

背景简介
互联网的出现和普及给用户带来了大量的信息,满足了用户在信息时代对信息的需求,但随着网络的迅速发展而带来的网上信息量的大幅增长,使得用户在面对大量信息时无法从中获得对自己真正有用的那部分信息,对信息的使用效率反而降低了,这就是所谓的2信息超载(informationoverload)问题。
解决信息超载问题一个非常有潜力的办法是3推荐系统,它是根据用户的信息需求、兴趣等,将用户感兴趣的信息、产品等推荐给用户的个性化信息推荐系统。和搜索引擎相比推荐系统通过研究用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点,从而引导用户发现自己的信息需求。一个好的推荐系统不仅能为用户提供个性化的服务,还能和用户之间建立密切关系,让用户对推荐产生依赖。
推荐系统现已广泛应用于很多领域,其中最典型并具有良好的发展和应用前景的领域就是电子商务领域。同时学术界对推荐系统的研究热度一直很高,逐步形成了一门独立的学科。
定义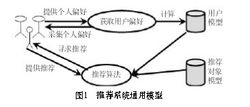 推荐系统有3个重要的模块:用户建模模块、推荐对象建模模****块、推荐算法模块。通用的推荐系统模型流程如图。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。
推荐系统有3个重要的模块:用户建模模块、推荐对象建模模****块、推荐算法模块。通用的推荐系统模型流程如图。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。
发展历程1995年3月,卡耐基.梅隆大学的RobertArmstrong等人在美国人工智能协会上提出了个性化导航系统Web Watcher;斯坦福大学的MarkoBalabanovic等人在同一会议上推出了个性化推荐系统LIRA;
1995年8月,麻省理工学院的Henry Lieberman在国际人工智能联合大会(IJCAI)上提出了个性化导航智能体Letizia;
1996年, Yahoo 推出了个性化入口My Yahoo;
1997年,AT&T实验室提出了基于协作过滤的个性化推荐系统PHOAKS和Referral Web;
1999年,德国Dresden技术大学的Tanja Joerding实现了个性化电子商务原型系统TELLIM;
2000年,NEC研究院的Kurt等人为搜索引擎CiteSeer增加了个性化推荐功能;
2001年,纽约大学的Gediminas Adoavicius和Alexander Tuzhilin实现了个性化电子商务网站的用户建模系统1:1Pro;
2001年,IBM公司在其电子商务平台Websphere中增加了个性化功能,以便商家开发个性化电子商务网站。
2003年,Google开创了AdWords盈利模式,通过用户搜索的关键词来提供相关的广告。AdWords的点击率很高,是Google广告收入的主要来源。2007年3月开始,Google为AdWords添加了个性化元素。不仅仅关注单次搜索的关键词,而是对用户一段时间内的搜索历史进行记录和分析,据此了解用户的喜好和需求,更为精确地呈现相关的广告内容。
2007年,雅虎推出了SmartAds广告方案。雅虎掌握了海量的用户信息,如用户的性别、年龄、收入水平、地理位置以及生活方式等,再加上对用户搜索、浏览行为的记录,使得雅虎可以为用户呈现个性化的横幅广告。
2009年,Overstock(美国著名的网上零售商)开始运用ChoiceStream公司制作的个性化横幅广告方案,在一些高流量的网站上投放产品广告。 Overstock在运行这项个性化横幅广告的初期就取得了惊人的成果,公司称:“广告的点击率是以前的两倍,伴随而来的销售增长也高达20%至30%。”
2009年7月,国内首个推荐系统科研团队北京百分点信息科技有限公司成立,该团队专注于推荐引擎技术与解决方案,在其推荐引擎技术与数据平台上汇集了国内外百余家知名电子商务网站与资讯类网站,并通过这些B2C网站每天为数以千万计的消费者提供实时智能的商品推荐。
2011年9月,百度世界大会2011上,李彦宏将推荐引擎与云计算、搜索引擎并列为未来互联网重要战略规划以及发展方向。百度新首页将逐步实现个性化,智能地推荐出用户喜欢的网站和经常使用的APP。
主要推荐方法基于内容推荐基于内容的推荐(Content-based Recommendation)是4信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。 基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。
基于内容推荐方法的优点是:
1)不需要其它用户的数据,没有冷开始问题和稀疏问题。
2)能为具有特殊兴趣爱好的用户进行推荐。
3)能推荐新的或不是很流行的项目,没有新项目问题。
4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。
5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。
缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。
协同过滤推荐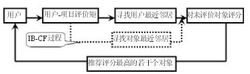 协同过滤推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优 点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
协同过滤推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优 点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
 协同过滤是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用 户。其基本思想非常易于理解,在日常生活中,我们往往会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到电子商务推荐系统中来,基于其他用 户对某一内容的评价来向目标用户进行推荐。
协同过滤是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用 户。其基本思想非常易于理解,在日常生活中,我们往往会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到电子商务推荐系统中来,基于其他用 户对某一内容的评价来向目标用户进行推荐。
基于协同过滤的推荐系统可以说是从用户的角度来进行相应推荐的,而且是自动的即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的,不需要用户努力地找到适合自己兴趣的推荐信息,如填写一些调查表格等。
和基于内容的过滤方法相比,协同过滤具有如下的优点:
1) 能够过滤难以进行机器自动内容分析的信息,如艺术品,音乐等。
2) 共享其他人的经验,避免了内容分析的不完全和不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤。
3) 有推荐新信息的能力。可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的。这也是协同过滤和基于内容的过滤一个较大的差别,基于内容的过滤推荐很多都是用户本来就熟悉的内容,而协同过滤可以发现用户潜在的但自己尚未发现的兴趣偏好。
4) 能够有效的使用其他相似用户的反馈信息,较少用户的反馈量,加快个性化学习的速度。
虽然协同过滤作为一种典型的推荐技术有其相当的应用,但协同过滤仍有许多的问题需要解决。最典型的问题有稀疏问题(Sparsity)和可扩展问题(Scalability)。
基于关联规则推荐基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零 售业中已经得到了成功的应用。管理规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集Y,其直观的意义就是用户在购 买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会同时购买面包。
算法的第一步关联规则的发现最为关键且最耗时,是算法的瓶颈,但可以离线进行。其次,商品名称的同义性问题也是关联规则的一个难点。
基于效用推荐基于效用的推荐(Utility-based Recommendation)是建立在对用户使用项目的效用情况上计算的,其核心问题是怎么样为每一个用户去创建一个效用函数,因此,用户资料模型很大 程度上是由系统所采用的效用函数决定的。基于效用推荐的好处是它能把非产品的属性,如提供商的可靠性(Vendor Reliability)和产品的可得性(Product Availability)等考虑到效用计算中。
基于知识推荐基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因 它们所用的功能知识不同而有明显区别。效用知识(Functional Knowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以 是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
组合推荐由于各种推荐方法都有优缺点,所以在实际中,组合推荐(Hybrid Recommendation)经常被采用。研究和应用最多的是内容推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法 去产生一个推荐预测结果,然后用某方法组合其结果。尽管从理论上有很多种推荐组合方法,但在某一具体问题中并不见得都有效,组合推荐一个最重要原则就是通 过组合后要能避免或弥补各自推荐技术的弱点。
在组合方式上,有研究人员提出了七种组合思路:
1)加权(Weight):加权多种推荐技术结果。
2)变换(Switch):根据问题背景和实际情况或要求决定变换采用不同的推荐技术。
3)混合(Mixed):同时采用多种推荐技术给出多种推荐结果为用户提供参考。
4)特征组合(Feature combination):组合来自不同推荐数据源的特征被另一种推荐算法所采用。
5)层叠(Cascade):先用一种推荐技术产生一种粗糙的推荐结果,第二种推荐技术在此推荐结果的基础上进一步作出更精确的推荐。
6)特征扩充(Feature augmentation):一种技术产生附加的特征信息嵌入到另一种推荐技术的特征输入中。
7)元级别(Meta-level):用一种推荐方法产生的模型作为另一种推荐方法的输入。
体系结构服务器端推荐系统推荐系统的体系结构研究的重要问题就是用户信息收集和用户描述文件放在什么地方,服务器还是客户机上,或者是处于二者之间的代理服务器上。
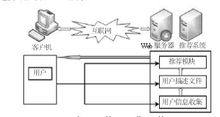 最初的推荐系统都是基于服务器端的推荐系统,基本结构如图。在这类推荐系统中,推荐系统与Web服务器一般共享一台硬件设备。在逻辑上,推荐系统要的用户信息收集和建模都依赖于Web服务器。
最初的推荐系统都是基于服务器端的推荐系统,基本结构如图。在这类推荐系统中,推荐系统与Web服务器一般共享一台硬件设备。在逻辑上,推荐系统要的用户信息收集和建模都依赖于Web服务器。
由此可知,基于服务器端的推荐系统存在的问题主要包括:
(1)个性化信息的收集完全由Web服务器来完成,受到了Web服务器功能的限制。
(2)增加了Web服务器的系统开销。
(3)对用户的隐私有极大威胁。无论是推荐系统的管理者还是入侵推荐系统的人员都能方便地获取存放在服务器上的用户数据。由于用户的个人数据是有很高价值的,接触到用户数据的部分人会出卖用户数据或把用户数据用于非法用途。
客户端推荐系统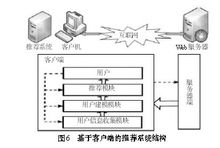 典型的客户端个性化服务系统有斯坦福大学的LIRA、麻省理工学院的Letizia、加州大学的Syskill&Webert、卡内基·梅隆大学的PersonalWeb-Watcher等。
典型的客户端个性化服务系统有斯坦福大学的LIRA、麻省理工学院的Letizia、加州大学的Syskill&Webert、卡内基·梅隆大学的PersonalWeb-Watcher等。
基于客户端的推荐系统有如下优点:
(1)由于用户的信息就在本地收集和处理,因而不但能够获取丰富准确的用户信息以构建高质量的用户模型。
(2)少量甚至没有用户数据存放在服务器上,Web服务器不能访问和控制用户的数据,能比较好地保护用户的隐私。
(3)用户更愿意向推荐系统提供个人信息,从而提高推荐系统的推荐性能。因为基于客户端的推荐系统中的用户数据存储在用户本地客户机上,用户对数据能够进行自行控制。
基于客户端的推荐系统有一定缺点:
(1)用户描述文件的形成、推荐策略的应用都依赖于所有用户数据分析的基础上进行的,而基于客户端的推荐系统较难获取其他用户的数据,用户描述文件较难得到,协同推荐策略实施也较难,所以推荐系统要重新设计,尤其是推荐策略必须进行修改。
(2)个性化推荐处理过程中用户的数据资料还需要部分的传给服务器,存在隐私泄漏的危险,需要开发安全传输平台进行数据传输。
知名团队明尼苏达大学GroupLens(John Riedl, Joseph A.Konstan)
密西根大学(Paul Resnick)
卡内基梅隆大学(JaimeCallan)
微软研究院(Ryen W.White)
纽约大学(Alexander Tuzhilin)
百分点科技团队(Baifendian)

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国