

今年下半年,生成式 AI 作画突然爆火,许多人都对这种“以文生图”的 AI 作画感到好奇,并且进行了自己的尝试。在 AI 的帮助下,不乏一些让人惊叹的美术作品出现,比如今年 8 月,美国游戏设计师 Jason Allen 就凭借一幅 AI 绘画作品《太空歌剧院(Théâtre D'opéra Spatial)》,获得了美国科罗拉多州博览会美术竞赛一等奖。
《太空歌剧院(Théâtre D’opéra Spatial)》,作者:Jason M. Allen在欣赏 AI 作品的同时,我们也不能忽略人工智能在作画时产生的问题。01
作品质量参差不齐
首先就是作品质量问题。像刚才提到的获得一等奖的《太空歌剧院》,其实也是被设计师进行了多次修改,花费了近 80 个小时后才得到的作品。在一些情况下,如果没有人为的后续修改,那么 AI 绘画的作品可能会“惨不忍睹”。这是因为尽管人工智能作品充满了冲击力和视觉张力,但和几乎所有其他的深度学习模型一样,在理解知识、推理、逻辑方面做得都不够好。例如“画一张世界上最大的猫科动物的图片”,甚至是“一只狗坐在一只猫的左边”,都不会产生符合逻辑或常识的图片。在生成偏写实风格的人类图片的时候,有时候会因为微小的偏差产生“恐怖谷效应”,让人感到不适。另一个已经被广泛注意到的问题,是人工智能经常会生成奇形怪状的手。

图片来源:用户在社交网络上分享的图片这种现象的原因很可能是手部是人类身体上形状最丰富的结构之一——人的一只手有超过 20 个关节(相较而言,脸上只有 1 个关节)。
手部有丰富的姿势,图库版权图片,不授权转载而且在大部分用来训练的图片中,手部经常不是最核心的部位,所以角度不同、距离不同、手势不同、还会被阴影和其他物体遮挡。甚至还有些更加奇特的“手”,它们的手的形状和手指数都不相同,但也都会被标注成“手”,让模型觉得它们的形状——以及它们形状的平均形态,可能都是合理的,也就因此产生了各种崎岖的手。
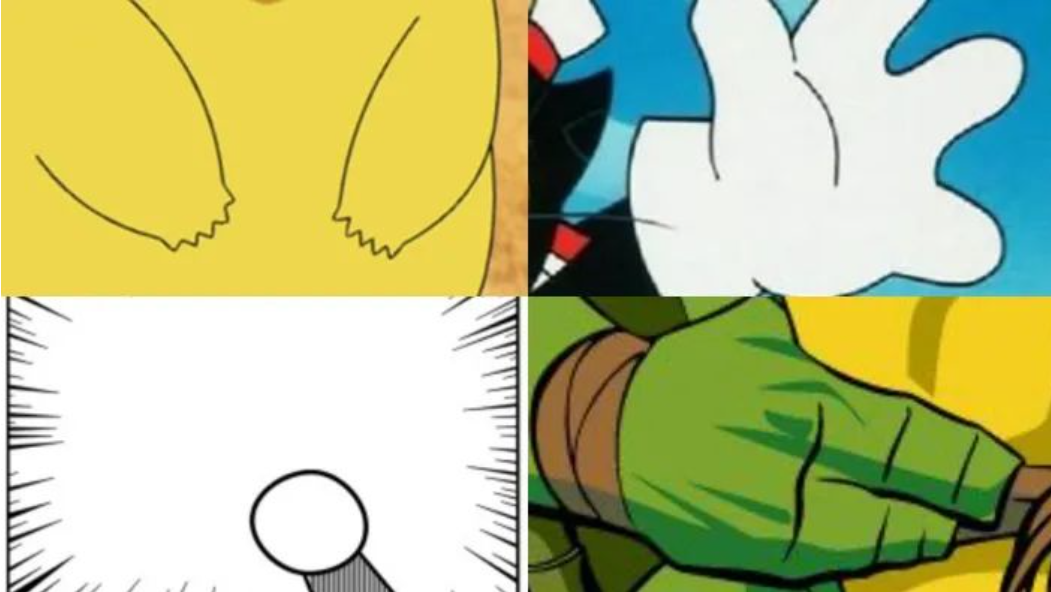
甚至这些也可以被标注为“手”,图片来源:《精灵宝可梦》《黑猫警长》《机器猫》和《忍者神龟》的动画介绍截图。另一个有趣的例子是,一家公司的团队照片几乎都是通过人工智能技术生成的。如果仔细看的话,还是能发现一些线索。例如,第一排左起第二个人只带了一个耳环,第二排左起第二个人的耳朵轮廓不太正常。
图片来源:Business Insider 截取了这家公司的网页截图。可以看到,和开头的获奖作品不同,AI 作画在写实风格上还是存在不少问题的,但这并不妨碍人们对 AI 作画的尝试和使用,同时还在帮助设计者们对 AI 不断优化。毕竟让机器有创造力一直是人工智能的最高理想之一,所以生成任务就成了衡量机器创造力的标准。02
AI 也会产生偏见和刻板印象
除了质量问题外,人工智能生成的内容还有可能产生各种伦理问题。比如在语言模型上时常会出现的偏见和刻板印象,在图片生成中也有体现,例如生成“大公司 CEO”大概率会出现一个白人成熟男性的形象。更大的担忧在于大量虚假内容很可能会操纵公众注意力和观点。每一次修改或生成内容的新技术出现,都会引发这样的担忧。技术的进步让生成虚假内容的门槛变得越来越低,人们认为,AI 技术有可能会让虚假信息空前繁荣,因此伤害社会。除了推动立法外,开发便捷的生成检测技术也是必要的。03
AI 生成的历史
除了最近非常受欢迎的图片生成,AI 创作还包括文字(问答、对话、诗歌、小说)和视频生成,只不过,AI 在创造上还需要更多的训练和学习。第一个能保证质量水准的 AI 创造模型是对抗生成网络(Generative Adversarial Network,下简称:GAN),它包括了一个生成器(G)和一个对抗(分类)器(A)。生成器需要不断训练自己,得到逼真的图片,骗过分类器;而分类器则要尽量将生成的图片和真实的图片区分开来。GAN 的作者伊恩·古德费洛(Ian Goodfellow)在原始论文里用一个假想的警察和假钞犯来举例子:警察不停地使用越来越强的验钞机,逼迫假钞犯露出马脚,但随着验钞机的能力越来越强,假钞机的模仿能力也变得更强。
最早的 GAN 放在今天看,效果其实并不好。图片来源:伊恩·古德费洛等人于 2014 年发表的论文《对抗生成网络(Generative Adversarial Nets)》最早的 GAN 其实效果一般,但随后各种 GAN 的变体开始像雨后春笋一样涌现出来。其中,相当有名的是 StyleGAN,它能生成极为逼真的人脸。这些人脸和任何已有的人脸都不相同,是由计算机全新创作出的面孔。 StyleGAN 生成的高清人脸。值得注意的是,这些人脸并非从真人照片中修改而来,而是模型从零开始生成的全新人脸。图片来源:Tero Karras 等人于 2019 年发表的论文《一种基于风格的生成对抗网络生成器架构(A Style-Based Generator Architecture for Generative Adversarial Networks)》。作为图片生成模型,GAN 仍然有很多缺点。例如,不同的场景需要训练不同的 GAN 模型,但需求的种类是无限的,有些场景也会非常复杂。所以,GAN 只能理解专门用于某个场景的训练图片数据,而无法理解人类的语言,因此不能通过文字控制图片的生成。04
StyleGAN 生成的高清人脸。值得注意的是,这些人脸并非从真人照片中修改而来,而是模型从零开始生成的全新人脸。图片来源:Tero Karras 等人于 2019 年发表的论文《一种基于风格的生成对抗网络生成器架构(A Style-Based Generator Architecture for Generative Adversarial Networks)》。作为图片生成模型,GAN 仍然有很多缺点。例如,不同的场景需要训练不同的 GAN 模型,但需求的种类是无限的,有些场景也会非常复杂。所以,GAN 只能理解专门用于某个场景的训练图片数据,而无法理解人类的语言,因此不能通过文字控制图片的生成。04
风格逐渐丰富的 AI 创作
新的模型很大程度上解决了这一问题。2021 年 1 月,美国研究机构OPEN AI 发布了 DALL·E,OPEN AI 随后又在 2022 年 4 月公布了 DALL·E 2。和 GAN 相比,DALL·E 是预先训练好的大模型,也有理解人类语言的能力,所以只需要用户输入一段文字,就能直接生成对应的图片,不再需要每次都根据对应数据集重新训练。因为不再需要训练模型的专业知识,直接输入文字就能生成效果惊人的图片,DALL·E 2 在国外的社交网络上引起了巨大轰动。大家纷纷尝试用各种各样奇怪的文字输入模型,再把生成的图片公布出来,一度形成了网络迷因。很快,大家发现,DALL·E 2 不仅能准确地生成各种实体,比如动物、植物、建筑、人,还能按照要求改变绘画风格,从写实照片到数字艺术,从油画到简笔画,从梵高到安迪霍尔,从中国国画到日本浮世绘,从毛线织物到橡皮泥风格。只需要在输入文字中加入一两个描绘风格的词,DALL·E 2 就能自动生成符合这种风格的图片。 图片来源:DALL·E 2官网
图片来源:DALL·E 2官网
图片来源:DALL·E 2官网
图片来源:用户在社交网络上分享的图片更令人惊讶的是,DALL·E 对语言的内涵经常有非常准确的理解,因此在面对一些完全虚构的场景时,也能生成带有复杂逻辑的惊人图片。例如:
图片来源:用户在社交网络上分享的图片
图片来源:用户在社交网络上分享的图片
除了 OpenAI,谷歌也随后推出了自己的模型 Disco Diffusion。在技术原理上它和 DALL·E 很类似,但允许艺术家在输入主题文字外,还能控制一些图片参数。
图片来源:用户在社交网络上分享的图片
图片来源:用户在社交网络上分享的图片虽然这些模型都很强大,但却不能理解中文,也难以生成有中国特色的图片,例如国画。因此,很多中国的机构也在训练有创作能力的模型。百度于 2022 年 8 月发布了文心一格,不仅可以接受中文输入,还能生成中国国画或带有古诗词意境的图片。
在百度文心一格上生成的“江南水乡”05
AI 创作的版权问题
最后,人工智能模型生成的作品也面临版权争议。美国版权局多次判决,拥有版权的只有可能是自然人,不能是程序或者机器。另外,有很多人工智能团队在没有征求原作者同意的情况下就用他们的作品用预训练模型,这也引起了广泛的争议。目前,已经有程序员群体在起诉微软的 Github 和 Open AI,因为他们认为这两个机构使用他们的代码训练自动写程序的模型。不过,因为人工智能的创作模型仍是一个非常新的产品,所以各方的边界都没有被法律明确界定,可能还需要更多的案例才能逐渐明晰。作者|管心宇
审核|马珂 阿里云 人工智能计算机视觉 高级工程师
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国