

所谓遍历(Traversal),是指沿着某条搜索路线,依次对树(图)中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问题, 具体的访问操作可能是检查节点的值、更新节点的值等。不同的遍历方式,其访问节点的顺序是不一样的。遍历是二叉树上最重要的运算之一,是二叉树上进行其它运算之基础。当然遍历的概念也适合于多元素集合的情况,如数组。
树的遍历简介树的遍历是树的一种重要的运算。所谓遍历是指对树中所有结点的信息的访问,即依次对树中每个结点访问一次且仅访问一次。与那些基本上都有标准遍历方式(通常是按线性顺序)的线性数据结构(如链表、一维数组)所不同的是,树结构有多种不同的遍历方式。从二叉树的根节点出发,节点的遍历分为三个主要步骤:对当前节点进行操作(称为“访问”节点)、遍历左边子节点、遍历右边子节点。这三个步骤的先后顺序也是不同遍历方式的根本区别。
由于从给定的某个节点出发,有多个可以前往的下一个节点(树不是线性数据结构),所以在顺序计算(即非并行计算)的情况下,只能推迟对某些节点的访问——即以某种方式保存起来以便稍后再访问。常见的做法是采用栈(LIFO)或队列(FIFO)。由于树本身是一种自我引用(即递归定义)的数据结构,因此很自然也可以用递归方式,或者更准确地说,用corecursion,来实现延迟节点的保存。这时(采用递归的情况)这些节点被保存在call stack中。
树的3种最重要的遍历方式分别称为前序遍历、中序遍历和后序遍历。以这3种方式遍历一棵树时,若按访问结点的先后次序将结点排列起来,就可分别得到树中所有结点的前序列表、中序列表和后序列表。相应的结点次序分别称为结点的前序、中序和后序。树的这3种遍历方式可递归地定义如下:
如果T是一棵空树,那么对T进行前序遍历、中序遍历和后序遍历都是空操作,得到的列表为空表。
如果T是一棵单结点树,那么对T进行前序遍历、中序遍历和后序遍历根,树根的子树从左到右依次为T1,T2,..,Tk,那么有:
对T进行前序遍历是先访问树根n,然后依次前序遍历T1,T2,..,Tk。
对T进行中序遍历是先中序遍历T1,然后访问树根n,接着依次对T2,T2,..,Tk进行中序遍历。
对T进行后序遍历是先依次对T1,T2,..,Tk进行后序遍历,最后访问树根n。
下面以二叉树的遍历为例,二叉树是树型数据结构中最为常用的,它的遍历方法常用的有三种:先序遍历二叉树,中序遍历二叉树,后序遍历二叉树。从算法分有可分为:递归遍历算法和非递归算法。递归先序遍历二叉树的操作定义为:访问根结点,先序遍历左子树,先序遍历右子树。递归中序遍历二叉树的操作定义为:中序序遍历左子树,访问根结点,中序遍历右子树。递归后序遍历二叉树的操作定义为:后序遍历左子树,后序遍历右子树,访问根结点1。
从二叉树的递归定义可知,一棵非空的二叉树由根结点及左、右子树这三个基本部分组成。
 因此,在任一给定结点上,可以按某种次序执行三个操作:
因此,在任一给定结点上,可以按某种次序执行三个操作:
⑴访问结点本身(N),
⑵遍历该结点的左子树(L),
⑶遍历该结点的右子树(R)。
以上三种操作有六种执行次序:
NLR、LNR、LRN、NRL、RNL、RLN。
注意:
前三种次序与后三种次序对称,故只讨论先左后右的前三种次序。
命名根据访问结点操作发生位置命名:
① NLR:前序遍历(PreorderTraversal亦称(先序遍历))
——访问结点的操作发生在遍历其左右子树之前。
② LNR:中序遍历(InorderTraversal)
——访问结点的操作发生在遍历其左右子树之中(间)。
③ LRN:后序遍历(PostorderTraversal)
——访问结点的操作发生在遍历其左右子树之后。
注意:
由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解释为根、根的左子树和根的右子树。NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
遍历算法
中序若二叉树非空,则依次执行如下操作:
⑴遍历左子树;
⑵访问根结点;
⑶遍历右子树。
先序若二叉树非空,则依次执行如下操作:
⑴ 访问根结点;
⑵ 遍历左子树;
⑶ 遍历右子树。
后序若二叉树非空,则依次执行如下操作:
⑴遍历左子树;
⑵遍历右子树;
⑶访问根结点。
中序算法用二叉链表做为存储结构,中序遍历算法可描述为:
void InOrder(BinTree T)
{ //算法里①~⑥是为了说明执行过程加入的标号
① if(T) { // 如果二叉树非空
② InOrder(T->lchild);
③ printf("%c",T->data); // 访问结点
④ InOrder(T->rchild);
⑤ }
⑥ } // InOrder
序列1.遍历二叉树的执行踪迹
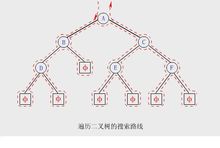
三种递归遍历算法的搜索路线相同(如下图虚线所示)。
具体线路为:
从根结点出发,逆时针沿着二叉树外缘移动,对每个结点均途径三次,最后回到根结点。
2.遍历序列
⑴ 中序序列
中序遍历二叉树时,对结点的访问次序为中序序列
【例】中序遍历上图所示的二叉树时,得到的中序序列为:
D B A E C F
⑵ 先序序列
先序遍历二叉树时,对结点的访问次序为先序序列
【例】先序遍历上图所示的二叉树时,得到的先序序列为:
A B D C E F
⑶ 后序序列
后序遍历二叉树时,对结点的访问次序为后序序列
【例】后序遍历上图所示的二叉树时,得到的后序序列为:
D B E F C A
注意⑴ 在搜索路线中,若访问结点均是第一次经过结点时进行的,则是前序遍历;若访问结点均是在第二次(或第三次)经过结点时进行的,则是中序遍历(或后序遍历)。只要将搜索路线上所有在第一次、第二次和第三次经过的结点分别列表,即可分别得到该二叉树的前序序列、中序序列和后序序列。
⑵ 上述三种序列都是线性序列,有且仅有一个开始结点和一个终端结点,其余结点都有且仅有一个前趋结点和一个后继结点。为了区别于树形结构中前趋(即双亲)结点和后继(即孩子)结点的概念,对上述三种线性序列,要在某结点的前趋和后继之前冠以其遍历次序名称。
【例】上图所示的二叉树中结点C,其前序前趋结点是D,前序后继结点是E;中序前趋结点是E,中序后继结点是F;后序前趋结点是F,后序后继结点是A。但是就该树的逻辑结构而言,C的前趋结点是A,后继结点是E和F。
二叉链表的构造
1. 基本思想 基于先序遍历的构造,即以二叉树的先序序列为输入构造。
注意:
先序序列中必须加入虚结点以示空指针的位置。
【例】
建立上图所示二叉树,其输入的先序序列是:ABD∮∮CE∮∮F∮∮。
2. 构造算法
假设虚结点输入时以空格字符表示,相应的构造算法为:
void CreateBinTree (BinTree *T)
{ //构造二叉链表。T是指向根指针的指针,故修改*T就修改了实参(根指针)本身
char ch;
if((ch=getchar())=='') *T=NULL; //读入空格,将相应指针置空
else{ //读入非空格
*T=(BinTNode *)malloc(sizeof(BinTNode)); //生成结点
(*T)->data=ch;
CreateBinTree(&(*T)->lchild); //构造左子树
CreateBinTree(&(*T)->rchild); //构造右子树
}
}
注意:调用该算法时,应将待建立的二叉链表的根指针的地址作为实参。
图的遍历简介遍历算法是计算机领域中的一个重要的研究方向,一个问题的求解就是从最开始的状态,利用已经存在的规则和条件改变当前状态,直到把当前状态变为最终目的状态,把中间出现的状态全部连接起来,变成一条遍历路径的过程。通过图的遍历,我们可以找到这条径2。图的遍历算法主要有两种,一种是按照深度优先的顺序展开遍历的算法,也就是深度优先遍历;另一种是按照宽度优先的顺序展开遍历的算法,也就是宽度优先遍历。宽度优先遍历是沿着图的深度遍历图的所有节点,每次遍历都会沿着当前节点的邻接点遍历,直到所有点全部遍历完成。如果当前节点的所有邻接点都遍历过了,则回溯到上一个节点,重复这一过程一直到已访问从源节点可达的所有节点为止。如果还存在没有被访问的节点,则选择其中一个节点作为源节点并重复以上过程,直到所有节点都被访问为止。利用图的深度优先搜索可以获得很多额外的信息,也可以解决很多图论的问题。宽度优先遍历又名广度优先遍历。通过沿着图的宽度遍历图的节点,如果所有节点均被访问,算法随即终止。宽度优先遍历的实现一般需要一个队列来辅助完成。 宽度优先遍历和深度优先遍历一样也是一种盲目的遍历方法。也就是说,宽度遍历算法并不使用经验法则算法, 并不考虑结果的可能地址,只是彻底地遍历整张图,直到找到结果为止。图的遍历问题分为四类:
遍历完所有的边而不能有重复,即所谓“欧拉路径问题”(又名一笔画问题);
遍历完所有的顶点而没有重复,即所谓“哈密顿路径问题”。
遍历完所有的边而可以有重复,即所谓“中国邮递员问题”;
遍历完所有的顶点而可以重复,即所谓“旅行推销员问题”。
对于第一和第三类问题已经得到了完满的解决,而第二和第四类问题则只得到了部分解决。第一类问题就是研究所谓的欧拉图的性质,而第二类问题则是研究所谓的哈密顿图的性质。
深度优先图的深度优先遍历的递归定义:
假设给定图G的初态是所有顶点均未曾访问过。在G中任选一顶点v为初始出发点(源点),则深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。图的深度优先遍历类似于树的前序遍历。采用的搜索方法的特点是尽可能先对纵深方向进行搜索。这种搜索方法称为深度优先搜索(Depth-First Search)。相应地,用此方法遍历图就很自然地称之为图的深度优先遍历。
深度优先搜索的过程
设x是当前被访问顶点,在对x做过访问标记后,选择一条从x出发的未检测过的边(x,y)。若发现顶点y已访问过,则重新选择另一条从x出发的未检测过的边,否则沿边(x,y)到达未曾访问过的y,对y访问并将其标记为已访问过;然后从y开始搜索,直到搜索完从y出发的所有路径,即访问完所有从y出发可达的顶点之后,才回溯到顶点x,并且再选择一条从x出发的未检测过的边。上述过程直至从x出发的所有边都已检测过为止。此时,若x不是源点,则回溯到在x之前被访问过的顶点;否则图中所有和源点有路径相通的顶点(即从源点可达的所有顶点)都已被访问过,若图G是连通图,则遍历过程结束,否则继续选择一个尚未被访问的顶点作为新源点,进行新的搜索过程。
算法实现
platevoidDigraph::depth_first(void(*visit)(Vertex&))const/*Post:Thefunction*visithasbeenperformedateachvertexoftheDigraphindepth-firstorder.Uses:Methodtraversetoproducetherecursivedepth-firstorder.*/{boolvisited[max_size];Vertexv;for(allvinG)visited[v]=false;for(allvinG)if(!visited[v])traverse(v,visited,visit);}templatevoidDigraph::traverse(Vertex&v,boolvisited[],void(*visit)(Vertex&))const/*Pre:visavertexoftheDigraph.Post:Thedepth-firsttraversal,usingfunction*visit,hasbeencompletedforvandforallverticesthatcanbereachedfromv.Uses:traverserecursively.*/{Vertexw;visited[v]=true;(*visit)(v);for(allwadjacenttov)if(!visited[w])traverse(w,visited,visit);}广度优先基本思想
**1、**从图中某个顶点V0出发,并访问此顶点;
**2、**从V0出发,访问V0的各个未曾访问的邻接点W1,W2,…,Wk;然后,依次从W1,W2,…,Wk出发访问各自未被访问的邻接点;
**3、**重复步骤2,直到全部顶点都被访问为止。
广度优先遍历的性质
与深度优先遍历类似,广度优先遍历也有许多有用的特性:
**1、**广度优先生成树
在广度优先遍历中,如果将每次“前进”(纵深)路过的(将被访问的)结点和边都记录下来,就得到一个子图,该子图为以出发点为根的树,称为广度优先生成树。这种情况与深度优先遍历类似。
类似地,也可以给广度优先生成树结点定义时间戳。
**2、**最短路径
显然,从v0出发广度优先遍历图,将得到v0到它的各个可达到的路径。我们这里定义路径上的边的数目为路径长度。与深度优先遍历不同,广度优先遍历得到的v0到各点的路径是最短路径(未考虑边权)。
算法实现
templatevoidDigraph::breadth_first(void(*visit)(Vertex&))const/*Post:Thefunction*visithasbeenperformedateachvertexoftheDigraphinbreadth-firstorder.Uses:MethodsofclassQueue.*/{Queueq;boolvisited[max_size];Vertexv,w,x;for(allvinG)visited[v]=false;for(allvinG)if(!visited[v]){q.append(v);while(!q.empty()){q.retrieve(w);if(!visited[w]){visited[w]=true;(*visit)(w);for(allxadjacenttow)q.append(x);}q.serve();}}}与深度优先遍历的比较
广度优先遍历与深度优先遍历的区别在于:广度优先遍历是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索;而深度优先遍历是将某一条枝桠上的所有节点都搜索到了之后,才转向搜索另一条枝桠上的所有节点。
深度优先遍历从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续找它的下一个新的顶点进行访问,重复此步骤,直到所有结点都被访问完为止。
广度优先遍历从某个顶点出发,首先访问这个顶点,然后找出这个结点的所有未被访问的邻接点,访问完后再访问这些结点中第一个邻接点的所有结点,重复此方法,直到所有结点都被访问完为止。
可以看到两种方法最大的区别在于前者从顶点的第一个邻接点一直访问下去再访问顶点的第二个邻接点;后者从顶点开始访问该顶点的所有邻接点再依次向下,一层一层的访问。
古汉语词语释义遍:全面,到处;如遍布、遍及、遍野、普遍。历:行、游历、周游伏轼撙衔,横历天下,出自《战国策》。历聘(游历天下以求聘用);历国(游历各国);历行(遍行,走遍);历块(穿过一国如过一小块土地);历说(游说)。
遍历就是全部走遍,到处周游的意思;古文中还有一种遍历的用法:如:乃以是履弃之于道旁,即遍历人家捕之,若有女履者,捕之以告。这里的遍是全面、到处的意思;而历,在这里应当作逐一、逐个地的来讲。所以这里的遍历的意思是全部逐一的。
遍历名山,博采方术。——前蜀· 杜光庭《李筌》
宋 陆游 《舟中晓赋》诗:“高樯健席从今始,遍历三湘与五湖。”
清 戴名世 《自序》:“自燕逾济 ,游于渤海之滨,遍历齐鲁之境。”
释玄奘,陈留人。贞观三年出关西行,遍历诸国;
(郑和)自苏州刘家河泛海至福建,复自福建五虎门扬帆,首达占域,以次遍历诸国"。
本词条内容贡献者为:
徐恒山 - 讲师 - 西北农林科技大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国