

基本概念
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成1。
一致性检查一致性检查(consistency check)是根据每个变量的合理取值范围和相互关系,检查数据是否合乎要求,发现超出正常范围、逻辑上不合理或者相互矛盾的数据。例如,用1-7级量表测量的变量出现了0值,体重出现了负数,都应视为超出正常值域范围。SPSS、SAS、和Excel等计算机软件都能够根据定义的取值范围,自动识别每个超出范围的变量值。具有逻辑上不一致性的答案可能以多种形式出现:例如,许多调查对象说自己开车上班,又报告没有汽车;或者调查对象报告自己是某品牌的重度购买者和使用者,但同时又在熟悉程度量表上给了很低的分值。发现不一致时,要列出问卷序号、记录序号、变量名称、错误类别等,便于进一步核对和纠正。
无效值和缺失值的处理由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
采用不同的处理方法可能对分析结果产生影响,尤其是当缺失值的出现并非随机且变量之间明显相关时。因此,在调查中应当尽量避免出现无效值和缺失值,保证数据的完整性2。
数据清洗原理数据清洗原理:利用有关技术如数理统计、数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。
主要类型残缺数据这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
错误数据这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
重复数据对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
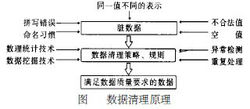
数据清洗的方法一般来说,数据清理是将数据库精简以除去重复记录,并使剩余部分转换成标准可接收格式的过程。数据清理标准模型是将数据输入到数据清理处理器,通过一系列步骤“ 清理”数据,然后以期望的格式输出清理过的数据(如上图所示)。数据清理从数据的准确性、完整性、一致性、惟一性、适时性、有效性几个方面来处理数据的丢失值、越界值、不一致代码、重复数据等问题。
数据清理一般针对具体应用,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出相应的数据清理方法。
1.解决不完整数据( 即值缺失)的方法
大多数情况下,缺失的值必须手工填入( 即手工清理)。当然,某些缺失值可以从本数据源或其它数据源推导出来,这就可以用平均值、最大值、最小值或更为复杂的概率估计代替缺失的值,从而达到清理的目的。
2.错误值的检测及解决方法
用统计分析的方法识别可能的错误值或异常值,如偏差分析、识别不遵守分布或回归方程的值,也可以用简单规则库( 常识性规则、业务特定规则等)检查数据值,或使用不同属性间的约束、外部的数据来检测和清理数据。
3.重复记录的检测及消除方法
数据库中属性值相同的记录被认为是重复记录,通过判断记录间的属性值是否相等来检测记录是否相等,相等的记录合并为一条记录(即合并/清除)。合并/清除是消重的基本方法。
4.不一致性( 数据源内部及数据源之间)的检测及解决方法
从多数据源集成的数据可能有语义冲突,可定义完整性约束用于检测不一致性,也可通过分析数据发现联系,从而使得数据保持一致。目前开发的数据清理工具大致可分为三类。
数据迁移工具允许指定简单的转换规则,如:将字符串gender替换成sex。sex公司的PrismWarehouse是一个流行的工具,就属于这类。
数据清洗工具使用领域特有的知识( 如,邮政地址)对数据作清洗。它们通常采用语法分析和模糊匹配技术完成对多数据源数据的清理。某些工具可以指明源的“ 相对清洁程度”。工具Integrity和Trillum属于这一类。
数据审计工具可以通过扫描数据发现规律和联系。因此,这类工具可以看作是数据挖掘工具的变形3。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国