

起源与发展
半监督学习的研究的历史可以追溯到20世纪70年代,这一时期,出现了自训练(Self-Training)、直推学习(Transductive Learning)、生成式模型(Generative Model)等学习方法。2
到了20世纪90年代,对半监督学习的研究变得更加狂热,新的理论的出现,以及自然语言的处理、文本分类和计算机视觉中的新应用的发展,促进了半监督学习的发展,出现了协同训练(Co-Training)和转导支持向量机(Transductive Support Vector Machine,TSVM)等新方法。Merz等人在1992年提出了SSL这个术语,并首次将SSL用于分类问题。接着Shahshahani和Landgrebe展开了对SSL的研究。协同训练方法由Blum和Mitchell提出,基于不同的视图训练出两个不同的学习机,提高了训练样本的置信度。Vapnik和Sterin提出了TSVM,用于估计类标签的线性预测函数。为了求解TSVM,Joachims提出了SVM方法,Bie和Cristianini将TSVM放松为半定规划问题从而进行求解。许多研究学者广泛研究将期望最大算法(Expectation Maximum,EM)与高斯混合模型(Gaussian Mixture Model,GMM)相结合的生成式SSL方法。Blum等人提出了最小割法(Mincut),首次将图论应用于解决SSL问题。Zhu等人提出的调和函数法(Harmonic Function)将预测函数从离散形式扩展到连续形式。由Belkin等人提出的流形正则化法(Manifold Regularization)将流形学习的思想用于SSL场景。Klein等人提出首个用于聚类的半监督距离度量学习方法,学习一种距离度量。
在半监督学习成为一个热门领域之后,出现了许多利用无类标签的样例提高学习算法预测精度和加快速度的学习方法,因此出现了大量改进的半监督学习方法。Nigam等人将EM和朴素贝叶斯结合,通过引入加权系数动态调整无类标签的样例的影响提高了分类准确度,建立每类中具有多个混合部分的模型,使贝叶斯偏差减小。Zhou和Goldman提出了协同训练改进算法,不需要充分冗余的视图,而利用两个不同类型的分类器来完成学习。Shang等人提出一种新的半监督学习方法,能同时解决有类标签样本稀疏和具有附加无类标签样例成对约束的问题。
基本思想半监督学习的基本设置是给定一个来自某未知分布的有标记示例集L={(x1, y1), (x2, y2), ..., (x |L|,y|L|)}以及一个未标记示例集U = {x1’, x2’, ... , x |U|’},期望学得函数f: X→Y可以准确地对示例x 预测其标记y。这里xi, xj’ ∈X 均为d维向量,yi∈Y为示例xi的标记,|L|和|U|分别为L和U的大小,即它们所包含的示例数。3
半监督学习的基本思想是利用数据分布上的模型假设建立学习器对未标签样例进行标签。它的形式化描述是给定一个来自某未知分布的样例集S=LU,其中L是已标签样例集L={(x1,y1),(x2,y2),,,(x|L|,y|L|)},U是一个未标签样例集U={xc1,xc2,,,xc|U|},希望得到函数f:XyY可以准确地对样例x预测其标签y。其中xi,xc1均为d维向量,ytIY为样例xi的标签,|L|和|U|分别为L和U的大小,即所包含的样例数,半监督学习就是在样例集S上寻找最优的学习器。如果S=L,那么问题就转化为传统的有监督学习;反之,如果S=U,那么问题是转化为传统的无监督学习。如何综合利用已标签样例和未标签样例,是半监督学习需要解决的问题。
目前,在半监督学习中有三个常用的基本假设来建立预测样例和学习目标之间的关系,有以下三个:
(1)平滑假设(Smoothness Assumption):位于稠密数据区域的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同。
(2)聚类假设(Cluster Assumption):当两个样例位于同一聚类簇时,它们在很大的概率下有相同的类标签。这个假设的等价定义为低密度分离假设(Low Sensity Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例分到决策边界两侧。
聚类假设是指样本数据间的距离相互比较近时,则他们拥有相同的类别。根据该假设,分类边界就必须尽可能地通过数据较为稀疏的地方,以能够避免把密集的样本数据点分到分类边界的两侧。在这一假设的前提下,学习算法就可以利用大量未标记的样本数据来分析样本空间中样本数据分布情况,从而指导学习算法对分类边界进行调整,使其尽量通过样本数据布局比较稀疏的区域。例如,Joachims提出的转导支持向量机算法,在训练过程中,算法不断修改分类超平面并交换超平面两侧某些未标记的样本数据的标记,使得分类边界在所有训练数据上最大化间隔,从而能够获得一个通过数据相对稀疏的区域,又尽可能正确划分所有有标记的样本数据的分类超平面。
(3)流形假设(Manifold Assumption):将高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。
流形假设的主要思想是同一个局部邻域内的样本数据具有相似的性质,因此其标记也应该是相似。这一假设体现了决策函数的局部平滑性。和聚类假设的主要不同是,聚类假设主要关注的是整体特性,流形假设主要考虑的是模型的局部特性。在该假设下,未标记的样本数据就能够让数据空间变得更加密集,从而有利于更加标准地分析局部区域的特征,也使得决策函数能够比较完满地进行数据拟合。流形假设有时候也可以直接应用于半监督学习算法中。例如,Zhu 等人利用高斯随机场和谐波函数进行半监督学习,首先利用训练样本数据建立一个图,图中每个结点就是代表一个样本,然后根据流形假设定义的决策函数的求得最优值,获得未标记样本数据的最优标记;Zhou 等人利用样本数据间的相似性建立图,然后让样本数据的标记信息不断通过图中的边的邻近样本传播,直到图模型达到全局稳定状态为止。
从本质上说,这三类假设是一致的,只是相互关注的重点不同。其中流行假设更具有普遍性。
半监督学习的分类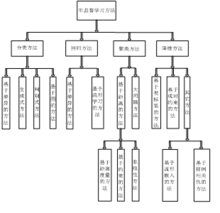 SSL按照统计学习理论的角度包括直推(Transductive)SSL和归纳(Inductive)SSL两类模式。直推SSL只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,预测训练数据中无类标签的样例的类标签;归纳SSL处理整个样本空间中所有给定和未知的样例,同时利用训练数据中有类标签的样本和无类标签的样例,以及未知的测试样例一起进行训练,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签。从不同的学习场景看,SSL可分为四大类:4
SSL按照统计学习理论的角度包括直推(Transductive)SSL和归纳(Inductive)SSL两类模式。直推SSL只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,预测训练数据中无类标签的样例的类标签;归纳SSL处理整个样本空间中所有给定和未知的样例,同时利用训练数据中有类标签的样本和无类标签的样例,以及未知的测试样例一起进行训练,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签。从不同的学习场景看,SSL可分为四大类:4
半监督分类半监督分类(Semi-Supervised Classification):是在无类标签的样例的帮助下训练有类标签的样本,获得比只用有类标签的样本训练得到的分类器性能更优的分类器,弥补有类标签的样本不足的缺陷,其中类标签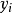 取有限离散值
取有限离散值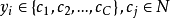 。
。
半监督回归半监督回归(Semi-Supervised Regression):在无输出的输入的帮助下训练有输出的输入,获得比只用有输出的输入训练得到的回归器性能更好的回归器,其中输出 取连续值
取连续值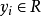 ;
;
半监督聚类半监督聚类(Semi-Supervised Clustering):在有类标签的样本的信息帮助下获得比只用无类标签的样例得到的结果更好的簇,提高聚类方法的精度;
半监督降维半监督降维(Semi-Supervised Dimensionality Reduction):在有类标签的样本的信息帮助下找到高维输入数据的低维结构,同时保持原始高维数据和成对约束(Pair-Wise Constraints)的结构不变,即在高维空间中满足正约束(Must-Link Constraints)的样例在低维空间中相距很近,在高维空间中满足负约束(Cannot-Link Constraints)的样例在低维空间中距离很远。
未来研究方向经过大量研究人员的长期努力,SSL领域的研究已取得了一定发展,提出了不少SSL方法,同时已将SSL应用于许多实际领域。但目前这个领域的研究仍存在许多有待进一步解决的问题,未来的研究方向包括以下一些内容。2
理论分析目前对SSL的理论分析还不够深入。在类标签错误或成对约束不正确时学习方法的性能如何改变,选择不同的正约束和负约束的比例会对降维的性能造成什么影响,除了通常采用的分类精度和运算速度之外,还有没有其他更合适的评价指标,对学习性能起到改进作用的是准确的最优化求解算法,还是使用的学习模型中的数据表示和学习方法,最优解对学习结果的影响有多大,未来还需要进一步探讨这些问题。
抗干扰性与可靠性当前大部分SSL利用的数据是无噪声干扰的数据,而且依赖的基本假设没有充分考虑噪声干扰下无类标签数据分布的不确定性以及复杂性,但是在实际应用中通常难以得到无噪声数据。未来需要研究如何根据实际问题选择合适的SSL方法,更好地利用无类标签的样例帮助提高学习的准确性和快速性,并减小大量无类标签数据引起的计算复杂性,可以考虑引入鲁棒统计理论解决该抗噪声干扰问题。此外,大量实验研究证明当模型假设正时,无类标签的样例能够帮助改进学习性能;而在错误的模型假设上,SSL不仅不会对学习性能起到改进作用,甚至会产生错误,恶化学习性能。如何验证做出的模型假设是否正确,选择哪种SSL方法能够更合适地帮助提高学习性能,除了己有的假设之外,还可以在无类标签的样例上进行哪些假设,新的假设是否会产生新的法,SSL能否有效用于大型的无类标签的数据,这些问题还有待未来研究.此外,导致SSL性能下降的原因除了模型假设不符合实际情况外,还有学习过程中标记无类标签的样例累积的噪声,是否还有其他原因使无类标签的样例造成学习能力的下降,也是未来需要进一步研究的问题。
训练样例与参数的选取通常训练数据是随机选取的,即有类标签的样例和无类标签的样例独立同分布,但是在实际应用中,无类标签的样例可能来自与有类标签的样例分布不同或未知的场景,并且有可能带有噪声。未来的研究需要找到一个好的方法将SSL和主动学习相结合,选取有利于学习模型的训练样例,并确定SSL,能够有效进行所需要的有类标签的样本数量的下界。此外,许多研究人员将SL和UL二算法扩展用于SSL,但是许多这些算法是根据先验信息得到训练数据集的参数,并利用这些参数改进算法在SSL中的性能.目前都是人工选取一种SSL方法,并设定学习数,保证SSL的性能优于SL和UL,但是当选取的SSL方法与学习任务不匹配或者参数的设定不合适时,会成SSL的性能比SL或UL更差.如何自动根据学习任务选取合适的SSL方法并准确得到参数是未来SSL需要深入研究的内容,可以考虑用全贝叶斯学习理论解决。
优化求解从各种SSL算法的实现过程可以看出,SSL问题大多为非凸、非平滑问题,或整数规划和组合优化问题,存在多个局部最优解,例如求解SSL产生式方法目标函数的EM算法只能得到局部极大值目前主要采用各种放松方法把目标函数近似转化为凸或连续最优化问题,不易得到全局最优解,算法的时空复杂性很高,问题的求解依赖于最优化理论的突破,未来需要研究新的算法求解全局最优解。
研究拓展SSL从产生以来,主要用于实验室中处理人工合成数据,未来的研究一方而需要讨论SSL可以显著提高哪些学习任务的性能,拓展SSL在现实领域的实际应用,另一方而需要制定出一个统一的令人信服的SSL方法的使用规程。此外,目前有许多的半监督分类方法,而对半监督回归问题的研究比较有限。未来有待继续研究半监督分类和半监督回归之间的关系,并提出其他半监督回归方法。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国