

语音合成是通过机械的、电子的方法产生人造语音的技术。TTS技术(又称文语转换技术)隶属于语音合成,它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。
采用世界领先的语音合成技术,研发出来的“语音合成助手”软件可以完美的完成语音合成工作。
概述语音合成是利用电子计算机和一些专门装置模拟人,制造语音的技术。
专业技术语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。使电脑具有类似于人一样的说话能力,是当今时代信息产业的重要竞争市场。和语音识别相比,语音合成的技术相对说来要成熟一些,并已开始向产业化方向成功迈进,大规模应用指日可待。
语音合成,又称文语转换(Text to Speech)技术,能将任意文字信息实时转化为标准流畅的语音朗读出来,相当于给机器装上了人工嘴巴。它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何将文字信息转化为可听的声音信息,也即让机器像人一样开口说话。我们所说的“让机器像人一样开口说话”与传统的声音回放设备(系统)有着本质的区别。传统的声音回放设备(系统),如磁带录音机,是通过预先录制声音然后回放来实现“让机器说话”的。这种方式无论是在内容、存储、传输或者方便性、及时性等方面都存在很大的限制。而通过计算机语音合成则可以在任何时候将任意文本转换成具有高自然度的语音,从而真正实现让机器“像人一样开口说话”。1
转换系统文语转换系统实际上可以看作是一个人工智能系统。为了合成出高质量的语言,除了依赖于各种规则,包括语义学规则、词汇规则、语音学规则外,还必须对文字的内容有很好的理解,这也涉及到自然语言理解的问题。下图显示了一个完整的文语转换系统示意图。文语转换过程是先将文字序列转换成音韵序列,再由系统根据音韵序列生成语音波形。其中第一步涉及语言学处理,例如分词、字音转换等,以及一整套有效的韵律控制规则;第二步需要先进的语音合成技术,能按要求实时合成出高质量的语音流。因此一般说来,文语转换系统都需要一套复杂的文字序列到音素序列的转换程序,也就是说,文语转换系统不仅要应用数字信号处理技术,而且必须有大量的语言学知识的支持。1
TTS结构语言处理在文语转换系统中起着重要的作用,主要模拟人对自然语言的理解过程——文本规整、词的切分、语法分析和语义分析,使计算机对输入的文本能完全理解,并给出后两部分所需要的各种发音提示。1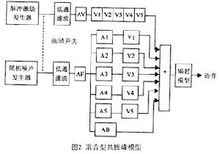
韵律处理为合成语音规划出音段特征,如音高、音长和音强等,使合成语音能正确表达语意,听起来更加自然。1
声学处理根据前两部分处理结果的要求输出语音,即合成语音。1
历史语音合成技术的研究已有两百多年的历史,但真正具有实用意义的近代语音合成技术是随着计算机技术和数字信号处理技术的发展而发展起来的,主要是让计算机能够产生高清晰度、高自然度的连续语音。在语音合成技术的发展过程中,早期的研究主要是采用参数合成方法,后来随着计算机技术的发展又出现了波形拼接的合成方法。
参数合成在语音合成技术的发展中,早期的研究主要是采用参数合成方法。值得提及的是Holmes的并联共振峰合成器(1973)和Klatt的串/并联共振峰合成器(1980),只要精心调整参数,这两个合成器都能合成出非常自然的语音。最具代表性的文语转换系统当数美国DEC公司的DECtalk(1987)。但是经过多年的研究与实践表明,由于准确提取共振峰参数比较困难,虽然利用共振峰合成器可以得到许多逼真的合成语音,但是整体合成语音的音质难以达到文语转换系统的实用要求。1
波形拼接自八十年代末期至今,语言合成技术又有了新的进展,特别是基音同步叠加(PSOLA)方法的提出(1990),使基于时域波形拼接方法合成的语音的音色和自然度大大提高。九十年代初,基于PSOLA技术的法语、德语、英语、日语等语种的文语转换系统都已经研制成功。这些系统的自然度比以前基于LPC方法或共振峰合成器的文语合成系统的自然度要高,并且基于PSOLA方法的合成器结构简单易于实时实现,有很大的商用前景。
国内的汉语语音合成研究起步较晚些,但从八十年代初就基本上与国际上研究同步发展。大致也经历了共振峰合成、LPC合成至应用PSOLA技术的过程。在国家863计划,国家自然科学基金委,国家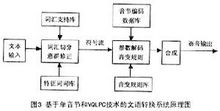 攻关计划,中国科学院有关项目等支持下,联想佳音(1995);清华大学的TH_SPEECH (1993);中国科技大学的KDTALK(1995)等系统。这些系统基本上都是采用基于PSOLA方法的时域波形拼接技术,其合成汉语普通话的可懂度、清晰度达到了很高的水平。然而同国外其它语种的文语转换系统一样,这些系统合成的句子及篇章语音机器味较浓,其自然度还不能达到用户可广泛接受的程度,从而制约了这项技术的大规模进入市场。1
攻关计划,中国科学院有关项目等支持下,联想佳音(1995);清华大学的TH_SPEECH (1993);中国科技大学的KDTALK(1995)等系统。这些系统基本上都是采用基于PSOLA方法的时域波形拼接技术,其合成汉语普通话的可懂度、清晰度达到了很高的水平。然而同国外其它语种的文语转换系统一样,这些系统合成的句子及篇章语音机器味较浓,其自然度还不能达到用户可广泛接受的程度,从而制约了这项技术的大规模进入市场。1
合成方法系统概念一种语音合成系统,其包括:分割单元,其被配置成将对应于目标语音的音位串分割为多个节段,来产生第一节段序列;
选择单元,其被配置成基于第一节段序列通过组合多个语音单元产生对应于第一节段序列的多个第一语音单元串,并从所述多个第一语音单元串中选择一个语音单元串;和连接单元,其被配置成连接包含在所选择语音单元串中的多个语音单元,以产生合成语音,选择单元包括检索单元,其被配置成反复实施第一处理和第二处理,该第一处理基于对应于第二节段序列的最多W个(W为预定值)第二语音单元串产生对应于第三节段序列的多个第三语音单元串,所述第二节段序列作为第一节段序列中的部分序列,所述第三节段序列作为通过将节段添加给第二节段序列而获得的部分序列,第二处理从所述多个第三语音单元串中选择最多W个第三语音单元串,第一计算单元,其被配置成计算所述多个第三语音单元串中每个的总成本,第二计算单元,其被配置成基于涉及语音单元数据获取速度的限制来为所述多个第三语音单元串中的每个计算对应于总成本的惩罚系数,其中惩罚系数依赖于接近所述限制的程度,和第三计算单元,其被配置成通过使用惩罚系数修正总成本来计算所述多个第三语音单元串中每个的估计值,其中检索单元基于所述多个第三语音单元串中每个的估计值从所述多个第三语音单元串中选择最多W个第三语音单元串。2
方法比较“未来的十年是语音技术的时代”。随着语音技术研究的突破,其对计算机发展和社会生活的重要性日益凸现出来。语音合成技术是语音技术中十分实用的一项重要技术,它能解决人民大众的实际需求,能够深入到社会的各行各业中去。
语音合成技术经历了一个逐步发展的过程,从参数合成到拼接合成,再到两者的逐步结合,其不断发展的动力是人们认知水平和需求的提高。它们各有优缺点,人们在应用过程中往往将多种技术有机地结合在一起,或将一种技术的优点运用到另一种技术上,以克服另一种技术的不足。2
共振峰语音合成的理论基础是语音生成的数学模型。该模型语音生成过程是在激励信号的激励下,声波经谐振腔(声道),由嘴或鼻辐射声波。因此,声道参数、声道谐振特性一直是研究的重点。习惯上,把声道传输频率响应上的极点称之为共振峰,而语音的共振峰频率(极点频率)的分布特性决定着该语音的音色。
音色各异的语音具有不同的共振峰模式,因此,以每个共振峰频率及其带宽作为参数,可以构成共振峰滤波器。再用若干个这种滤波器的组合来模拟声道的传输特性(频率响应),对激励源发出的信号进行调制,再经过辐射模型就可以得到合成语音。这就是共振峰合成技术的基本原理。基于共振峰的理论有以下三种实用模型。2
级联模型在该模型中,声道被认为是一组串联的二阶谐振器。该模型主要用于绝大部分元音的合成。
并联模型许多研究者认为,对于鼻化元音等非一般元音以及大部分辅音,上述级联型模型不能很好地加以描述和模拟,因此,构筑和产生了并联型共振峰模型。
混合模型在级联型共振峰合成模型中,共振峰滤波器首尾相接;而在并联型模型中,输入信号先分别通过幅度调节再加到每一个共振峰滤波器上,然后将各路的输出叠加起来。将两者比较,对于合成声源位于声道末端的语音(大多数的元音),级联型合乎语音产生的声学理论,并且无需为每一个滤波器分设幅度调节;而对于合成声源位于声道中间的语音(大多数清擦音和塞音),并联型则比较合适,但是其幅度调节很复杂。基于此种考虑,人们将两者结合在一起,提出了混和型共振峰模型。
共振峰模型是基于对声道的一种比较准确的模拟,因而可以合成出自然度比较高的语音,另外由于共振峰参数有着明确的物理意义,直接对应于声道参数,因此,可以容易利用共振峰描述自然语流中的各种现象,并且总结声学规则,最终用于共振峰合成系统。
但是,人们同时也发现该技术有明显的弱点。首先由于它是建立在对声道的模拟上,因此,对于声道模型的不精确势必会影响其合成质量。另外,实际工作表明,共振峰模型虽然描述了语音中最基本最主要的部分,但并不能表征影响语音自然度的其他许多细微的语音成分,从而影响了合成语音的自然度。另外,共振峰合成器控制十分复杂,对于一个好的合成器来说,其控制参数往往达到几十个,实现起来十分困难。
基于这些原因,研究者继续寻求和发现其他新的合成技术。人们从波形的直接录制和播放得到启发,提出了基于波形拼接的合成技术,LPC合成技术和PSOLA合成技术是其中的代表。与共振峰合成技术不同,波形拼接合成是基于对录制的合成基元的波形进行拼接,而不是基于对发声过程的模拟。2
合成技术LPC波形拼接技术的发展与语音的编、解码技术的发展密不可分,其中LPC技术(线性预测编码技术)的发展对波形拼接技术产生了巨大的影响。LPC合成技术本质上是一种时间波形的编码技术,目的是为了降低时间域信号的传输速率。
LPC合成技术的优点是简单直观。其合成过程实质上只是一种简单的解码和拼接过程。另外,由于波形拼接技术的合成基元是语音的波形数据,保存了语音的全部信息,因而对于单个合成基元来说能够获得很高的自然度。
但是,由于自然语流中的语音和孤立状况下的语音有着极大的区别,如果只是简单地把各个孤立的语音生硬地拼接在一起,其整个语流的质量势必是不太理想的。而LPC技术从本质上来说只是一种录音+重放,对于合成整个连续语流LPC合成技术的效果是不理想的。因此,LPC合成技术必须和其他技术相结合,才能明显改善LPC合成的质量。2
PSOLA20世纪80年代末提出的PSOLA合成技术(基音同步叠加技术)给波形拼接合成技术注入了新的活力。PSOLA技术着眼于对语音信号超时段特征的控制,如基频、时长、音强等的控制。而这些参数对于语音的韵律控制以及修改是至关重要的,因此,PSOLA技术比LPC技术具有可修改性更强的优点,可以合成出高自然度的语音。
PSOLA技术的主要特点是:在拼接语音波形片断之前,首先根据上下文的要求,用PSOLA算法对拼接单元的韵律特征进行调整,使合成波形既保持了原始发音的主要音段特征,又能使拼接单元的韵律特征符合上下文的要求,从而获得很高的清晰度和自然度。
PSOLA技术保持了传统波形拼接技术的优点,简单直观,运算量小,而且还能方便地控制语音信号的韵律参数,具有合成自然连续语流的条件,得到了广泛的应用。
但是,PSOLA技术也有其缺点。首先,PSOLA技术是一种基音同步的语音分析/合成技术,首先需要准确的基音周期以及对其起始点的判定。基音周期或其起始点的判定误差将会影响PSOLA技术的效果。其次,PSOLA技术是一种简单的波形映射拼接合成,这种拼接是否能够保持平稳过渡以及它对频域参数有什么影响等并没有得到解决,因此,在合成时会产生不理想的结果。2
LMA随着人们对语音合成的自然度和音质的要求越来越高,PSOLA算法表现出对韵律参数调整能力较弱和难以处理协同发音的缺陷,因此,人们又提出了一种基于LMA声道模型的语音合成方法。这种方法具有传统的参数合成可以灵活调节韵律参数的优点,同时又具有比PSOLA算法更高的合成音质。
这两种技术各有所长,共振峰技术比较成熟,有大量的研究成果可以利用,而PSOLA技术则是比较新的技术,具有良好的发展前景。过去这两种技术基本上是互相独立发展的,2
中文语音作为一种有调语言,汉语韵律特征非常复杂。古汉语的平仄以及现代汉语拼音,对于同样一个音节,出现在不同的环境下,其韵律参数都是各不相同的。用有限的存储单元存储基本汉语基本语音单元,进而从有限的存储单元中合成出无限词汇,组成连续汉语语句。必须在一定的韵律规则下对音库单元的韵律参数进行调整,以得到符合当前语言环境的语音库单元。语音合成器用来完成这种功能。
中文语音合成系统在DSP下实现时,除清晰度,能懂度和自然度外,还要求合成算法具有较低的运算复杂度,尽量小的语音库以减少对有限存储空间的占用程度。2
本词条内容贡献者为:
李宗秀 - 副教授 - 黑龙江财经学院
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国