

统计学术语定义
在生产工作正常的情况下,产品的质量也不可能完全相同,但也不会相差太大,而是围绕着一定的平均值,在一定的范围内变动和分布。分布分析****法就是通过对质量的变动分布状态的分析中发现问题的一种重要方法。它可以了解生产工序是否正常,废品是否发生等情况。其工具是直方图,故又称直方图法1。
基本介绍分布分析法又称直方图法。它是将搜集到的质量数据进行分组整理,绘制成频数分布直方图,用以描述质量分布状态的一种分析方法。在学习直方图之前,我们首先应了解一下质量数据的一些特点2。
1. 质量数据
质量管理的指导思想中有一条是“用数据说话”。每一种产品都有其质量特性。为了尽量准确地表达产品的质量特性,就需要量化这些特性,从而得到了质量特性值。产品的质量特性有很多都是可以直接衡量的,比如重量、长度、强度、浓度、速度等;但是另一些特性却很难直接衡量,如光洁度、造型美感、舒适性、味感等,这些特性要确定一些技术参数来间接反映。也有一些特性值虽是可以直接衡量,为了方便而选用代用值去间接衡量,如耐用度是金属切削工具的真正质量特性,而规定的硬度HRC是代用特性。总之,产品的质量特性绝大部分是以量的形式表示,可以据此制定质量标准。
常用到的质量特性数值有五类:
计量值数据:指可以连续取值的数据,可以出现小数,小数位数根据要求而定,即数据具有连续性,像长度、重量、温度、压力、化学成分等。
计数值数据:指不能连续取值的数据,只能以件数、个数、点数等整数计量,具有离散性。
评分数:有些质量特性值既可为整数值又可为非整数值,如舒适度、美感度等,只是为了方便起见,常将这些数定义为计数值,即只取整数。
顺序数:只能排出顺序的数,多取整数。
优劣值(或等级数):只能定出优劣程度,表示等级。
2.直方图
直方图又称质量分布图。它是通过对收集来的数据进行加工、整理,以此来判断生产过程质量水平及不合格品率大小的一种常用工具。根据直方图可掌握产品质量的波动情况,了解质量特征的分布规律,以便对质量状况进行分析判断。
绘制直方图一般需要50个以上数据,通过以下步骤进行。
搜集整理数据:用随机抽样的方法抽取数据,一般要求数据在50个以上。
计算极差R:极差R是数据中最大值和最小值之差。
对数据分组:包括确定组数、组距和组限。
第一,确定组数K。确定组数的原则是分组的结果能正确地反映数据的分布规律。组数应根据数据多少来确定。组数过少,会掩盖数据的分布规律;组数过多,使数据过于零乱分散,也不能显示出质量分布状况。一般可参考表1的经验数值确定。
|| || 表1 数据分组参考值
第二,确定组距H。组距是组与组之间的间隔,即一个组的范围。各组距应相等,于是有
极差≈组距×组数,即: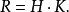
因而组数、组距的确定应根据极差综合考虑,适当调整,还要注意数值尽量取整,使分组结果能包括全部变量值,同时也便于以后的计算分析。
第三,确定组限。每组的最大值为上限,最小值为下限,上、下限统称组限。
确定组限时应注意使各组之间连续,即较低组上限应为相邻较高组下限,这样才能不致使有的数据被遗漏。对恰恰处于组限值上的数据,其解决的办法有:规定每组上(或下)组限不计在该组内,而应计入相邻较高(或较低)组内;将组限值较原始数据精度提高半个最小测量单位。
编制数据频数统计表:统计各组频数,可采用唱票形式进行,频数总和应等于全部数据个数。
绘制频数分布直方图:在频数分布直方图中,横坐标表示质量特性值,并标出各组的组限值。画出以组距为底,以频数为高的K个直方形,便得到频数分布直方图。
绘制出直方图以后,将之与标准分布图比较可以对该批产品质量分布情况作出一个判断2。
语言学术语定义分布分析法是结构主义语言学所采用的一种分析语言的方法。分析语言诸单位在语言结构中的分布关系,借以进行语言单位的分类与归纳语言的结构系统。如分析音位在词中,词在句子中的分布情况。它用于音素、语素直到结构体的分析,并把分布分析归纳为切分话语、归并语素、语素分类、语素组合四个步骤,用以揭示语音、语法和词汇成分在较大的序列中的分布情况。这种方法首先由美国描写语言学派提出来3。
基本介绍按照Harris的定义,一个单位的“分布”是指“它所出现的全部环境的总和,也就是这个单位的所有(不同的)位置(或者出现情况)的总和,这个单位出现的这些位置是同其他单位的出现有关系的”。分布分析最初被用于音位分析,后来则广泛运用于语素分析和句法分析。美国结构主义语言学家赋予“分布”以特殊的地位,认为“描写语言学的主要研究工作……就是要确立话语中某些部分或特征的相互间的分布或配列关系”。这使得分布分析成为后布龙菲尔德学派最根本的语言分析方法,而分布的标准也成为该学派对语言进行切分和归类时所遵循的主要标准,以至于有人把他们的语言分析思想称作“分布主义”(distributionalism)。根据单位所出现的环境,分布可分为三种类型4:
1)对等分布(equivalent distribution),即两个成分可出现在相同的环境。如果这两个成分相互替代时不改变整个形式的意义,则它们互为自由变体,如either中的/i:/和/ai/,以及湖北方言中的/n/和/l/;如果使意义发生改变,则两个成分处于对立分布,如game中的/g/与came中的/k/;
2)部分对等分布,即两个成分经常但并非总是出现于同一环境,如/k/与/ŋ/,前者可出现于词首、词中和词尾,而后者不出现于词首,但可以出现在词中和词尾;
3)互补分布,即两个成分从不在同一环境中出现,如[t]与[th],在词首的元音前只能出现送气音[th],而在词首的辅音/s/后只能出现不送气音[t]4。
分布分析则有两种情况。一种情况是以寻找语言单位的同类(或部分同类)环境为原则的归类法,在形式类的归并中常用到这种分析方法,如Fries把凡能出现于(The)___is/are good或___s are/were good框架中的形式称为I类词。Hockett把能够出现在cart、can go、can go there之前的she、he、it、I、we、they等归为一个形式类。另一种情况是以寻找语言单位的异类环境为原则的归类法,即根据互补分布来进行归类,在音位和语素的归并中常用到这种分析方法。如Harris把英语中的/-iz/、/-s/、/-z/、/-ən/(在ox后出现)、/a/~/e/(如man)和零形式(在sheep中出现)都归并为一个语素(复数语素),因为它们具有相同的意义,且处于互补分布之中。
分布分析从语言的形式出发,着眼于易于观察的语言单位之间的位置关系和它们所处的环境,因此避免了传统语言学因过分依赖意义而导致分析中主观性过强的缺陷。例如Harris便认为,采用分布分析的原因在于“方法严密的需要”(demand of rigor),同时也在于这种分析能处理某些用语义分析难以确定的情况。不过,以Harris为代表的某些后布龙菲尔德学派的学者,如Bloch、Trager等人,在语言分析中极力回避意义,试图完全依赖分布来对语言进行描写。Bloch宣称,可以“完全不依赖于意义”,而仅仅依靠语音特征和分布来确定一种语言的音位系统。Trager&Smith也说:“意义没有什么指导作用,分析的理论基础……在于发现类似的模式和序列出现的情况和分布。”Harris则认为,在语言分析中,意义的使用只能是“起提示作用”(heuristically),“决定性的标准永远只能是用分布状况予以说明”。然而,正如众多学者所指出的,仅靠分布法是不可能对语言作出全面、准确的描写和分析的。而且实际上,分布主义者在语言分析中还是利用了意义。另外,分布分析还存在理论上的循环论证、操作上的主观性(如对环境的选择)等缺陷,在实际应用中其操作程序也极为繁琐。这些弊病在相当程度上限制了分布法的有效运用4。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国