的通用游戏AI竞赛(General Video Game AI Competition,GVG-AI Competition)的核心就是测试AI解决各种问题的能力。在这项比赛中,AI 需要在未知的10款Atari游戏中对战并学习如何赢得比赛。
正如阿尔法狗在真正进行人机对弈之前,进行过无数次的自我对弈一样,游戏AI的对手并不局限于人类,不同团队开发的游戏AI之间,甚至某个游戏AI自身都可以进行对弈。

(传统的俄罗斯方块游戏(左)与GVG-AI竞赛中AI之间的俄罗斯方块比赛(右),图片来自网络)
所以说,现在AI开发者都在玩什么游戏呢?
随着AI技术的不断发展,AI所能进行的竞技性游戏更加复杂化、多元化。广义上来说,竞技性电子游戏可分为两种类型:完全信息博弈(complete information game)游戏和不完全信息博弈(Incomplete information game)游戏。
完全信息博弈游戏:在这类游戏中,每一个参与者都拥有所有其他参与者的特征、策略集及得益函数等方面的准确信息的博弈(尴尬而不失礼的翻译:己方的生命值,武器系统,技能系统等相关信息都被博弈对手所完全掌握,反之亦然。当然,这里并不是说你将要使出的招法在出招之前就能被对方预知,而是说你只能使出招式表中的招法。对手即便知晓你的全部出招可能,出什么招,何时出仍然是你根据场上形势随机应变,相时而动的)。
典型的完全信息博弈游戏包括:《乓》、《太空侵略者》、《街霸3》和《象棋》等等。进行这类游戏时,两个玩家共享同一个屏幕,看到的画面完全同步。

(完全信息博弈游戏,图片来自网络)
不完全信息博弈:对其他参与人的特征、策略空间及收益函数信息了解的不够准确、或者不是对所有参与人的特征、策略空间及收益函数都有准确的信息,在这种情况下进行的博弈就是不完全信息博弈(尴尬而不失礼的继续翻译:玩家只能知道己方(甚至仅仅自己)正在进行的操作,而对于对方玩家的情况仅知晓一部分。最典型的例子就是RTS游戏中的战争迷雾(war fog)让玩家并不能直接获取对手的动态,对手是选择暴兵还是升级科技往往只有短兵相接的那一刻才能真正揭开谜底。)。
典型的不完全信息博弈游戏包括《星际》、《CS:GO》、《Dota》等即时战略(RTS)或第一人称射击游戏。

(不完全信息博弈,图片来自网络)
即使通过游戏体验,普通玩家也能猜到完全信息博弈情形下的游戏AI开发难度要远远低于非完全信息博弈。譬如,在棋类游戏中,游戏AI与人类玩家共享相同的战局态势,一旦突破了核心算法,AI的超强运算能力就有了用武之地。AlphaGo在与柯洁的对战中体现出滴水不漏的攻防,展示出决胜千里的妙招也就不足为奇了。
在AlphaGo这样高度进化的游戏AI出现之后,人类围棋技艺中所谓**“势”**的概念也可能要成为历史了。“势”这样玄乎其技的说法,实际上是在掩饰人类大脑的运算能力无法看破复杂局面的窘迫,对于AI来说,于人类而言如同迷雾一般的棋局可能不过是中央处理器多运行的几十个纳秒而已。
通用游戏AI竞赛中的十多款Atari游戏都属于完全信息博弈。在这些游戏中,复杂度最高的几款游戏AI仍达不到击败人类玩家的水平。而在其余的一些规则相对简单的游戏中(如《乓》和《太空侵略者》游戏),人类玩家已经远不是AI的对手。
在这些游戏中,AI是如何被开发并优化,一步步击败人类的呢?
目前比较流行的通用游戏AI训练方式是以2013年NIPS上发表的,关于深度Q网络(Deep Q-Learning Network , DQN) 为基础的强化学习 (Reinforcement Learning)和深度神经网络 (Deep Neural Network,DNN)的结合。下面两篇文献中有详细的解释,这里仅以《乓》为例做简要介绍。
• Playing Atari with Deep Reinforcement Learning. ArXiv (2013)
• Humanlevel control through deep reinforcement learning. Nature (2015)
首先,简要介绍一下啥叫强化学习和深度神经网络。
**强化学习(Reinforcement Learning)**是机器人(可以理解为AI)在与环境交互中,根据获得的奖励或惩罚,不断进行学习的一种机器学习方式。
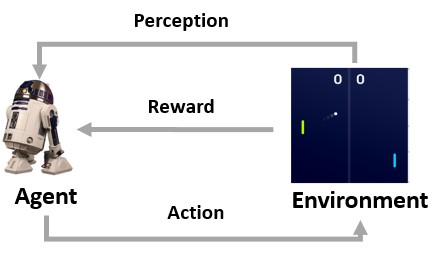
(强化学习示意图)
如图所示,从环境中,机器人会不断地得到状态 (State) 和奖励 (Reward)。这与动物学习非常类似。一开始,机器人不知道环境会对不同行为做出什么样的反应,仅从环境中获取观察的状态,这就是最上方箭头表示的感知(Perception)。而环境能够根据机器人的行为反馈给它一个奖励。
例如在《乓》中,向上移动回击小球,如对手没接住就分会增加一分,那么这一步的奖励就是正值;反之,奖励为负值。重复感知、行动和奖励的过程就形成一个强化学习的交互流程,AI在这种交互中不断纠正自己的行为,从而对环境变化做出最佳的应对。
深度神经网络**(Deep Neural Network,DNN)**,也被称为深度学习,其产生来源于科学家们模拟人脑中神经元之间传递信号的方法开发出的机器学习技术(所以才叫人工智能啊喂)。
众所周知,人脑中神经网络由1000亿多个神经元(即神经细胞)构成,不同神经元之间通过突触结构彼此相连。在这之中,每个神经元需要接收来自不同数个临近神经元传来的信号(输入1,输入2,输入3……),进行整合(后最终被传播到“输出层”,将神经网络的最终结果输出给用户。
由此可见,神经元的计算对数据的识别、处理(加权)及最终输出具有至关重要的作用,在计算机领域,这个中间步骤被称为网络的“隐藏层”。
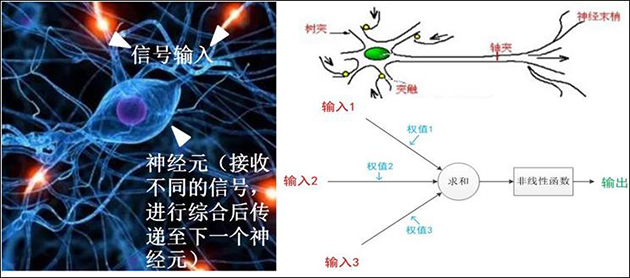
(神经元**/**深度神经网络工作原理,图片来自网络)
深度神经网络与强化学习的联合应用,即是深度Q网络模型(深度强化学习)。例如,在《乓》中深度Q网络的简略流程 :输入游戏原始画面,经过隐藏层加权后会输出概率动作输出空间。例如,在《乓》中选择上移(Up)、下移(Down)和不动(Stay)的概率。
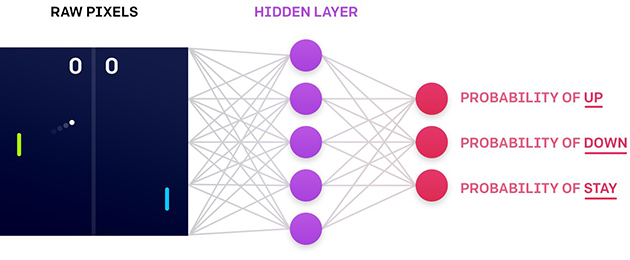
(深度Q网络流程图(图片来自https://blog.openai.com**))**
又如,Deepmind在2013年提出的一个更为复杂的深度Q网络网络结构。输入是连续4帧游戏原始画面,输出是不同动作的长期化收益Q,中间为两个卷积层(Convolutional Layer)和两个全连接层(Fully Connected Layer)。

(DQN网络结构图(图片来自http://www.teach.cs.toronto.edu**))**
我们再回到开头,看一下这次Dota2的人机对抗视频。比赛距今已约两周的时间,OpenAI最终公布了Dota AI的一些比赛细节,不过还是有所保留,并未公布全部的技术细节,不过我们可以从公开消息中猜测一二:
-
Dota是不完全信息博弈,玩家并不能直观获得对手的位置和活动信息。这使得每一步的决策都是在具有不确定性的条件下做出的。
-
AI机器人并不能局限于仅提供类似“向上移动”这样的微观操作。必须把微观操作转换连续的宏观动作流程,就像比赛视频中的卡兵操作。
-
Dota是多机器人(multi-agent) 合作博弈,这是当前AI领域最具有挑战性的部分。
-
合理的分配、使用道具,这涉及到长期的规划策略。
OpenAI Bot****选择了1v1的对抗模式,简化其有效动作数(available actions)和有效状态空间(state space)数。在该限制条件下,对抗的关键为技能选择和短期策略,并不涉及到长期规划和多机器人协调。也就是说对战环境的设置更加类似于《街霸》一类的格斗游戏,而不是真正的即时战略。
(一些可能的AI输入信息)
值得注意的是,如果将游戏设置为即时战略(RTS)模式,从目前来看,就算在OepnAI的限制场景下, OpenAI Bot还未达吊打人类的水平。由于算法鲁棒性和泛化能力的局限性,它还无法像人类玩家一样从若干几回合的对局中找到对手弱点并加以针对。就像Deepmind在开源的星际2人工智能学习环境(SC2LE)中指出的那样,现阶段,AI还不具备在即时战略(RTS)游戏中对抗人类玩家的能力。
(OpenAI Bot被战翻50余次)
从传统的棋牌类游戏(象棋、围棋、德州扑克)到经典对战电子游戏(星际、Dota、CS),AI在征服了几乎全部的棋牌类游戏之后,又将魔爪伸向了即时战略游戏。人类还能在多大程度上延缓AI的攻势,即时战略游戏何时才会全面沦陷?非完全信息博弈游戏集中体现了人类智慧的高度,如同两国交战,战术和战略层面的种种策略——诱敌深入、千里奔袭、围魏救赵、擒贼擒王、声东击西、瞒天过海……都可以在Dota以及CS中找到对应的影子。
如果有一天,AI也能产生“谋略”,像人类一样运筹帷幄、纵横捭阖,类似电影《终结者》系列中拥有自主智能并致力于绞杀人类的AI“天网”可能绝非狂想。在不断提升AI性能、应用领域的同时,人类还需不断的思考人工智能的发展方向以及人类与人工智能的未来。
参考文献
-
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller. Playing Atari With Deep Reinforcement Learning. NIPS Deep Learning Workshop, 2013.
-
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, Demis Hassabis. Human-level Control through Deep Reinforcement Learning. Nature, 518: 529–533, 2015.
-
PySC2 - StarCraft II Learning Environment. https://github.com/deepmind/pysc2
-
Dota Bot Scripting - API Reference. https://developer.valvesoftware.com/wiki/Dota_Bot_Scripting_-_API_Reference
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国