

介绍
将交叉熵引入计算语言学消岐领域,采用语句的真实语义作为交叉熵的训练集的先验信息,将机器翻译的语义作为测试集后验信息。计算两者的交叉熵,并以交叉熵指导对歧义的辨识和消除。实例表明,该方法简洁有效.易于计算机自适应实现。交叉熵不失为计算语言学消岐的一种较为有效的工具。
在信息论中,交叉熵是表示两个概率分布p,q,其中p表示真实分布,q表示非真实分布,在相同的一组事件中,其中,用非真实分布q来表示某个事件发生所需要的平均比特数。从这个定义中,我们很难理解交叉熵的定义。下面举个例子来描述一下:
假设现在有一个样本集中两个概率分布p,q,其中p为真实分布,q为非真实分布。假如,按照真实分布p来衡量识别一个样本所需要的编码长度的期望为:
H(p)=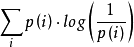
但是,如果采用错误的分布q来表示来自真实分布p的平均编码长度,则应该是:
H(p,q)=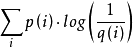
此时就将H(p,q)称之为交叉熵。交叉熵的计算方式如下:
对于离散变量采用以下的方式计算:H(p,q)=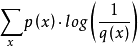
对于连续变量采用以下的方式计算:
应用交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。1
在特征工程中,可以用来衡量两个随机变量之间的相似度。
在语言模型中(NLP)中,由于真实的分布p是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。2
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国