

背景
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。机器能否像人类一样能具有学习能力呢?1959年美国的塞缪尔(Samuel)设计了一个下棋程序,这个程序具有学习能力,它可以在不断的对弈中改善自己的棋艺。4年后,这个程序战胜了设计者本人。又过了3年,这个程序战胜了美国一个保持8年之久的常胜不败的冠军。这个程序向人们展示了机器学习的能力,提出了许多令人深思的社会问题与哲学问题。3
基础概念深度从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示:流向图是一种能够表示计算的图,在这种图中每一个节点表示一个基本的计算以及一个计算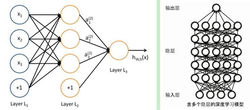 的值,计算的结果被应用到这个节点的子节点的值。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有父节点,输出节点没有子节点。
的值,计算的结果被应用到这个节点的子节点的值。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有父节点,输出节点没有子节点。
这种流向图的一个特别属性是深度(depth):从一个输入到一个输出的最长路径的长度。
传统的前馈神经网络能够被看做拥有等于层数的深度(比如对于输出层为隐层数加1)。SVMs有深度2(一个对应于核输出或者特征空间,另一个对应于所产生输出的线性混合)。4
人工智能研究的方向之一,是以所谓 “专家系统” 为代表的,用大量 “如果-就” (If - Then) 规则定义的,自上而下的思路。人工神经网络 ( Artifical Neural Network),标志着另外一种自下而上的思路。神经网络没有一个严格的正式定义。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。5
解决问题需要使用深度学习解决的问题有以下的特征:
深度不足会出现问题。
人脑具有一个深度结构。
认知过程逐层进行,逐步抽象。
深度不足会出现问题在许多情形中深度2就足够表示任何一个带有给定目标精度的函数。但是其代价是:图中所需要的节点数(比如计算和参数数量)可能变的非常大。理论结果证实那些事实上所需要的节点数随着输入的大小指数增长的函数族是存在的。
我们可以将深度架构看做一种因子分解。大部分随机选择的函数不能被有效地表示,无论是用深的或者浅的架构。但是许多能够有效地被深度架构表示的却不能被用浅的架构高效表示。一个紧的和深度的表示的存在意味着在潜在的可被表示的函数中存在某种结构。如果不存在任何结构,那将不可能很好地泛化。
大脑有一个深度架构
例如,视觉皮质得到了很好的研究,并显示出一系列的区域,在每一个这种区域中包含一个输入的表示和从一个到另一个的信号流(这里忽略了在一些层次并行路径上的关联,因此更复杂)。这个特征层次的每一层表示在一个不同的抽象层上的输入,并在层次的更上层有着更多的抽象特征,他们根据低层特征定义。
需要注意的是大脑中的表示是在中间紧密分布并且纯局部:他们是稀疏的:1%的神经元是同时活动的。给定大量的神经元,仍然有一个非常高效地(指数级高效)表示。
认知过程逐层进行,逐步抽象
人类层次化地组织思想和概念;
人类首先学习简单的概念,然后用他们去表示更抽象的;
工程师将任务分解成多个抽象层次去处理;
学习/发现这些概念(知识工程由于没有反省而失败?)是很美好的。对语言可表达的概念的反省也建议我们一个稀疏的表示:仅所有可能单词/概念中的一个小的部分是可被应用到一个特别的输入(一个视觉场景)。64
基本思想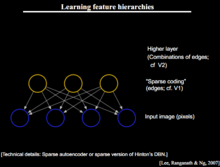
假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I =>S1=>S2=>…..=>Sn => O,如果输出O等于输入I,即输入I经过这个系统变化之后没有任何的信息损失,设处理a信息得到b,再对b处理得到c,那么可以证明:a和c的互信息不会超过a和b的互信息。这表明信息处理不会增加信息,大部分处理会丢失信息。保持了不变,这意味着输入I经过每一层Si都没有任何的信息损失,即在任何一层Si,它都是原有信息(即输入I)的另外一种表示。现在回到主题Deep Learning,需要自动地学习特征,假设我们有一堆输入I(如一堆图像或者文本),假设设计了一个系统S(有n层),通过调整系统中参数,使得它的输出仍然是输入I,那么就可以自动地获取得到输入I的一系列层次特征,即S1,…, Sn。3
对于深度学习来说,其思想就是对堆叠多个层,也就是说这一层的输出作为下一层的输入。通过这种方式,就可以实现对输入信息进行分级表达了。3
另外,前面是假设输出严格地等于输入,这个限制太严格,可以略微地放松这个限制,例如只要使得输入与输出的差别尽可能地小即可,这个放松会导致另外一类不同的Deep Learning方法。上述就是Deep Learning的基本思想。3
把学习结构看作一个网络,则深度学习的核心思路如下:
①无监督学习用于每一层网络的pre-train;
②每次用无监督学习只训练一层,将其训练结果作为其高一层的输入;
③用自顶而下的监督算法去调整所有层
主要技术线性代数、概率和信息论
欠拟合、过拟合、正则化
最大似然估计和贝叶斯统计
随机梯度下降
监督学习和无监督学习
深度前馈网络、代价函数和反向传播
正则化、稀疏编码和dropout
自适应学习算法
卷积神经网络
循环神经网络
递归神经网络
深度神经网络和深度堆叠网络
LSTM长短时记忆
主成分分析
正则自动编码器
表征学习
蒙特卡洛
受限波兹曼机
深度置信网络
softmax回归、决策树和聚类算法
KNN和SVM
生成对抗网络和有向生成网络
机器视觉和图像识别
自然语言处理
语音识别和机器翻译
有限马尔科夫
动态规划
梯度策略算法
增强学习(Q-learning)
转折点
2006年前,尝试训练深度架构都失败了:训练一个深度有监督前馈神经网络趋向于产生坏的结果(同时在训练和测试误差中),然后将其变浅为1(1或者2个隐层)。
2006年的3篇论文改变了这种状况,由Hinton的革命性的在深度信念网(Deep Belief Networks, DBNs)上的工作所引领:
Hinton, G. E., Osindero, S. and Teh, Y.,A fast learning algorithm for deep belief nets.Neural Computation 18:1527-1554, 2006
Yoshua Bengio, Pascal Lamblin, Dan Popovici and Hugo Larochelle,Greedy LayerWise Training of Deep Networks, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems 19 (NIPS 2006), pp. 153-160, MIT Press, 2007
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra and Yann LeCun Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2007
在这三篇论文中以下主要原理被发现:
表示的无监督学习被用于(预)训练每一层;
在一个时间里的一个层次的无监督训练,接着之前训练的层次。在每一层学习到的表示作为下一层的输入;
用有监督训练来调整所有层(加上一个或者更多的用于产生预测的附加层);
DBNs在每一层中利用用于表示的无监督学习RBMs。Bengio et al paper 探讨和对比了RBMs和auto-encoders(通过一个表示的瓶颈内在层预测输入的神经网络)。Ranzato et al paper在一个convolutional架构的上下文中使用稀疏auto-encoders(类似于稀疏编码)。Auto-encoders和convolutional架构将在以后的课程中讲解。
从2006年以来,大量的关于深度学习的论文被发表。
成功应用1、计算机视觉
ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, NIPS 2012.
Learning Hierarchical Features for Scene Labeling, Clement Farabet, Camille Couprie, Laurent Najman and Yann LeCun, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013.
Learning Convolutional Feature Hierarchies for Visual Recognition, Koray Kavukcuoglu, Pierre Sermanet, Y-Lan Boureau, Karol Gregor, Michaël Mathieu and Yann LeCun, Advances in Neural Information Processing Systems (NIPS 2010), 23, 2010.
2、语音识别
微软研究人员通过与hinton合作,首先将RBM和DBN引入到语音识别声学模型训练中,并且在大词汇量语音识别系统中获得巨大成功,使得语音识别的错误率相对减低30%。但是,DNN还没有有效的并行快速算法,很多研究机构都是在利用大规模数据语料通过GPU平台提高DNN声学模型的训练效率。
在国际上,IBM、google等公司都快速进行了DNN语音识别的研究,并且速度飞快。
国内方面,阿里巴巴,科大讯飞、百度、中科院自动化所等公司或研究单位,也在进行深度学习在语音识别上的研究。
3、自然语言处理等其他领域
很多机构在开展研究,2013年Tomas Mikolov,Kai Chen,Greg Corrado,Jeffrey Dean发表论文Efficient Estimation of Word Representations in Vector Space建立word2vector模型,与传统的词袋模型(bag of words)相比,word2vector能够更好地表达语法信息。7深度学习在自然语言处理等领域主要应用于机器翻译以及语义挖掘等方面。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国