

四要素
一般而言,特征选择可以看作一个搜索寻优问题。对大小为n 的特征集合, 搜索空间由2n-1 种可能的状态构成。Davies 等证明最小特征子集的搜索是一个NP 问题,即除了穷举式搜索,不能保证找到最优解。但实际应用中,当特征数目较多的时候, 穷举式搜索因为计算量太大而无法应用,因此人们致力于用启发式搜索算法寻找次优解。一般特征选择算法必须确定以下4 个要素:1)搜索起点和方向;2)搜索策略;3)特征评估函数;4)停止准则。2
搜索起点和方向搜索起点是算法开始搜索的状态点,搜索方向是指评价的特征子集产生的次序。搜索的起点和搜索方向是相关的,它们共同决定搜索策略。一般的,根据不同的搜索起点和方向,有以下4 种情况:
1)前向搜索搜索起点是空集S,依据某种评价标准,随着搜索的进行,从未被包含在S 里的特征集中选择最佳的特征不断加入S。
2)后向搜索搜索起点是全集S,依据某种评价标准不断从S 中剔除最不重要的特征,直到达到某种停止标准。
3)双向搜索双向搜索同时从前后两个方向开始搜索。一般搜索到特征子集空间的中部时,需要评价的子集将会急剧增加。当使用单向搜索时,如果搜索要通过子集空间的中部就会消耗掉大量的搜索时间,所以双向搜索是比较常用的搜索方法。2
4)随机搜索随机搜索从任意的起点开始,对特征的增加和删除也有一定的随机性。
搜索策略假设原始特征集中有n 个特征(也称输入变量),那么存在2n-1 个可能的非空特征子集。搜索策略就是为了从包含
2n-1 个候选解的搜索空间中寻找最优特征子集而采取的搜索方法。搜索策略可大致分为以下3 类:
1)穷举式搜索它可以搜索到每个特征子集。缺点是它会带来巨大的计算开销,尤其当特征数较大时,计算时间很长。分支定界法(Branch and Bound, BB)通过剪枝处理缩短搜索时间。2
2)序列搜索它避免了简单的穷举式搜索,在搜索过程中依据某种次序不断向当前特征子集中添加或剔除特征,从而获得优化特征子集。比较典型的序列搜索算法如:前向后向搜索、浮动搜索、双向搜索、序列向前和序列向后算法等。序列搜索算法较容易实现,计算复杂度相对较小,但容易陷入局部最优。
3)随机搜索由随机产生的某个候选特征子集开始,依照一定的启发式信息和规则逐步逼近全局最优解。例如:遗传算法(Genetic Algorithm, GA)、模拟退火算法(SimulatedAnnealing, SA)、粒子群算法(Particl Swarm Optimization,PSO)和免疫算法(Immune Algorithm, IA)等。2
特征评估函数评价标准在特征选择过程中扮演着重要的角色,它是特征选择的依据。评价标准可以分为两种:一种是用于单独地衡量每个特征的预测能力的评价标准;另一种是用于评价某个特征子集整体预测性能的评价标准。
在Filte方法中,一般不依赖具体的学习算法来评价特征子集,而是借鉴统计学、信息论等多门学科的思想,根据数据集的内在特性来评价每个特征的预测能力,从而找出排序较优的若干个特征组成特征子集。通常,此类方法认为最优特征子集是由若干个预测能力较强的特征组成的。相反,在Wrapper 方法中,用后续的学习算法嵌入到特征选择过程中,通过测试特征子集在此算法上的预测性能来决定它的优劣,而极少关注特征子集中每个特征的预测性能如何。因此,第二种评价标准并不要求最优特征子集中的每个特征都是优秀的。2
停止准则停止标准决定什么时候停止搜索, 即结束算法的执行。它与评价准则或搜索算法的选择以及具体应用需求均有关联。常见的停止准则一般有:
1)执行时间即事先规定了算法执行的时间,当到达所制定的时间就强制终止算法运行,并输出结果。
2)评价次数即制定算法需要运算多少次,通常用于规定随机搜索的次数, 尤其当算法运行的结果不稳定的情况下,通过若干次的运行结果找出其中稳定的因素。
3) 设置阈值一般是给算法的目标值设置一个评价阈值,通过目标与该阈值的比较决定算法停止与否。不过,要设置一个合适的阈值并不容易,需要对算法的性能有十分清晰的了解。否则,设置阈值过高会使得算法陷入死循环,阈值过小则达不到预定的性能指标。2
基本框架迄今为止, 已有很多学者从不同角度对特征选择进行过定义: Kira 等人定义理想情况下特征选择是寻找必要的、足以识别目标的最小特征子集; John 等人从提高预测精度的角度定义特征选择是一个能够增加分类精度, 或者在不降低分类精度的条件下降低特征维数的过程; Koller 等人从分布的角度定义特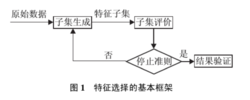 征选择为: 在保证结果类分布尽可能与原始数据类分布相似的条件下, 选择尽可能小的特征子集;Dash 等人给出的定义是选择尽量小的特征子集, 并满足不显著降低分类精度和不显著改变类分布两个条件. 上述各种定义的出发点不同, 各有侧重点, 但是目标都是寻找一个能够有效识别目标的最小特征子集. 由文献可知, 对特征选择的定义基本都是从分类正确率以及类分布的角度考虑. Dash 等人给出了特征选择的基本框架, 如图1 所示.3
征选择为: 在保证结果类分布尽可能与原始数据类分布相似的条件下, 选择尽可能小的特征子集;Dash 等人给出的定义是选择尽量小的特征子集, 并满足不显著降低分类精度和不显著改变类分布两个条件. 上述各种定义的出发点不同, 各有侧重点, 但是目标都是寻找一个能够有效识别目标的最小特征子集. 由文献可知, 对特征选择的定义基本都是从分类正确率以及类分布的角度考虑. Dash 等人给出了特征选择的基本框架, 如图1 所示.3
由于子集搜索是一个比较费时的步骤, Yu 等人基于相关和冗余分析, 给出了另一种特征选择框架, 避免了子集搜索, 可以高效快速地寻找最优子集.框架如图2 所示.3
从特征选择的基本框架可以看出, 特征选择方法中有4 个基本步骤: 候选特征子集的生成(搜索策略)、评价准则、停止准则和验证方法. 目前对特征选择方法的研究主要集中于搜索策略和评价准则, 因而, 一般从搜索策略和评价准则两个角度对特征选择方法进行分类.3
特征选择的一般过程**(1)产生过程( Generation Procedure )**
产生过程是搜索特征子集的过程,负责为评价函数提供特征子集。
(2)评价函数( Evaluation Function )
评价函数是评价一个特征子集好坏程度的一个准则。
(3)停止准则( Stopping Criterion )
停止准则是与评价函数相关的,一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索。
(4)验证过程( Validation Procedure )
在验证数据集上验证选出来的特征子集的有效性。
基于搜索策略的方法分类基本的搜索策略按照特征子集的形成过程可分为以下3 种: 全局最优、随机搜索和启发式搜索. 一个具体的搜索算法会采用两种或多种基本搜索策略,例如遗传算法是一种随机搜索算法, 同时也是一种启发式搜索算法. 下面对3 种基本的搜索策略进行分析比较.
1、采用全局最优搜索策略的特征选择方法
迄今为止, 唯一得到最优结果的搜索方法是分支定界法. 这种算法能保证在事先确定优化特征子集中特征数目的情况下, 找到相对于所设计的可分性判据而言的最优子集. 它的搜索空间是O(2N) (其中N 为特征的维数). 存在的问题: 很难确定优化特征子集的数目; 满足单调性的可分性判据难以设计; 处理高维多类问题时, 算法的时间复杂度较高. 因此, 虽然全局最优搜索策略能得到最优解, 但因为诸多因素限制, 无法被广泛应用.3
2、采用随机搜索策略的特征选择方法
在计算过程中把特征选择问题与模拟退火算法、禁忌搜索算法、遗传算法等, 或者仅仅是一个随机重采样过程结合起来, 以概率推理和采样过程作为算法的基础, 基于对分类估计的有效性, 在算法运行中对每个特征赋予一定的权重; 然后根据用户所定义的或自适应的阈值来对特征重要性进行评价. 当特征所对应的权重超出了这个阈值, 它便被选中作为重要的特征来训练分类器. Relief 系列算法即是一种典型的根据权重选择特征的随机搜索方法, 它能有效地去掉无关特征, 但不能去除冗余, 而且只能用于两类分类. 随机方法可以细分为完全随机方法和概率随机方法两种. 虽然搜索空间仍为O(2N), 但是可以通过设置最大迭代次数限制搜索空间小于O(2N). 例如遗传算法, 由于采用了启发式搜索策略, 它的搜索空间远远小于O(2N).存在的问题: 具有较高的不确定性, 只有当总循环次数较大时, 才可能找到较好的结果. 在随机搜索策略中, 可能需对一些参数进行设置, 参数选择的合适与否对最终结果的好坏起着很大的作用. 因此, 参数选择是一个关键步骤.3
3、采用启发式搜索策略的特征选择方法
这类特征选择方法主要有: 单独最优特征组合,序列前向选择方法(SFS), 广义序列前向选择方法(GSFS), 序列后向选择方法(SBS), 广义序列后向选择方法(GSBS), 增l去r 选择方法, 广义增l去r选择方法, 浮动搜索方法. 这类方法易于实现且快速, 它的搜索空间是O(N2). 一般认为采用浮动广义后向选择方法(FGSBS) 是较为有利于实际应用的一种特征选择搜索策略, 它既考虑到特征之间的统计相关性, 又用浮动方法保证算法运行的快速稳定性. 存在的问题是: 启发式搜索策略虽然效率高, 但是它以牺牲全局最优为代价.3
每种搜索策略都有各自的优缺点, 在实际应用过程中, 可以根据具体环境和准则函数来寻找一个最佳的平衡点. 例如, 如果特征数较少, 可采用全局最优搜索策略; 若不要求全局最优, 但要求计算速度快, 则可采用启发式策略; 若需要高性能的子集, 而不介意计算时间, 则可采用随机搜索策略.3
基于评价准则划分特征选择方法特征选择方法依据是否独立于后续的学习算法, 可分为过滤式(Filter) 和封装式(Wrapper)两种.Filter 与后续学习算法无关, 一般直接利用所有训练数据的统计性能评估特征, 速度快, 但评估与后续学习算法的性能偏差较大. Wrapper 利用后续学习算法的训练准确率评估特征子集, 偏差小, 计算量大, 不适合大数据集. 下面分别对Filter 和Wrapper 方法进行分析.3
1、过滤式(Filter) 评价策略的特征选择方法
Filter 特征选择方法一般使用评价准则来增强特征与类的相关性, 削减特征之间的相关性. 可将评价函数分成4 类: 距离度量、信息度量、依赖性度量以及一致性度量.
2、封装式(Wrapper) 评价策略的特征选择方法
除了上述4 种准则, 分类错误率也是一种衡量所选特征子集优劣的度量标准. Wrapper 模型将特征选择算法作为学习算法的一个组成部分, 并且直接使用分类性能作为特征重要性程度的评价标准. 它的依据是选择子集最终被用于构造分类模型. 因此, 若在构造分类模型时, 直接采用那些能取得较高分类性能的特征即可, 从而获得一个分类性能较高的分类模型. 该方法在速度上要比Filter 方法慢, 但是它所选择的优化特征子集的规模相对要小得多, 非常有利于关键特征的辨识; 同时它的准确率比较高, 但泛化能力比较差, 时间复杂度较高. 目前此类方法是特征选择研究领域的热点, 相关文献也很多. 例如, Hsu 等人用决策树来进行特征选择, 采用遗传算法来寻找使得决策树分类错误率最小的一组特征子集. Chiang等人将Fisher 判别分析与遗传算法相结合, 用来在化工故障过程中辨识关键变量, 取得了不错的效果.Guyon 等人使用支持向量机的分类性能衡量特征的重要性程度, 并最终构造一个分类性能较高的分类器. Krzysztof提出了一种基于相互关系的双重策略的Wrapper 特征选择方法. 叶吉祥等人提出了一种快速的Wrapper 特征选择方法FFSR(fast featuresubset ranking), 以特征子集作为评价单位, 以子集收敛能力作为评价标准. 戴平等人利用SVM线性核与多项式核函数的特性, 结合二进制PSO 方法, 提出了一种基于SVM的快速特征选择方法.3
综上所述, Filter 和Wrapper 特征选择方法各有优缺点. 将启发式搜索策略和分类器性能评价准则相结合来评价所选的特征, 相对于使用随机搜索策略的方法, 节约了不少时间. Filter 和Wrapper 是两种互补的模式, 两者可以结合. 混合特征选择过程一般由两个阶段组成, 首先使用Filter 方法初步剔除大部分无关或噪声特征, 只保留少量特征, 从而有效地减小后续搜索过程的规模. 第2 阶段将剩余的特征连同样本数据作为输入参数传递给Wrapper 选择方法,以进一步优化选择重要的特征. 例如,有 文献]采用混合模型选择特征子集, 先使用互信息度量标准和bootstrap 技术获取前k个重要的特征, 然后再使用支持向量机构造分类器.3
研究进展及展望自从上世纪90 年代以来, 特征选择得到广泛研究并应用于Web 文档处理(文本分类、文本检索、文本恢复等)、基因分析、药物诊断等领域。现在的社会是信息爆炸的社会, 越来越多、形式多样的数据出现在我们面前, 比如基因数据、数据流, 如何设计出更好的特征选择算法来满足社会的需求, 是一个长期的任务, 特征选择算法的研究在未来的一段时间仍将是机器学习等领域的研究热点问题之一。目前研究热点及趋势主要集中于以下方面:
1) 特征与样本选择的组合研究。不同的样本集合区域, 也许应该选择不同的特征选择算法。很多数据中存在特征天然分割的特性, 如在网页半监督分类问题中, 描述网页特征集( 一般为词汇集) 通常可以分割为如下独立的两个特征子集: 出现在网页文本内容中的词汇集合和出现在网页的超级链接中的词汇集合, 那么对于这两个特征子集, 我们能不能使用不同的特征选择方法来降低维数、取得更好的学习效果呢?4
2)最近, 特征及其与目标(分类、回归、聚类等)的相关性受到越来越多的重视, 可以称此问题为全相关间题。如在基因表达式分析中,找出所有特征中那些和目标变量相关的特征, 这些特征可能导致生物状态为健康或有疾病, 目前常用的是Ranking方法, 但Ranking方法往往考虑的是特征和标签的相关性, 没有考虑特征间的关联,如何将特征之间的关联性考虑进去呢? 这也是目前研究的重点和难点之一。4


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国