

迭代法也称辗转法,是一种不断用变量的旧值递推新值的过程,跟迭代法相对应的是直接法(或者称为一次解法),即一次性解决问题。迭代算法是用计算机解决问题的一种基本方法,它利用计算机运算速度快、适合做重复性操作的特点,让计算机对一组指令(或一定步骤)进行重复执行,在每次执行这组指令(或这些步骤)时,都从变量的原值推出它的一个新值,迭代法又分为精确迭代和近似迭代。比较典型的迭代法如“二分法”和"牛顿迭代法”属于近似迭代法。1
简介迭代法是一类利用递推公式或循环算法通过构造序列来求问题近似解的方法。例如,对非线性方程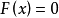 ,利用递推关系式
,利用递推关系式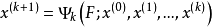 ,从
,从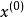 开始依次计算
开始依次计算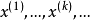 ,来逼近方程的根
,来逼近方程的根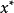 的方法,若
的方法,若 仅与
仅与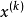 有关,即
有关,即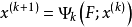 ,则称此迭代法为单步迭代法,一般称为多步迭代法;对于线性方程组
,则称此迭代法为单步迭代法,一般称为多步迭代法;对于线性方程组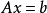 ,由关系
,由关系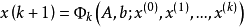 从 开始依次计算 来过近方程 的解的方法。若对某一正整数
从 开始依次计算 来过近方程 的解的方法。若对某一正整数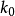 ,当
,当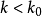 时,
时,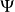 与 k 无关,称该迭代法为定常迭代法,否则称之为非定常迭代法。称所构造的序列
与 k 无关,称该迭代法为定常迭代法,否则称之为非定常迭代法。称所构造的序列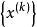 为迭代序列。
为迭代序列。
应用迭代法的主要研究课题是对所论问题构造收敛的迭代格式,分析它们的收敛速度及收敛范围。迭代法的收敛性定理可分成下列三类:
①局部收敛性定理:假设问题解存在,断定当初始近似与解充分接近时迭代法收敛;
②半局部收敛性定理:在不假定解存在的情况下,根据迭代法在初始近似处满足的条件,断定迭代法收敛于问题的解;
③大范围收敛性定理:在不假定初始近似与解充分接近的条件下,断定选代法收敛于问题的解。
选代法在线性和非线性方程组求解,最优化计算及特征值计算等问题中被广泛应用。2
算法迭代是数值分析中通过从一个初始估计出发寻找一系列近似解来解决问题(一般是解方程或者方程组)的过程,为实现这一过程所使用的方法统称为迭代法(Iterative Method)。
一般可以做如下定义:对于给定的线性方程组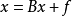 (这里的x、B、f同为矩阵,任意线性方程组都可以变换成此形式),用公式
(这里的x、B、f同为矩阵,任意线性方程组都可以变换成此形式),用公式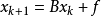 (
(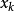 代表迭代k次得到的x,初始时k=0)逐步带入求近似解的方法称为迭代法(或称一阶定常迭代法)。如果
代表迭代k次得到的x,初始时k=0)逐步带入求近似解的方法称为迭代法(或称一阶定常迭代法)。如果 存在,记为x*,称此迭代法收敛。显然x*就是此方程组的解,否则称为迭代法发散。
存在,记为x*,称此迭代法收敛。显然x*就是此方程组的解,否则称为迭代法发散。
跟迭代法相对应的是直接法(或者称为一次解法),即一次性的快速解决问题,例如通过开方解决方程x +3= 4。一般如果可能,直接解法总是优先考虑的。但当遇到复杂问题时,特别是在未知量很多,方程为非线性时,我们无法找到直接解法(例如五次以及更高次的代数方程没有解析解,参见阿贝耳定理),这时候或许可以通过迭代法寻求方程(组)的近似解。
最常见的迭代法是牛顿法。其他还包括最速下降法、共轭迭代法、变尺度迭代法、最小二乘法、线性规划、非线性规划、单纯型法、惩罚函数法、斜率投影法、遗传算法、模拟退火等等。
利用迭代算法解决问题,需要做好以下三个方面的工作:
确定迭代变量在可以用迭代算法解决的问题中,至少存在一个直接或间接地不断由旧值递推出新值的变量,这个变量就是迭代变量。
建立迭代关系式所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式(或关系)。迭代关系式的建立是解决迭代问题的关键,通常可以顺推或倒推的方法来完成。
对迭代过程进行控制在什么时候结束迭代过程?这是编写迭代程序必须考虑的问题。不能让迭代过程无休止地重复执行下去。迭代过程的控制通常可分为两种情况:一种是所需的迭代次数是个确定的值,可以计算出来;另一种是所需的迭代次数无法确定。对于前一种情况,可以构建一个固定次数的循环来实现对迭代过程的控制;对于后一种情况,需要进一步分析出用来结束迭代过程的条件。
举例例 1 :一个饲养场引进一只刚出生的新品种兔子,这种兔子从出生的下一个月开始,每月新生一只兔子,新生的兔子也如此繁殖。如果所有的兔子都不死去,问到第 12 个月时,该饲养场共有兔子多少只?
分析:这是一个典型的递推问题。我们不妨假设第 1 个月时兔子的只数为 u 1 ,第 2 个月时兔子的只数为 u 2 ,第 3 个月时兔子的只数为 u 3 ,……根据题意,“这种兔子从出生的下一个月开始,每月新生一只兔子”,则有
u 1 = 1 , u 2 = u 1 + u 1 × 1 = 2 , u 3 = u 2 + u 2 × 1 = 4 ,……
根据这个规律,可以归纳出下面的递推公式:
u n = u(n - 1)× 2 (n ≥ 2)
对应 u n 和 u(n - 1),定义两个迭代变量 y 和 x ,可将上面的递推公式转换成如下迭代关系:
y=x*2
x=y
让计算机对这个迭代关系重复执行 11 次,就可以算出第 12 个月时的兔子数。参考程序如下:
cls
x=1
for i=2 to 12
y=x*2
x=y
next i
print y
end
例 2 :阿米巴用简单分裂的方式繁殖,它每分裂一次要用 3 分钟。将若干个阿米巴放在一个盛满营养参液的容器内, 45 分钟后容器内充满了阿米巴。已知容器最多可以装阿米巴 220,220个。试问,开始的时候往容器内放了多少个阿米巴?请编程序算出。
分析:根据题意,阿米巴每 3 分钟分裂一次,那么从开始的时候将阿米巴放入容器里面,到 45 分钟后充满容器,需要分裂 45/3=15 次。而“容器最多可以装阿米巴2^ 20 个”,即阿米巴分裂 15 次以后得到的个数是 2^20。题目要求我们计算分裂之前的阿米巴数,不妨使用倒推的方法,从第 15 次分裂之后的 2^20 个,倒推出第 15 次分裂之前(即第 14 次分裂之后)的个数,再进一步倒推出第 13 次分裂之后、第 12 次分裂之后、……第 1 次分裂之前的个数。
设第 1 次分裂之前的个数为 x 0 、第 1 次分裂之后的个数为 x 1 、第 2 次分裂之后的个数为 x 2 、……第 15 次分裂之后的个数为 x 15 ,则有
x 14 =x 15 /2 、 x 13 =x 14 /2 、…… x n-1 =x n /2 (n ≥ 1)
因为第 15 次分裂之后的个数 x 15 是已知的,如果定义迭代变量为 x ,则可以将上面的倒推公式转换成如下的迭代公式:
x=x/2 (x 的初值为第 15 次分裂之后的个数 2^20)
让这个迭代公式重复执行 15 次,就可以倒推出第 1 次分裂之前的阿米巴个数。因为所需的迭代次数是个确定的值,我们可以使用一个固定次数的循环来实现对迭代过程的控制。参考程序如下:
cls
x=2^20
for i=1 to 15
x=x/2
next i
print x
end
**ps:**java中幂的算法是Math.pow(2,20);返回double,稍微注意一下
例 3 :验证谷角猜想。日本数学家谷角静夫在研究自然数时发现了一个奇怪现象:对于任意一个自然数 n ,若 n 为偶数,则将其除以 2 ;若 n 为奇数,则将其乘以 3 ,然后再加 1。如此经过有限次运算后,总可以得到自然数 1。人们把谷角静夫的这一发现叫做“谷角猜想”。
要求:编写一个程序,由键盘输入一个自然数 n ,把 n 经过有限次运算后,最终变成自然数 1 的全过程打印出来。
分析:定义迭代变量为 n ,按照谷角猜想的内容,可以得到两种情况下的迭代关系式:当 n 为偶数时, n=n/2 ;当 n 为奇数时, n=n*3+1。用 QBASIC 语言把它描述出来就是:
if n 为偶数 then
n=n/2
else
n=n*3+1
end if
这就是需要计算机重复执行的迭代过程。这个迭代过程需要重复执行多少次,才能使迭代变量 n 最终变成自然数 1 ,这是我们无法计算出来的。因此,还需进一步确定用来结束迭代过程的条件。仔细分析题目要求,不难看出,对任意给定的一个自然数 n ,只要经过有限次运算后,能够得到自然数 1 ,就已经完成了验证工作。因此,用来结束迭代过程的条件可以定义为:n=1。参考程序如下:
cls
input "Please input n=";n
do until n=1
if n mod 2=0 then
rem 如果 n 为偶数,则调用迭代公式 n=n/2
n=n/2
print "—";n;
else
n=n*3+1
print "—";n;
end if
loop
end
迭代法开平方:
#include
#include
void main()
{
double a,x0,x1;
printf("Input a:\n");
scanf("%lf",&a);//因为a是double型数据,所以要用%lf,而不是%f
if(a=1e-6);
}
printf("Result:\n");
printf("sqrt(%g)=%g\n",a,x1);
}
求平方根的迭代公式:x1=1/2*(x0+a/x0)。
算法:1.先自定一个初值x0,作为a的平方根值,在我们的程序中取a/2作为x0的初值;利用迭代公式求出一个x1。此值与真正的a的平方根值相比,误差很大。
⒉把新求得的x1代入x0中,准备用此新的x0再去求出一个新的x1.
⒊利用迭代公式再求出一个新的x1的值,也就是用新的x0又求出一个新的平方根值x1,此值将更趋近于真正的平方根值。
⒋比较前后两次求得的平方根值x0和x1,如果它们的差值小于我们指定的值,即达到我们要求的精度,则认为x1就是a的平方根值,去执行步骤5;否则执行步骤2,即循环进行迭代。
迭代法是用于求方程或方程组近似根的一种常用的算法设计方法。设方程为f(x)=0,用某种数学方法导出等价的形式x=g(x),然后按以下步骤执行:
⑴ 选一个方程的近似根,赋给变量x0;
⑵ 将x0的值保存于变量x1,然后计算g(x1),并将结果存于变量x0;
⑶ 当x0与x1的差的绝对值还小于指定的精度要求时,重复步骤⑵的计算。
若方程有根,并且用上述方法计算出来的近似根序列收敛,则按上述方法求得的x0就认为是方程的根。上述算法用C程序的形式表示为:
【算法】迭代法求方程的根
{ x0=初始近似根;
do {
x1=x0;
x0=g(x1); /*按特定的方程计算新的近似根*/
} while (fabs(x0-x1)>Epsilon);
printf(“方程的近似根是%f\n”,x0);
}
迭代算法也常用于求方程组的根,令
X=(x0,x1,…,xn-1)
设方程组为:
xi=gi(X) (I=0,1,…,n-1)
则求方程组根的迭代算法可描述如下:
【算法】迭代法求方程组的根
{ for (i=0;i
x=初始近似根;
do {
for (i=0;i
y=x;
for (i=0;i
x=gi(X);
for (delta=0.0,i=0;i
if (fabs(y-x)>delta) delta=fabs(y-x);
} while (delta>Epsilon);
for (i=0;i
printf(“变量x[%d]的近似根是 %f”,I,x);
printf(“\n”);
}
具体使用迭代法求根时应注意以下两种可能发生的情况:
⑴ 如果方程无解,算法求出的近似根序列就不会收敛,迭代过程会变成死循环,因此在使用迭代算法前应先考察方程是否有解,并在程序中对迭代的次数给予限制;
⑵ 方程虽然有解,但迭代公式选择不当,或迭代的初始近似根选择不合理,也会导致迭代失败。
递归
递归是设计和描述算法的一种有力的工具,由于它在复杂算法的描述中被经常采用,为此在进一步介绍其他算法设计方法之前先讨论它。
能采用递归描述的算法通常有这样的特征:为求解规模为N的问题,设法将它分解成规模较小的问题,然后从这些小问题的解方便地构造出大问题的解,并且这些规模较小的问题也能采用同样的分解和综合方法,分解成规模更小的问题,并从这些更小问题的解构造出规模较大问题的解。特别地,当规模N=1时,能直接得解。
【问题】 编写计算斐波那契(Fibonacci)数列的第n项函数fib(n)。
斐波那契数列为:0、1、1、2、3、……,即:
fib(0)=0;
fib⑴=1;
fib(n)=fib(n-1)+fib(n-2) (当n>1时)。
写成递归函数有:
int fib(int n)
{ if (n==0) return 0;
if (n==1) return 1;
if (n>1) return fib(n-1)+fib(n-2);
}
递归算法的执行过程分递推和回归两个阶段。在递推阶段,把较复杂的问题(规模为n)的求解推到比原问题简单一些的问题(规模小于n)的求解。例如上例中,求解fib(n),把它推到求解fib(n-1)和fib(n-2)。也就是说,为计算fib(n),必须先计算fib(n-1)和fib(n- 2),而计算fib(n-1)和fib(n-2),又必须先计算fib(n-3)和fib(n-4)。依次类推,直至计算fib⑴和fib(0),分别能立即得到结果1和0。在递推阶段,必须要有终止递归的情况。例如在函数fib中,当n为1和0的情况。
在回归阶段,当获得最简单情况的解后,逐级返回,依次得到稍复杂问题的解,例如得到fib⑴和fib(0)后,返回得到fib⑵的结果,……,在得到了fib(n-1)和fib(n-2)的结果后,返回得到fib(n)的结果。
在编写递归函数时要注意,函数中的局部变量和参数知识局限于当前调用层,当递推进入“简单问题”层时,原来层次上的参数和局部变量便被隐蔽起来。在一系列“简单问题”层,它们各有自己的参数和局部变量。
由于递归引起一系列的函数调用,并且可能会有一系列的重复计算,递归算法的执行效率相对较低。当某个递归算法能较方便地转换成递推算法时,通常按递推算法编写程序。例如上例计算斐波那契数列的第n项的函数fib(n)应采用递推算法,即从斐波那契数列的前两项出发,逐次由前两项计算出下一项,直至计算出要求的第n项。
【问题】 组合问题
问题描述:找出从自然数1、2、……、n中任取r个数的所有组合。例如n=5,r=3的所有组合为:⑴5、4、3 ⑵5、4、2 ⑶5、4、1
⑷5、3、2 ⑸5、3、1 ⑹5、2、1
⑺4、3、2 ⑻4、3、1 ⑼4、2、1
⑽3、2、1
分析所列的10个组合,可以采用这样的递归思想来考虑求组合函数的算法。设函数为void comb(int m,int k)为找出从自然数1、2、……、m中任取k个数的所有组合。当组合的第一个数字选定时,其后的数字是从余下的m-1个数中取k-1数的组合。这就将求m 个数中取k个数的组合问题转化成求m-1个数中取k-1个数的组合问题。设函数引入工作数组a[ ]存放求出的组合的数字,约定函数将确定的k个数字组合的第一个数字放在a[k]中,当一个组合求出后,才将a[ ]中的一个组合输出。第一个数可以是m、m-1、……、k,函数将确定组合的第一个数字放入数组后,有两种可能的选择,因还未去顶组合的其余元素,继续递归去确定;或因已确定了组合的全部元素,输出这个组合。细节见以下程序中的函数comb。
【程序】
# include
# define MAXN 100
int a[MAXN];
void comb(int m,int k)
{ int i,j;
for (i=m;i>=k;i--)
{ a[k]=i;
if (k>1)
comb(i-1,k-1);
else
{ for (j=a[0];j>0;j--)
printf(“%4d”,a[j]);
printf(“\n”);
}
}
}
void main()
{ a[0]=3;
comb(5,3);
}
【问题】 背包问题
问题描述:有不同价值、不同重量的物品n件,求从这n件物品中选取一部分物品的选择方案,使选中物品的总重量不超过指定的限制重量,但选中物品的价值之和最大。
设n 件物品的重量分别为w0、w1、…、wn-1,物品的价值分别为v0、v1、…、vn-1。采用递归寻找物品的选择方案。设前面已有了多种选择的方案,并保留了其中总价值最大的方案于数组option[ ],该方案的总价值存于变量maxv。当前正在考察新方案,其物品选择情况保存于数组cop[ ]。假定当前方案已考虑了前i-1件物品,现在要考虑第i件物品;当前方案已包含的物品的重量之和为tw;至此,若其余物品都选择是可能的话,本方案能达到的总价值的期望值为tv。算法引入tv是当一旦当前方案的总价值的期望值也小于前面方案的总价值maxv时,继续考察当前方案变成无意义的工作,应终止当前方案,立即去考察下一个方案。因为当方案的总价值不比maxv大时,该方案不会被再考察,这同时保证函数后找到的方案一定会比前面的方案更好。
对于第i件物品的选择考虑有两种可能:
⑴ 考虑物品i被选择,这种可能性仅当包含它不会超过方案总重量限制时才是可行的。选中后,继续递归去考虑其余物品的选择。
⑵ 考虑物品i不被选择,这种可能性仅当不包含物品i也有可能会找到价值更大的方案的情况。
按以上思想写出递归算法如下:
try(物品i,当前选择已达到的重量和,本方案可能达到的总价值tv)
{ /*考虑物品i包含在当前方案中的可能性*/
if(包含物品i是可以接受的)
{ 将物品i包含在当前方案中;
if (i
try(i+1,tw+物品i的重量,tv);
else
/*又一个完整方案,因为它比前面的方案好,以它作为最佳方案*/
以当前方案作为临时最佳方案保存;
恢复物品i不包含状态;
}
/*考虑物品i不包含在当前方案中的可能性*/
if (不包含物品i仅是可男考虑的)
if (i
try(i+1,tw,tv-物品i的价值);
else
/*又一个完整方案,因它比前面的方案好,以它作为最佳方案*/
以当前方案作为临时最佳方案保存;
}
为了理解上述算法,特举以下实例。设有4件物品,它们的重量和价值见表:
物品 0 1 2 3
重量 5 3 2 1
价值 4 4 3 1
并设限制重量为7。则按以上算法,下图表示找解过程。由图知,一旦找到一个解,算法就进一步找更好的佳。如能判定某个查找分支不会找到更好的解,算法不会在该分支继续查找,而是立即终止该分支,并去考察下一个分支。
按上述算法编写函数和程序如下:
【程序】
# include
# define N 100
double limitW,totV,maxV;
int option[N],cop[N];
struct { double weight;
double value;
}a[N];
int n;
void find(int i,double tw,double tv)
{ int k;
/*考虑物品i包含在当前方案中的可能性*/
if (tw+a.weightmaxV)
if (i
else
{ for (k=0;k
option[k]=cop[k];
maxv=tv-a.value;
}
}
void main()
{ int k;
double w,v;
printf(“输入物品种数\n”);
scanf((“%d”,&n);
printf(“输入各物品的重量和价值\n”);
for (totv=0.0,k=0;k
{ scanf(“%1f%1f”,&w,&v);
a[k].weight=w;
a[k].value=v;
totV+=V;
}
printf(“输入限制重量\n”);
scanf(“%1f”,&limitV);
maxv=0.0;
for (k=0;k find(0,0.0,totV);
for (k=0;k
if (option[k]) printf(“%4d”,k+1);
printf(“\n总价值为%.2f\n”,maxv);
}
作为对比,下面以同样的解题思想,考虑非递归的程序解。为了提高找解速度,程序不是简单地逐一生成所有候选解,而是从每个物品对候选解的影响来形成值得进一步考虑的候选解,一个候选解是通过依次考察每个物品形成的。对物品i的考察有这样几种情况:当该物品被包含在候选解中依旧满足解的总重量的限制,该物品被包含在候选解中是应该继续考虑的;反之,该物品不应该包括在当前正在形成的候选解中。同样地,仅当物品不被包括在候选解中,还是有可能找到比目前临时最佳解更好的候选解时,才去考虑该物品不被包括在候选解中;反之,该物品不包括在当前候选解中的方案也不应继续考虑。对于任一值得继续考虑的方案,程序就去进一步考虑下一个物品。
【程序】
# include
# define N 100
double limitW;
int cop[N];
struct ele { double weight;
double value;
} a[N];
int k,n;
struct { int ;
double tw;
double tv;
}twv[N];
void next(int i,double tw,double tv)
{ twv.=1;
twv tw=tw;
twv tv=tv;
}
double find(struct ele *a,int n)
{ int i,k,f;
double maxv,tw,tv,totv;
maxv=0;
for (totv=0.0,k=0;k
totv+=a[k].value;
next(0,0.0,totv);
i=0;
While (i>=0)
{ f=twv.;
tw=twv tw;
tv=twv tv;
switch(f)
{ case 1: twv.++;
if (tw+a.weightmaxv)
if (i
{ next(i+1,tw,tv-a.value);
i++;
}
else
{ maxv=tv-a.value;
for (k=0;k
cop[k]=twv[k].!=0;
}
break;
}
}
return maxv;
}
void main()
{ double maxv;
printf(“输入物品种数\n”);
scanf((“%d”,&n);
printf(“输入限制重量\n”);
scanf(“%1f”,&limitW);
printf(“输入各物品的重量和价值\n”);
for (k=0;k
scanf(“%1f%1f”,&a[k].weight,&a[k].value);
maxv=find(a,n);
printf(“\n选中的物品为\n”);
for (k=0;k
if (option[k]) printf(“%4d”,k+1);
printf(“\n总价值为%.2f\n”,maxv);
}
本词条内容贡献者为:
尚华娟 - 副教授 - 上海财经大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国