

感知器,也可翻译为感知机,是Frank Rosenblatt在1957年就职于Cornell航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈式人工神经网络,是一种二元线性分类器。2
Frank Rosenblatt给出了相应的感知器学习算法,常用的有感知机学习、最小二乘法和梯度下降法。譬如,感知机利用梯度下降法对损失函数进行极小化,求出可将训练数据进行线性划分的分离超平面,从而求得感知器模型。
感知器是生物神经细胞的简单抽象,如右图.神经细胞结构大致可分为:树突、突触、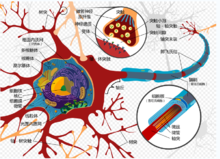 细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’,而未激动时为‘否’。
细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’,而未激动时为‘否’。
神经细胞的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会激动,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。为了模拟神经细胞行为,与之对应的感知机基础概念被提出,如权量(突触)、偏置(阈值)及激活函数(细胞体)。
在人工神经网络领域中,感知器也被指为单层的人工神经网络,以区别于较复杂的多层感知器(Multilayer Perceptron)。 作为一种线性分类器,(单层)感知器可说是最简单的前向人工神经网络形式。尽管结构简单,感知器能够学习并解决相当复杂的问题。感知器主要的本质缺陷是它不能处理线性不可分问题。
起源1943年,心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of the ideas immanent in nervous activity》论文中提出并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。31949年,心理学家唐纳德·赫布在《The Organization of Behavior》论文中描述了神经元学习法则。
人工神经网络更进一步被美国神经学家 Frank Rosenblatt 所发展。他提出了可以 模拟人类感知能力的机器,并称之为‘感知机’。1957年,在 Cornell 航空实验室中,他成功在IBM 704机上完成了感知机的仿真。两年后,他又成功实现了能够识别一些英文字母、基于感知机的神经计算机——Mark1,并于1960年6月23日,展示与众。
模拟人类感知能力的机器,并称之为‘感知机’。1957年,在 Cornell 航空实验室中,他成功在IBM 704机上完成了感知机的仿真。两年后,他又成功实现了能够识别一些英文字母、基于感知机的神经计算机——Mark1,并于1960年6月23日,展示与众。
为了‘教导’感知机识别图像,Rosenblatt,在Hebb 学习法则的基础上,发展了一种迭代、试错、类似于人类学习过程的学习算法——感知机学习。除了能够识别出现较多次的字母,感知机也能对不同书写方式的字母图像进行概括和归纳。但是,由于本身的局限,感知机除了那些包含在训练集里的图像以外,不能对受干扰(半遮蔽、不同大小、平移、旋转)的字母图像进行可靠的识别。
首个有关感知器的成果,由 Rosenblatt 于1958年发表在《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》的文章里。1962年,他又出版了《Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms》一书,向大众深入解释感知机的理论知识及背景假设。此书介绍了一些重要的概念及定理证明,例如感知机收敛定理。
虽然最初被认为有着良好的发展潜能,但感知机最终被证明不能处理诸多的模式识别问题。1969年,Marvin Minsky 和 Seymour Papert 在《Perceptrons》书中,仔细分析了以感知机为代表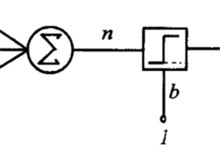 的单层神经网络系统的功能及局限,证明感知机不能解决简单的异或(XOR)等线性不可分问题,但 Rosenblatt 和 Minsky 及 Papert 等人在当时已经了解到多层神经网络能够解决线性不可分的问题。
的单层神经网络系统的功能及局限,证明感知机不能解决简单的异或(XOR)等线性不可分问题,但 Rosenblatt 和 Minsky 及 Papert 等人在当时已经了解到多层神经网络能够解决线性不可分的问题。
由于 Rosenblatt 等人没能够及时推广感知机学习算法到多层神经网络上,又由于《Perceptrons》在研究领域中的巨大影响,及人们对书中论点的误解,造成了人工神经领域发展的长年停滞及低潮,直到人们认识到多层感知机没有单层感知机固有的缺陷及反向传播算法在80年代的提出,才有所恢复。1987年,书中的错误得到了校正,并更名再版为《Perceptrons - Expanded Edition》。
在 Freund 及 Schapire (1998)使用核技巧改进感知器学习算法之后,愈来愈多的人对感知机学习算法产生兴趣。后来的研究表明除了二元分类,感知机也能应用在较复杂、被称为 structured learning 类型的任务上(Collins, 2002),又或使用在分布式计算环境中的大规模机器学习问题上(McDonald, Hall andMann,2011)。
数学描述感知器使用特征向量来表示的前馈式人工神经网络,它是一种二元分类器,把矩阵上的输入(实数值向量)映射到输出值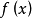 上(一个二元的值)。
上(一个二元的值)。
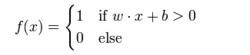
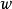 是实数的表式权重的向量,
是实数的表式权重的向量,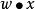 是点积。
是点积。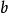 是偏置,一个不依赖于任何输入值的常数。偏置可以认为是激励函数的偏移量,或者给神经元一个基础活跃等级。
是偏置,一个不依赖于任何输入值的常数。偏置可以认为是激励函数的偏移量,或者给神经元一个基础活跃等级。
(0 或 1)用于对进行分类,看它是肯定的还是否定的,这属于二元分类问题。如果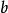 是负的,那么加权后的输入必须产生一个肯定的值并且大于
是负的,那么加权后的输入必须产生一个肯定的值并且大于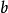 ,这样才能令分类神经元大于阈值0。从空间上看,偏置改变了决策边界的位置(虽然不是定向的)。
,这样才能令分类神经元大于阈值0。从空间上看,偏置改变了决策边界的位置(虽然不是定向的)。
由于输入直接经过权重关系转换为输出,所以感知机可以被视为最简单形式的前馈式人工神经网络。
感知器算法改进附加动量法它在标准的 BP 算法修正 权值时,在每一个权重的变化上加上一项动量因 子,动量因子正比于上一次权重变化量的值,并 根据反向传播法来产生新的权重的变化。在没有 附加动量的作用下,网络可能陷入局部极小值, 利用附加动量的作用有可能跳过这些极小值。这 是因为附加动量法在修正其权值时,考虑了在误 差曲面上变化趋势的影响,从而抑制了局部极小, 找到误差曲面的全局最小值。这里动量因子实质 上起到了缓冲的作用,它减小了学习过程的振荡 现象,一定程度上加快了 BP 算法的收敛速度。1
自适应学习速率算法标准 BP 算法的 学习速率采用的是确定值,学习速率的选择非常 重要,学习速率选得小虽然有利于总误差缩小, 但会导致收敛速度过慢。学习速率选取得太大, 则有可能导致无法收敛。为了解决这一问题,可 以采用自适应调整学习效率的改进算法,此算法 的基本思想是根据误差变化而自适应调整。如果 权值修正后确实降低了误差函数,则说明所选取 的学习速率值小了,应增大学习速率; 如果没有则说明学习速率调得过大,应减 小学习速率。总之使权值的调整向误差减小的方 向变化。自适应学习速率算法可以缩短训练时间。1
动量 - 自适应学习速率调整算法这一 算法采用了附加动量法和自适应学习速率法两种 方法的结合,既可以找到全局最优解,也可以缩 短训练时间。此外,还有学者提出了隐含层节点 和学习效率动态全参数自适应调整等算法,有效 地改善了收敛效果。 另一类 BP 改进算法是对其进行了数学上的优 化,如拟牛顿法在搜索方向上进行了改进; 共轭梯度法则是在收敛速度和计算复杂度上均能取得 较好效果,特别是用于网络权值较多的情形 ; Levenberg - Marquardt 法则结合了梯度下降和牛 顿法的优点,在网络权值不多的情形下,收敛速 度很快,优点突出。1
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国