

薛定谔的小板凳与深度学习的后浪
除了《薛定谔的滚》,《薛定谔的佛》,《薛定谔的爱情》之外,薛定谔小板凳的励志故事在坊间也广为流传:话说薛定谔小的时候,老师布置回家做小板凳的手工作业。第二天老师看到薛定谔的粗糙小板凳说:“我想世界上不会有比这更差的凳子了”,薛定谔却从书桌下拿出两个更为粗糙的小板凳说:“有,这是我第一次和第二次做的,而刚交上去的是第三次做的”。
什么,你记得是爱因斯坦的小板凳?确定?爱因斯坦不是用相对论证明勾股定理来着吗?他哪里会有时间做小板凳?!好吧,你是对的,enjoy。这个小板凳的故事,是一个伟大物理学家自我激励的故事,也是薛定谔的千千万万的后浪们被激励的故事。作者就是沐浴着这样的励志故事长大的,自我激励着,也被一波一波的前浪们引领着,裹挟到大数据人工智能这个江湖的。
激励的是需求
薛定谔的成长多大程度上来自自我激励,不得而知,但是他的成功却可能大多来自外部爱情的激励,这一点我在《薛定谔的爱情》中强调过。有人试图用马斯洛的需求层次理论来解释薛定谔现象:“人类的需求是一个金字塔,从底部到顶部,依次是生理、安全、社交、尊重、自我实现这五个需求。人们需要满足金字塔底层的需求后,才有条件满足更高层次的需求”,但这个努力似乎是不成功的:薛定谔的奇数层是同时满足的,你品,你细品;而千千万万的人在同样的爱情的外部激励下,却都没有发现薛定谔方程,或者其他什么方程。
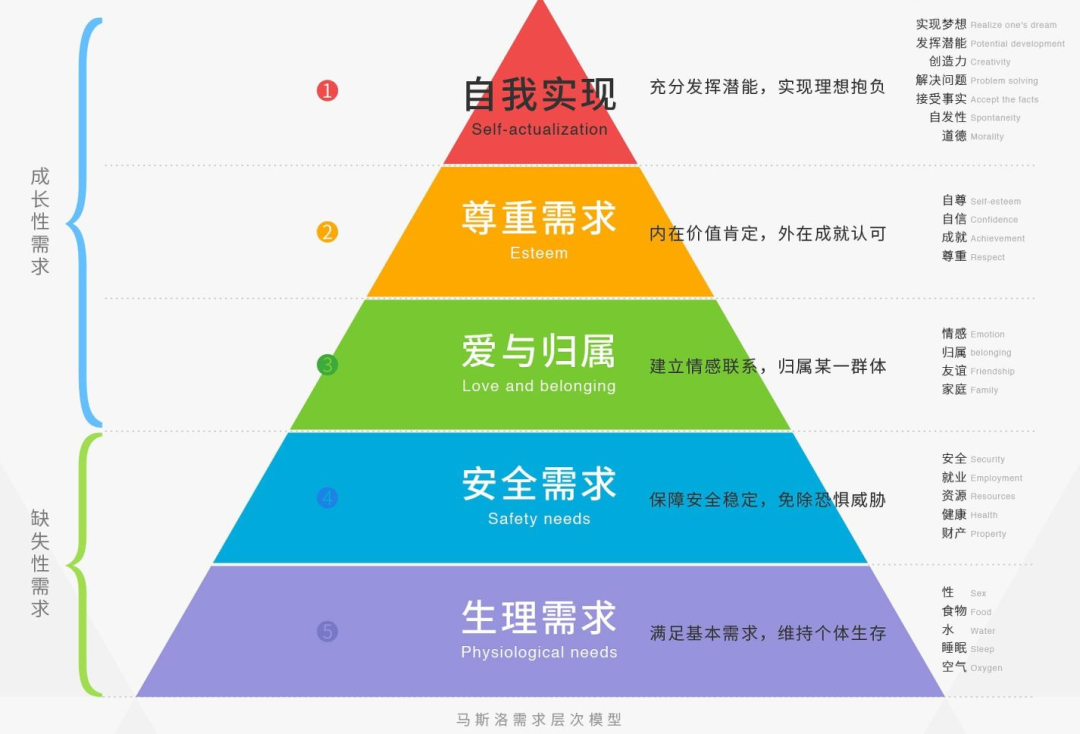
但这不是马斯洛的错,薛定谔毕竟是不确定性的代言人,海森伯也说世界本来就是测不准的。马斯洛的需求金字塔,实实在在为早期的激励理论(Incentivetheory)打下了坚实的基础。激励理论最重要的流派,行为主义心理学创始人华生(John BroadusWatson)认为:“通过激励手段,诱发人的行为。在‘刺激—反应’理论的指导下,激励者的任务就是去选择一套适当的刺激,即激励手段,以引起被激励者相应的反应标准和定型的活动”。新行为主义者斯金纳强调“人们的行为不仅取决于刺激的感知,也决定于行为的结果。当行为的结果有利于个人时,这种行为就会重复出现而起着强化激励作用。如果行为的结果对个人不利,这一行为就会削弱或消失。所以在训练(Training)中运用肯定、表扬、奖赏或否定、批评、惩罚等强化手段,可以对学习者的行为进行定向控制或改变,以引导到预期的最佳状态。”
行为主义大道
而这有意或无意的成了强化学习/深度强化学习的理论基础。作为机器学习/深度学习浪潮后,人工智能领域最被广泛看好的后浪,强化学习与深度强化学习被业界寄(da)予(si)厚(chui)望(peng),成为通往通用人工智能(AGI)大门的金钥匙。DeepMind 星际2 AI 对人类玩家的暴击, OpenAI 15亿参数的GPT-2超人语言模型,2019年深度强化学习的成功,激励了人工智能领域的后浪们,沿着华生的行为主义康庄大道,前赴后继。
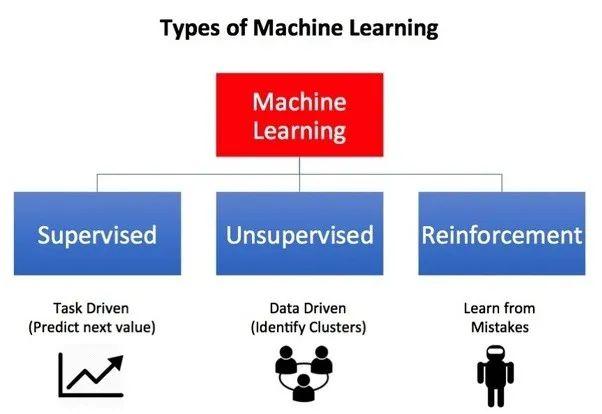
强化学习作为机器学习的一个分支,有别于经典的有监督学习、无监督学习,其最大的特点就是在交互中学习(Learningfrom Interaction)。通过让软件定义的智能体(Agent)与环境(Environment)交互来训练模型。当智能体的行为(Action)产生期望的结果时,智能体将获得激励(Reward),也就是环境给它这个行为正面或者负面的反馈,促其成长到新的状态(State),这一行为也将被强化,塑造智能体在此环境下,后续的良好行为。这一交互过程持续迭代,智能体在奖励或惩罚中不断的“学习知识”,“积累经验”,从而更加适应环境。业界认为这一学习的范式非常类似于人类求知的过程,因而也就对其实现通用人工智能充满期待。
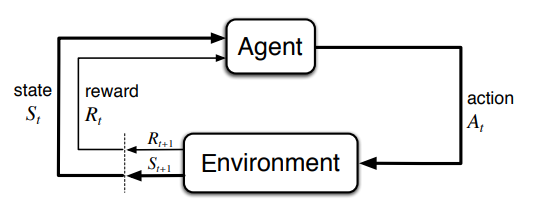
未来不迎MDP
智能体不能随意改变的任何东西都可以被认为是环境的一部分,行为可以是我们想让智能体学习的任何决策,状态则是可以帮助智能体进行行为选择的任何事。同时,也不假定环境中的一切对智能体而言都是未知的,例如激励规则是环境的一部分,但是智能体可以了解其算法,甚至智能体完全可以对环境此刻的奖惩机制了然于“心”。
想象一下自己是C罗,在踢一场足球联赛,你就是球场上那个懵懂的智能体(Agent),球场、裁判、队友与对手都是其所处环境(Environment)的一部分。现在你要决定脚下这个球怎么踢(Action),传球给队友中的哪一位?还是自己拔脚怒射?还是传给对手(假定是某大国风范男足)?你头脑里极其清楚,球踢到对方球门里,就能得一分(Reward),而踢到自家球门里,对方就得一分。你脑海过电影式的闪现刚才发生的一幕幕(Historical States ),形势紧迫,你快速环顾了一下全场状态(State),判断了一下传给队友与射门成功的各种可能性(Policy),最后起脚射门,打在横梁,吓得对方守门员一身冷汗,队友冲过来“拍了拍”你,以资鼓励。至此,你完成了一次攻防(Episode)。

踢球正如下棋,最好能多看几步,下棋落子无悔,踢球却更复杂,即便多看了几步,事情也不一定按照你设想的方向发展。万一遇到猪队友呢,万一自己就是猪队友呢,由于体力不支,本打算打门的球,妥妥地传给了对方后卫呢。场上形势瞬息万变,让人一筹莫展。这时候你忆起了强化学习的心法:MP -> MRP -> MDP,灵明无着,物来顺应,未来不迎,当时不杂,既过不恋。
既过不恋MP,马尔可夫过程,无记忆的随机过程,也就是,一个具备马尔可夫性质的随机状态序列S1,S2, …,可定义为<S,P>,S是有限状态的集合,P是状态到状态的转移概率;=> 当时不杂MRP,马尔可夫激励过程,一个懂得价值(Value)的马尔可夫过程,可以表示为<S,P, R, r>, R是激励函数,R是t状态到t+1状态的激励的数学期望,r是激励的价值贴现率;=> 未来不迎MDP, 马尔可夫决策过程,是马尔可夫激励过程参与某种决策,它处于一个环境(Environment),其中的状态都是马尔可夫状态,<S,P,R,r,A>, A是有限的行为的集合。

拜天资聪颖,悟性极高,加之勤于温习心法,你很快参透其中奥妙,下棋、星际Dota无往不胜。然而,球还是踢不好,中秋节拜早年也无济于事,留给球队的时间总是不多了。找不到队形站位,难以贯彻战术安排;反复演练的配合,场上无用武之地;小范围成功传切,难挡对方帽子戏法;苦于达成默契,技战术明显不稳。。。艰苦卓绝的训练了10000小时,仍差世界顶尖几条长安街。
马尔可夫困境
上帝说“这世界太黑了,要有光”,于是牛顿出现了。牛顿如此成功,他的定律为人们描述了一个确定性的世界,万物都按照确定的简洁的规律运行,如同精心设计的机械钟表。大数学家拉普拉斯甚至推导出了心中的智者。直到马尔可夫建立了自己的随机过程:“当一个随机过程在给定当前状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定当前状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。”
矫枉必须过正,或者必然过正。马尔可夫过程随即在物理、化学,生物、遗传,信息、互联网,经济、社会广泛应用,从彼时机械决定论的挑战者,如今几近变成放之四海而皆准的真理,大多时候人们会不假思索的做出马尔可夫性质的假设,从而进一步享受(enjoy)马尔可夫过程带来建模与推演的便利。我们可敬的学长,“概率学界学术教父”,钟开莱先生在他的《Green, Brown, and Probability》书中如此评价:"The Markov property means that the past has no after-effect on thefuture whenthe present is known; but beware,big mistakes have been made through misunderstanding the exact meaning of thewords 'when the present is known'."笔者斗胆译为:“马尔可夫性质意味着过去对于未来没有后效,当现在已知的时候;但请知悉,因对 '当现在已知的时候' 这个表述的确切含义的误解,已经铸成了大错。”
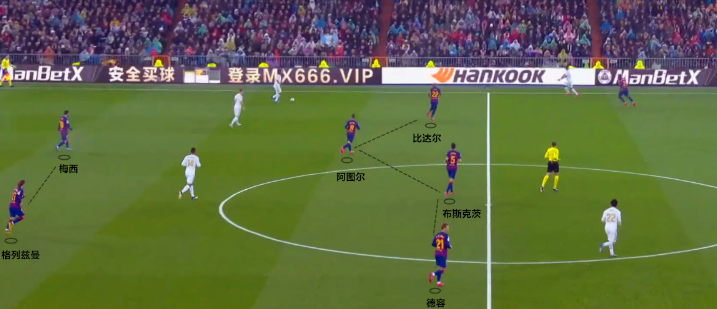
非马尔可夫是规则,马尔可夫是例外。这句话就可以解释为什么强化学习目前只擅长玩游戏,足球总是踢不好。因为电子游戏往往没有after-effect“后遗症”, 而现实世界中后遗症比比皆是。一块石头从陡坡上滑下,不具备马尔可夫性质;你在泳池奋力游回岸边,无奈呛了水,不是马尔可夫过程;冒名顶替,几十年相安无事,不代表未来不会身陷囹圄,不是不报,时候未到。教练的指导与战术部署贯穿全场,球场上形势瞬息万变,捕获每个时刻的全部状态(State)信息几乎是天方夜谭,马尔可夫性质也就无从谈起。
眼镜蛇效应
或许很幸运,你的强化学习问题恰好具备马尔可夫性质,可以放心大胆建模成马尔可夫过程。而且更幸运的是,这个问题跟金融折现一般直观,所以选择折现率 r 毫不费力,然后你开始构建价值函数(Value function),以期后续用BellmanEquation推算激励期望。是构建状态价值State Value函数,还是行为价值 Action Value函数呢?正如牛顿的小石块从有摩擦力的陡坡滑下,是看势能还是看动能?你的终极目标是打怪升级,可是这些终极目标如何拆解到短期的每一步呢?是否存在到达终极目标的完美路径呢?你陷入深度思考。
人类一思考,上帝就发笑。上帝知道此刻你用的是唯二的脑皮层回路,不是杏仁核的情绪反馈。脑皮层会三思而后行。强化学习究竟在激励什么?怎样给出合适的激励呢?如何定义这个智能体当前的需求呢?朝哪个维度激励呢?激励到什么程度呢?如何避免走一步看一步,得过且过呢?遇到斯坦福教授“棉花糖”实验中那些选择延迟满足的“熊孩子”怎么办?你推崇的以退为进,声东击西,围魏救赵的策略呢?你在训练的是个大脑还是杏仁核?

殖民时期印度,英政府想减少有毒眼镜蛇的数量,颁布法令奖励打死眼镜蛇。而印度人为赏金反而开始养殖眼镜蛇。英国政府意识到这个情况取消赏金后,养蛇人把毒蛇都放了继而导致毒蛇大量繁殖。People always game thesystem,人们总会与机制博弈。缜密设计的科举,遗憾同样无法完全规避冒名顶替,这里至少有242个坑爹的故事。谷歌科学家Alex举过一个例子讲他的模型如何作弊的:“有一个任务需要把红色的乐高积木放到蓝色的乐高积木上面,奖励函数的值基于红色乐高积木底部的高度而定,结果一个模型直接把红色乐高积木翻了一个底朝天”。所以,在编写激励函数时,请记住:你得到的是你所激励的,而不是你想要的。我可以理解此刻你茫然了,乐高尚且如此,更不用提足球比赛了。
智能体博弈
然而,这个世界有人的地方就有恩怨,有恩怨就有江湖,江湖的本质是对有形的或者无形的,客观的或者主观的,合理的或者疯狂的,当下的或者未来的,所有稀缺资源的配置与优化。有智能体的地方也不例外。下棋打游戏的巨大成功之后,足球比赛或许是深度强化学习,在具备实用价值之前,不得不闯荡的江湖。“闯荡”是信息交流,是竞争博弈,是协同合作,是成长成功,是波浪式前进,螺旋式上升。
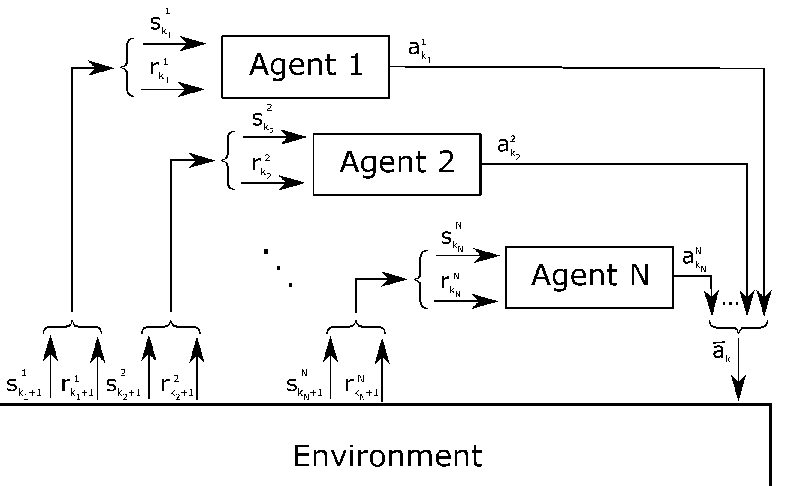
跟单智能体的强化学习类似,多智能体强化学习(MARL)引入智能体(>=2个),这些智能体通过动态地与其所在的环境交互来学习知识和经验。与单智能体强化学习不同的是,MARL场景中,多个智能体构成了江湖,他们彼此以及与环境(Environment)之间交流,合作,竞争,博弈。环境稳定的情况下,博弈结果趋向于纳什均衡,这一状态(State)是:只要其他智能体不改变自己的策略(Policy),没有任何一个智能体可以通过改变策略获得更多的收益(Reward),这时的策略也就是混合了多个智能体的群体策略。科学家说任何静态的博弈至少有一个纳什均衡状态,因而MARL都尽力收敛到纳什均衡。
可以想见,MARL体系的复杂性随着环境中智能体的数量增加而指数级的增长,很快就会触及维度灾难。如何为数量庞大的智能体确立学习目标,设定激励机制,促进群体共同学习;如何调整每一个智能体的变动的学习目标,调整其最优策略随着其他智能体的策略的改变而改变;如何在持续变更的环境中,描述长时间尺度的激励,以便智能体产生延迟满足,或者以退为进的协同策略,目前看都是世界级难题。天才请火速入坑。
强化内外兼修
《谁建造了马斯洛的金字塔?》总结到:“虽然后续大量的实证研究都无法证明马斯洛需求层次理论,但是管理学的研究人员依然不愿意放弃它”,“其中一个重要的原因就是管理学在引用心理学、经济学理论时,往往会曲解原意,以迎合自由市场、企业层级框架、公司管理等领域的需求”。而作为肩负人工智能后浪重任的深度强化学习,绕不开门卫的灵魂三问:你是谁,从哪里来,到哪里去。人们重仓深度强化学习,其中饱含对这一实现通用人工智能的潜力股的厚重期待,期待人工智能业界,遵照客观规律,潜心攻克这些世界级难题,而不是制造AI轰动效应,迎合社会与产业的公关炒作,这样吊足胃口,空耗社会热情,极易跌入新的寒冬。
面对有限理性的人们,把他们的行为简单地看成神经系统对客观环境激励的反应,忽视了人的内在因素,诸如需要、兴趣、意识、观念、思想与价值判断等等,不符合心理活动的客观规律。人的行为是外部环境和内部意识相互作用的结果,两者结合才能达到调整行为的目的。基于机械行为主义的深度强化学习,需要加强探索设计智能体本身的需求,结合《赫胥黎焦虑》中探讨的进化策略(EvolutionStrategy)与适应度函数设计短期长期结合的激励机制,彻底研究强化学习要解决的问题本身,审慎判读是否适用马尔可夫假设从而合理建模,该博弈的博弈,能均衡的均衡。
我们的深度强化学习还是爱因斯坦的第一个小板凳,激励机制的合理性与确定性仍不如薛定谔的猫,马尔可夫的随机过程天生无法建模量子的世界,多智能体也还在在探寻纳什心目中的均衡解,而行为主义也正趋向内外兼修。
参考文献:
https://www.davidsilver.uk/wp-content/uploads/2020/03/MDP.pdf
http://www.jtoy.net/blog/deep-reinforcement-learning-is-a-waste-of-time.html
https://www.alexirpan.com/2018/02/14/rl-hard.html
http://www.sbfisica.org.br/bjp/files/v28_90.pdf
https://towardsdatascience.com/introduction-to-reinforcement-learning-markov-decision-process-44c533ebf8da
https://wiki.mbalib.com/wiki/%E6%BF%80%E5%8A%B1%E7%90%86%E8%AE%BA

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国