

运算原理
搜索算法实际上是根据初始条件和扩展规则构造一棵“解答树”并寻找符合目标状态的节点的过程。所有的搜索算法从最终的算法实现上来看,都可以划分成两个部分——控制结构(扩展节点的方式)和产生系统(扩展节点),而所有的算法优化和改进主要都是通过修改其控制结构来完成的。其实,在这样的思考过程中,我们已经不知不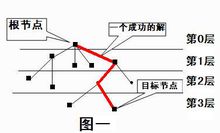 觉地将一个具体的问题抽象成了一个图论的模型——树,即搜索算法的使用第一步在于搜索树的建立。
觉地将一个具体的问题抽象成了一个图论的模型——树,即搜索算法的使用第一步在于搜索树的建立。
由图一可以知道,这样形成的一棵树叫搜索树。初始状态对应着根节点,目标状态对应着目标结点。排在前的结点叫父结点,其后的结点叫子结点,同一层中的结点是兄弟结点,由父结点产生子结点叫扩展。完成搜索的过程就是找到一条从根结点到目标结点的路径,找出一个最优的解。这种搜索算法的实现类似于图或树的遍历,通常可以有两种不同的实现方法,即深度优先搜索****(DFS——Depth First search)和广度优先搜索****(BFS——Breadth First Search)。
主要分类深度优先搜索如算法名称那样,深度优先搜索所遵循的搜索策略是尽可能“深”地搜索树。它的基本思想是:为了求得问题的解,先选择某一种可能情况向前(子结点)探索,在探索过程中,一旦发现原来的选择不符合要求,就回溯至父亲结点重新选择另一结点,继续向前探索,如此反复进行,直至求得最优解。深度优先搜索的实现方式可以采用递归或者栈来实现。由此可见,把通常问题转化为树的问题是至关重要的一步,完成了树的转换基本完成了问题求解。
(1)减少节点数,思想:尽可能减少生成的节点数
(2)定制回溯边界,思想:定制回溯边界条件,剪掉不可能得到最优解的子树
在很多情况下,我们已经找到了一组比较好的解。但是计算机仍然会义无返顾地去搜索比它更“劣”的其他解,搜索到后也只能回溯。为了避免出现这种情况,我们需要灵活地去定制回溯搜索的边界。
在深度优先搜索的过程当中,往往有很多走不通的“死路”。假如我们把这些“死路”排除在外,不是可以节省很多的时间吗?打一个比方,前面有一个路径,别人已经提示:“这是死路,肯定不通”,而你的程序仍然很“执着”地要继续朝这个方向走,走到头来才发现,别人的提示是正确的。这样,浪费了很多的时间。针对这种情况,我们可以把“死路”给标记一下不走,就可以得到更高的搜索效率。
广度优先搜索类似树的按层遍历,其过程为:首先访问初始点Vi,并将其标记为已访问过,接着访问Vi的所有未被访问过可到达的邻接点Vi1、Vi2……Vit,并均标记为已访问过,然后再按照Vi1、Vi2……Vit的次序,访问每一个顶点的所有未被访问过的邻接点,并均标记为已访问过,依此类推,直到图中所有和初始点Vi有路径相通的顶点都被访问过为止。
对于状态数很多时,广度优先搜索可以采用循环队列或动态链表来处理,对于这两种搜索算法,其主要区别如下表:
|| ||
双向广度优先搜索在广度优先搜索的基础上进行优化,采用双向搜索的方式,即从起始节点向目标节点方向搜索,同时从目标节点向起始节点方向搜索。1
特点:1.双向搜索只能用于广度优先搜索中。
2.双向搜索扩展的节点数量要比单向少的多。
A*算法A*算法是利用问题的规则和特点来制定一些启发规则,由此来改变节点的扩展顺序,将最有希望扩展出最优解的节点优先扩展,使得尽快找到最优解。1
对每一个节点,有一个估价函数F来估算起始节点经过该节点到达目标节点的最佳路径的代价。
每个节点扩展的时候,总是选择具有最小的F的节点。
F=G+B×H:G为从起始节点到当前节点的实际代价,已经算出,H为从该节点到目标节点的最优路径的估计代价。F要单调递增。
B最好随着搜索深度成反比变化,在搜索深度浅的地方,主要让搜索依靠启发信息,尽快的逼近目标,而当搜索深的时候,逐渐变成广度优先搜索。
散列函数散列函数(或散列算法,又称哈希函数,英语:Hash Function)是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
Rabin-Karp字符串搜索算法是一个相对快速的字符串搜索算法,它所需要的平均搜索时间是O(n).这个算法是创建在使用散列来比较字符串的基础上的。2
优化利用回溯算法进行优化:回溯和深度优先相似,不同之处在于对一个节点扩展的时候,并不将所有的子节点扩展出来,而只扩展其中的一个。因而具有盲目性,但内存占用少。
在搜索中的优化:1.在搜索前,根据条件降低搜索规模。2.广度优先搜索中,被处理过的节点,充分释放空间。3.给据问题的约束条件进行剪枝。
在剪枝时应遵循以下原则:
(1)正确性:剪去的“枝条”不包含最优答案;
我们知道,剪枝方法之所以能够优化程序的执行效率,是因为它能够“剪去”搜索树中的一些“枝条”。然而,如果在剪枝的时候,将“长有”我们所需要的解的枝条也剪掉了,那么,一切优化也就都失去了意义。所以,对剪枝的第一个要求就是正确性,即必须保证不丢失正确的结果,这是剪枝优化的前提。
为了满足这个原则,计算机应当利用“必要条件”来进行剪枝判断。也就是说,通过解所必须具备的特征、必须满足的条件等方面来考察待判断的枝条能否被剪枝。这样就可以保证所剪掉的枝条一定不是正解所在的枝条。当然,由必要条件的定义,没有被剪枝不意味着一定可以得到正解(否则,也就不必搜索了)。
(2)准确性:在保证第一条原则的情况下,尽可能的剪去更多不包含最优答案的枝条;
在保证了正确性的基础上,对剪枝判断的第二个要求就是准确性,即能够尽可能多的剪去不能通向正解的枝条。剪枝方法只有在具有了较高的准确性的时候,才能真正收到优化的效果。因此,准确性可以说是剪枝优化的生命。
(3)高效性:通过剪枝要能够更快的接近到达最优解。
一般说来,设计好剪枝判断方法之后,我们对搜索树的每个枝条都要执行一次判断操作。然而,由于是利用出解的“必要条件”进行判断,所以,必然有很多不含正解的枝条没有被剪枝。这些情况下的剪枝判断操作,对于程序的效率的提高无疑是具有副作用的。为了尽量减少剪枝判断的副作用,我们除了要下功夫改善判断的准确性外,经常还需要提高判断操作本身的时间效率。
然而这就带来了一个矛盾:我们为了加强优化的效果,就必须提高剪枝判断的准确性,因此,常常不得不提高判断操作的复杂度,也就同时降低了剪枝判断的时间效率;但是,如果剪枝判断的时间消耗过多,就有可能减小、甚至完全抵消提高判断准确性所能带来的优化效果,这恐怕也是得不偿失。很多情况下,能否较好的解决这个矛盾,往往成为搜索算法优化的关键。3
应用案例**(1)题目:黑白棋游戏**
黑白棋游戏的棋盘由4×4方格阵列构成。棋盘的每一方格中放有1枚棋子,共有8枚白棋子和8枚黑棋子。这16枚棋子的每一种放置方案都构成一个游戏状态。在棋盘上拥有1条公共边的2个方格称为相邻方格。一个方格最多可有4个相邻方格。在玩黑白棋游戏时,每一步可将任何2个相邻方格中棋子互换位置。对于给定的初始游戏状态和目标游戏状态,编程计算从初始游戏状态变化到目标游戏状态的最短着棋序列。
(2)分析
这题我们可以想到用深度优先搜索来做,但是如果下一步出现了以前的状态怎么办?直接判断时间复杂度的可能会有点大,这题的最优解法是用广度优先搜索来做。我们就可以有初始状态按照广度优先搜索遍历来扩展每一个点,这样到达目标状态的步数一定是最优的(步数的增加时单调的)。但问题是如果出现了重复的情况我们就必须要判重,但是朴素的判重是可以达到状态数级别的,其实我们可以考虑用hash表来判重。
Hash表:思路是根据关键码值进行直接访问。也就是说把一个关键码值映射到表中的一个位置来访问记录的过程。在Hash表中,一般插入,查找的时间复杂度可以在O(1)的时间复杂度内搞定。对于这一题我们可以用二进制值表示其hash值,最多2^16次方,所以我们开个2^16次方的表记录这个状态出现没有,这样可以在O(1)的时间复杂度内解决判重问题。
进一步考虑:从初始状态到目标状态,必定会产生很多无用的状态,那还有什么优化可以减少这时间复杂度?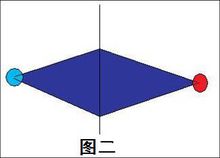 我们可以考虑把初始状态和目标状态一起扩展,这样如果初始状态的某个被扩展的点与目标状态所扩展的点相同时,那这两个点不用扩展下去,而两个扩展的步数和也就是答案。
我们可以考虑把初始状态和目标状态一起扩展,这样如果初始状态的某个被扩展的点与目标状态所扩展的点相同时,那这两个点不用扩展下去,而两个扩展的步数和也就是答案。
上面的想法是双向广度优先搜索:
就像图二一样,多扩展了很多不必要的状态。
从上面一题可以看到我们用到了两种优化方法,即Hash表优化和双向广搜优化。一般的广度优先搜索用这两个优化就足以解决。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国